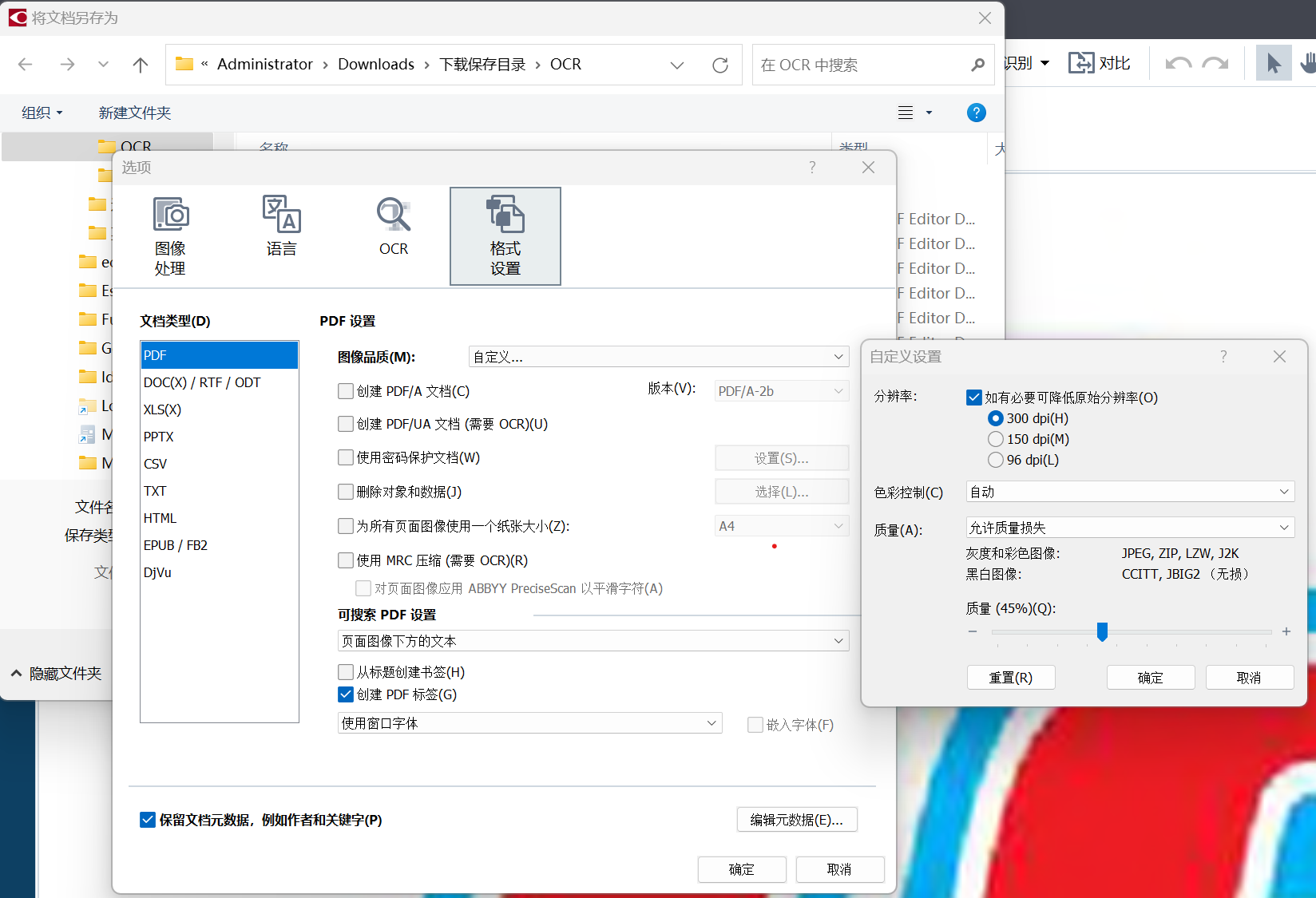
在通过扫描版PDF制作可搜索PDF文档的时候,见截图:
使用MRC压缩,分辨率,色彩控制,质量 等多处设置项,无论如何设置它们,貌似最后转换出来的PDF永远不可能做到保持原始图片,它总是要对图片进行一下图像处理,想原汁原味?对不起,不可能啊?!喔噻!
我是如何得到这个结论的?从文件的大小就可以看出来!我使用ACROBAT进行OCR的时候它没有ABBYY这么多设置,我ACROBAT中选择“将扫描的页面转换为可搜索的图像(精确)”这个选项,ACROBAT转换出来的文件比原文件只稍微膨胀不会超过10%估计只多出了文字部分的信息;但ABBYY OCR出来文件根据设置不同大小可以从30%到1500%原大小变化,任何设置都几乎看不到小于10%文件大小变化的结果。而且仔细观察原始PDF和OCR后的图片(尤其是通过极端放大细查),也可以看出来ACROBAT OCR之后图片的清晰度和细节和原始没有任何区别,但ABBYY有很大区别。
太奇怪了,如此一个大名鼎鼎的OCR软件竟然无法原汁原味?!
另一个小问题:用ACROBAT OCR出来的PDF,我用Foxit Reader打开的时候,鼠标置于空白处是手型形状此时可以任意上下拖拽文档,当将鼠标置于文字部分大约1秒后它就会自动变成字母 I 的形状此时就可以选择文本了,非常方便。但通过ABBYY OCR出来的PDF,则默认鼠标永远是手型形状,即便将鼠标放置到文字上也不会自动变成字母 I 的形状供选择文本,想要选择文本的话必须到工具栏点击“选择”按钮才可以转换,而想要再转回手型形状还是得点击工具栏手型按钮,真的不方便啊?!有什么办法让ABBYY 制作出来的OCR可以象ACROBAT那样可以自动转换手型和选择文本状态呢?!
有这两个问题我仍旧不忍放弃这个软件,因为经过对比它的OCR效果确实明显超过ACROBAT我又不好不用它!两难啊!