这个吗?(完整数据14天免费试用,但需要visa卡)


就是这个索引,抱歉我之前以为这个是部件的索引。
不是人人有Visa卡。有Visa卡的人爱惜自己的卡号。 ![]()
这个版的价值在于:有时怀疑旧版的某个词有错误时,可以做一道算术题,进去检索一下新版,看新版怎么说。
我个人觉得:连搞到完整的词头都有困难,别说内文数据了。
假如能收齐完整的词头索引数据,即使单用旧版的图像版也够了。
尝试爬了,挺好爬的,没有任何加密,但是爬太快出验证了,现在点几下就让我跳转验证一次,不知道什么时候可以继续。总共52本词典,codes.txt.zip (1.2 KB)
要是用的 cloudfare 在 github 上有库
要是自建的算术题,需要训练 OCR,成功率感人。
大概是日限量多少?
- 频率一秒一次的话,一天 86400
- 10 秒一次的话,一天 8640,再慢就得逆向找漏洞、分布式IP、OCR
0.2秒/次,验证是自建的算术题,我感觉还是太快的原因,慢点可能就没有验证了。
不如先试试注册一个完成订阅的账号再爬,在14天试用期内可能没验证
请问JSESSIONID是怎样解决的?
不需要Visa,贝宝也可以,已经是试用账号了,要是没试用爬100条就没了,让你先试用。
JSESSIONID大概4种级别,未注册,已注册,已试用,已付费。前两个级别没法爬,未注册大概爬10条就结束了,已注册可能100条,已试用才开始爬没感觉到有查询次数的限制,最开始间隔设的2秒没有出问题,后来感觉太慢了改成0.2秒就跳验证了,已付费可能限制又更少。
付费多少钱?看看能不能众筹?
€ 15.00 / 月
我出一个月,慢慢抓
时间太久,不太想搞。
爬取脚本在这里,使用说明也写在 readme.md 文件里了,需要是付费的用户。所有词典的索引和词条都可以爬取,是通用的脚本。
hanyucidian.org.zip (15.4 KB)
唉,我能注册我就注册了
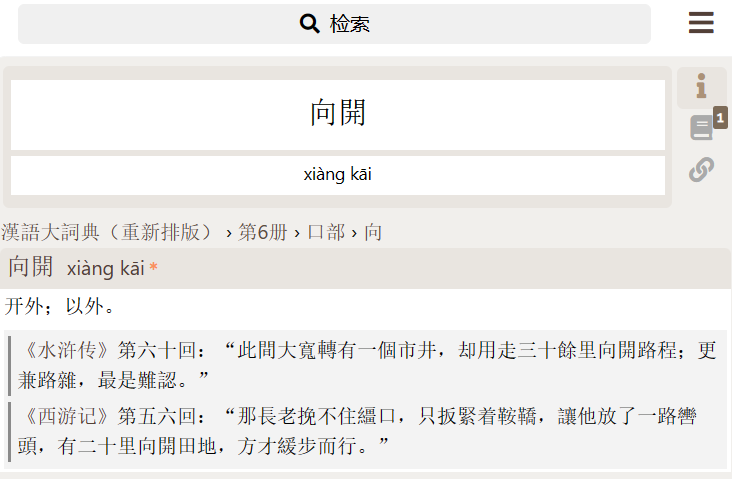
这一条是《订补》。看来正式收入了第2版。
<新增条目>
〖向開〗
开外;以外。《水浒传》第六十回:“此間大寬轉有一個市井,却用走三十餘里向開路程;更兼路雜,最是難認。”《西游记》第五六回:“那長老挽不住繮口,只扳緊着鞍鞽,讓他放了一路轡頭,有二十里向開田地,方才緩步而行。”
假如能得到所有词头,就可以用程式和旧版比较,看增加了什么新词。
想抓整本词典不切实际,时间成本太高。
比较实际的做法是得到所有词头,通过比较找出旧版没有的新词,然后收集新词条。
词头也很难获取,这个网站的索引是每页 45 个词头,30 万词头就要查询 6600 多次。
那么,也许只能这样做:
1.拿图像版的词头和文字版词头比较,找出图像版有而文字版缺的字、词。
2.找出图像版也缺的字词。
两者相加,得出一个待补字词表。
能把这个字词表中的词条补齐,就不错了。
假如只补单字,应该不会太多,就几千个吧。
2秒一次,一天86400,43200次,30万,需要运行8天。
二分法可以试1s,0.5s,4天左右,这个时间我等闲人是有的。
瓶颈在没有付费用户ID。
paypal 以前用过,有几次乱扣钱,虽然能找回,我直接就给关闭了。 ![]() 玩不来。
玩不来。