八千多个词条,包含图片、文字和视频。很难提取吧?![]()
见百度网盘 (更新:8.18)
8.18: 删除索引“ALL”,添加三本词典【体育专业手语(老版)、理科专业手语(老版)、中国手语老版本】
8.14: 处理错误的词条,添加索引“ALL”

密码: FREE
八千多个词条,包含图片、文字和视频。很难提取吧?![]()
见百度网盘 (更新:8.18)
8.18: 删除索引“ALL”,添加三本词典【体育专业手语(老版)、理科专业手语(老版)、中国手语老版本】
8.14: 处理错误的词条,添加索引“ALL”
密码: FREE
看iOS版也是海笛出品的,海笛的词典数据有被提取过,论坛上有作者会,但不知道他们用的什么方法提取的,没见到有公开的。
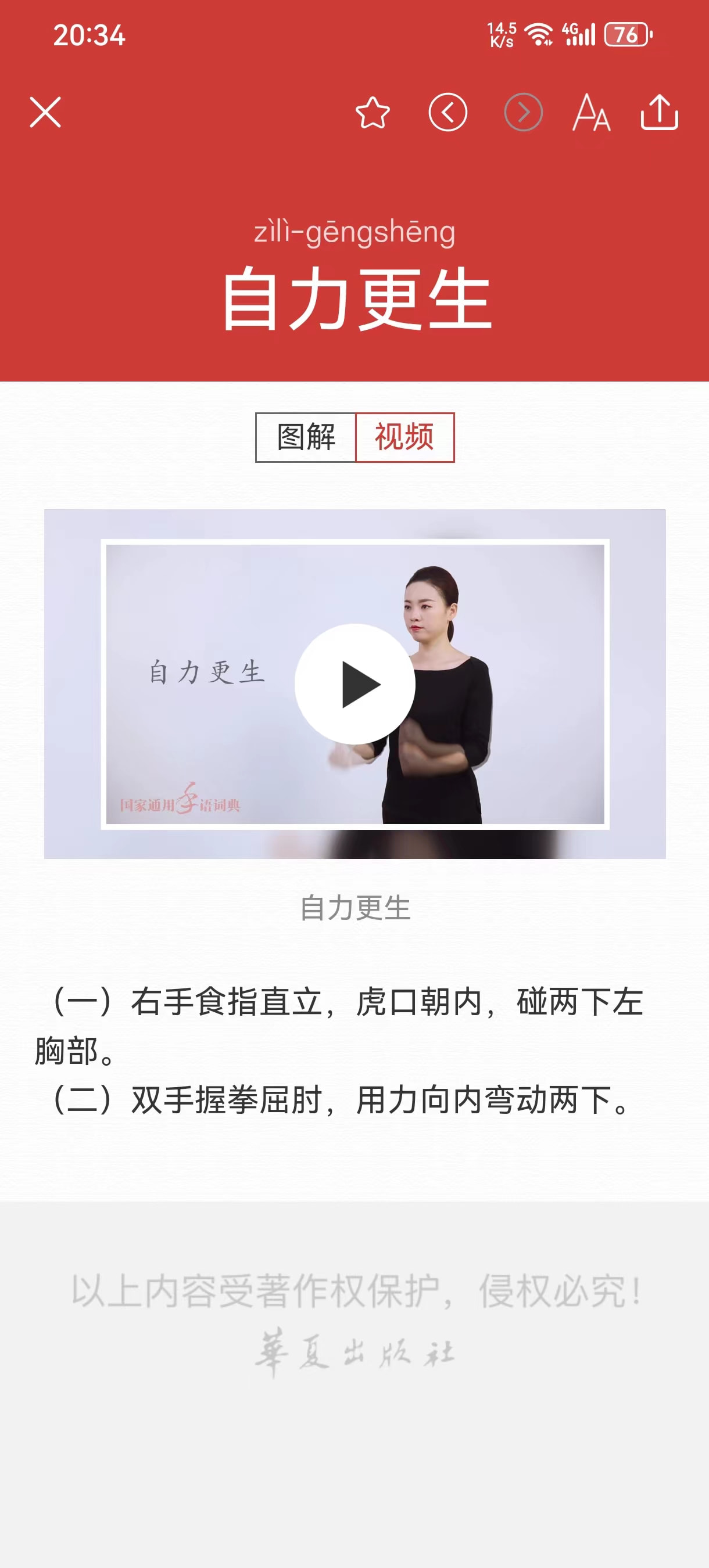
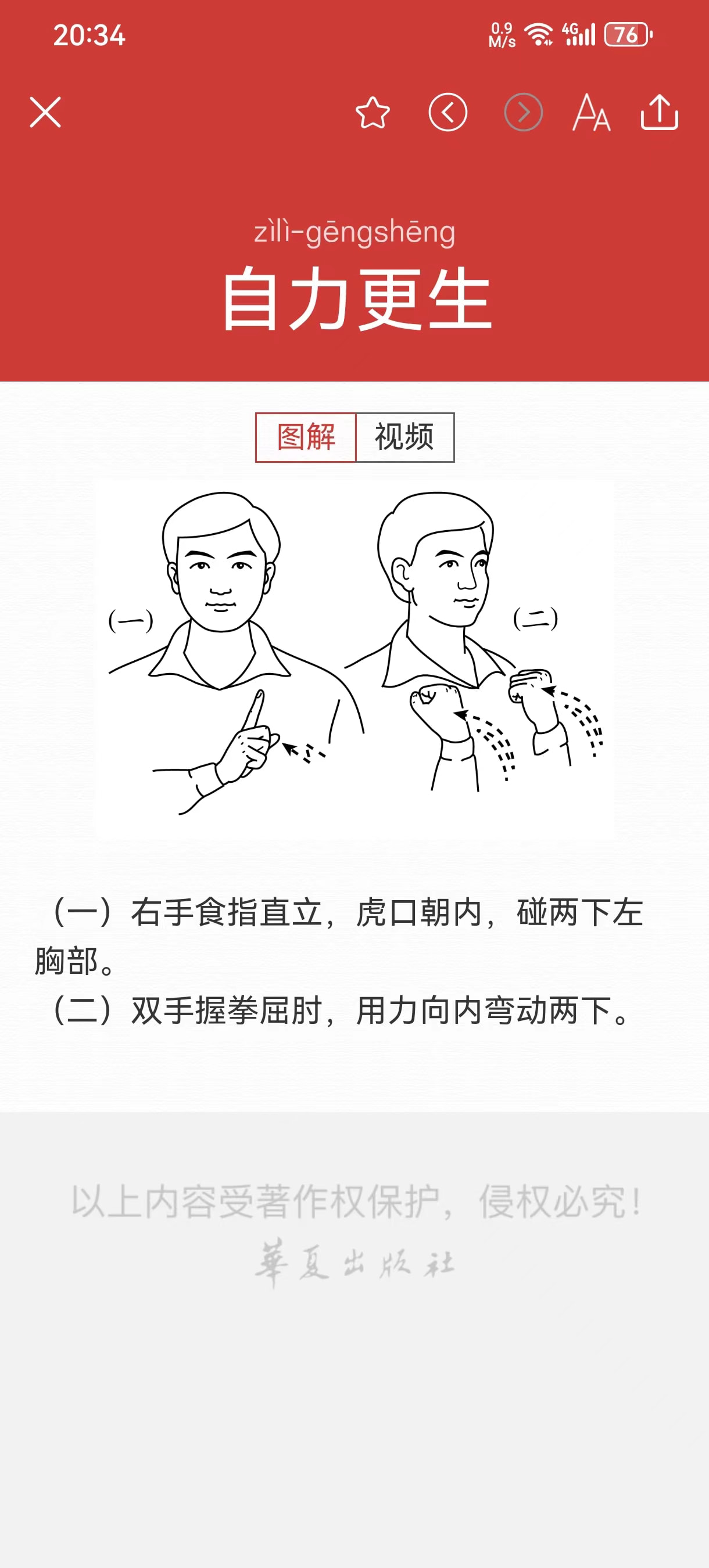
最近因为学术需求,想训练手语示意图LoRA,需要素材。抓包分析了一下国家通用手语App,发现其全部文字内容似乎是完全内嵌在App中的,但示意图和视频均是到无需cookie就能访问的公域域名获取的(可以理解为图床)。
比如「把」:
我不会搞,求指点迷津![]()
我也不太会![]() 今ㄦ个看了看它的android app,底子照着海词词典app改的,因为一堆资源文件都没删。但是App被360加壳了。我不懂安卓逆向,不知道怎么处理。
今ㄦ个看了看它的android app,底子照着海词词典app改的,因为一堆资源文件都没删。但是App被360加壳了。我不懂安卓逆向,不知道怎么处理。
所有手语图片格式我看了下ㄦ,大概是这样
http://img.haidii.com/image/41001/ 国家通用手语图床/7d1d984f/ 手语图示或者 /8b8fd305/视频浏览图/fc14753bf/ 类似形式的9位十六进制数,我猜测是根据词条id生成的某种编码。/f53fa3dad1744e86c3c46364bd3b528b.png 类似形式的32位16进制数,我猜测是根据词条id生成的md5编码。目标是爬下来所有图片、文字(视频我还没想好怎么办),现在有这么两个法子。
id生成的md5编码怎么获取的?
抓包(通过软件检测app从网上下载了什么东西)或者找存储目录都行。
今ㄦ个已经得到了几乎所有手语图(共6706张),理论上还差一张(app收录了8214个义项,有多音字、同音词什么的,但只有6707个词条),似乎是下漏了。我训练手语图LoRA的数据要求已经达到了。这段时间比较忙,就看之后谁能提取字典的文字数据和视频了。提取好了就能做电子词典了()
大佬厉害,可惜了我不会抓取安卓里的数据![]()
Anna下不了,有谁帮忙下载?
搜了搜,原来还有官方网站,也许可以买一些做成pdf: 国家通用手语系列 (readoor.cn)
处理图片分割反爬可以学习: 逆向世界某读切块图片链接与Python还原切割图片 - 『脱壳破解区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
“抱歉,本帖要求阅读权限高于 10 才能浏览” ![]()
逆向世界某读切块图片链接与Python还原切割图片.pdf (6.7 MB)
只是思路,不是同一个网站,需要自己触类旁通。
安娜我也下不动,很折磨。建议捐赠一下吧。
总共四册,这只是其中一册。
谢谢,还差三册![]()
在做mdx,请勿重复劳动力……
见百度网盘 (更新:8.14)
处理错误的词条,添加索引“ALL”
https://pan.baidu.com/s/1FvVmzM86PJNQsEInTysqlw
密码见1楼
词条处理太麻烦了,花了一天一夜搞定 ![]()
欢迎反馈,谢谢![]()
还有几本要不要也做了?我花了几个小时反复从安娜上下载下来的 ![]() 。
。
提取码:FREE


