是不是需要将mdx转为txt,然后用python来处理?对于我来说太复杂了,有什么好的办法呢?
举个例子
aaa
@@@LINK=bbb
</>
ccc
你好
</>
ddd
@@@LINK=ccc
</>
bbb不存在,需要删除以下部分。
aaa
@@@LINK=bbb
</>
是不是需要将mdx转为txt,然后用python来处理?对于我来说太复杂了,有什么好的办法呢?
举个例子
aaa
@@@LINK=bbb
</>
ccc
你好
</>
ddd
@@@LINK=ccc
</>
bbb不存在,需要删除以下部分。
aaa
@@@LINK=bbb
</>
如果已经有空词条表,可以用em批量替换
怎么做的?小白不懂![]()
参看这个。你需要增加的操作是,先把 含有 @@@LINK= 提取出来,整理成两栏。照此操作,没有提取到的就是那些空词头。
我用的是苹果电脑有办法弄到吗?
苹果?不懂。请忽略上面的回复。
设想了一种方法,供参考。
首先将词条转成单行,排序后分离主词条和跳转词条。
苹果系统应该有支持正则的文本编辑器吧。
排序可以复制到表格软件中(excel?)。
aaa @@@LINK=bbb
ccc 你好
ddd @@@LINK=ccc
↓↓↓
aaa @@@LINK=bbb
ddd @@@LINK=ccc
ccc 你好
跳转词条中的主词头前加上制表符,并把主词头放到第一列。
主词条加上第三列“@”(为了后面排序),合并主副词条。
(文本编辑器与表格软件交替使用)
aaa @@@LINK= bbb
ddd @@@LINK= ccc
↓↓↓
bbb aaa @@@LINK=
ccc ddd @@@LINK=
ccc 你好 @
复制到表格软件中排序,如图:
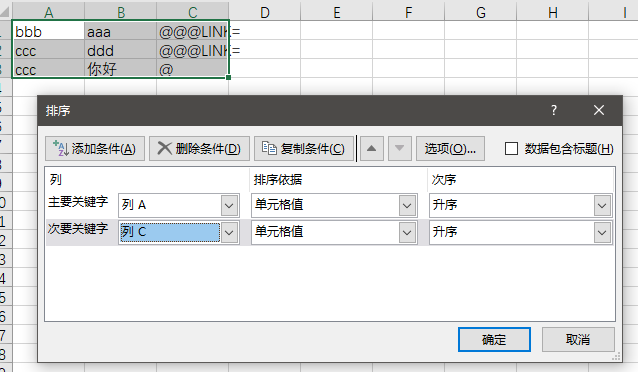
在第一行插入空行,便于后面使用。
输入公式,D2=IF(A2=A1,“2”,“1”)
复制D2到需要的单元格。
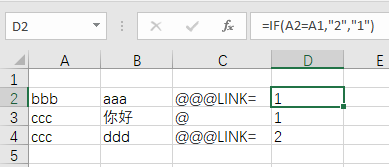
可以看到,跳转词条的 D 列是“1”的都可以删除了。
接下来就是上面的步骤逆操作一下,使文本符合mdx文本格式即可。