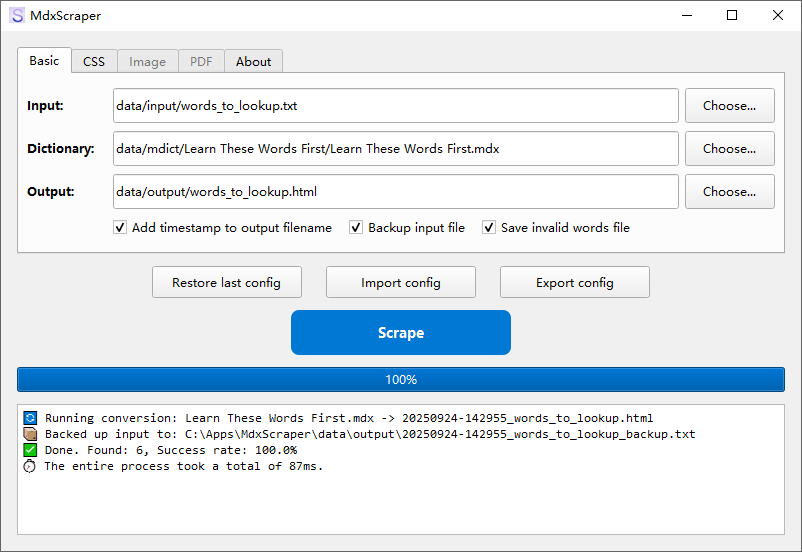
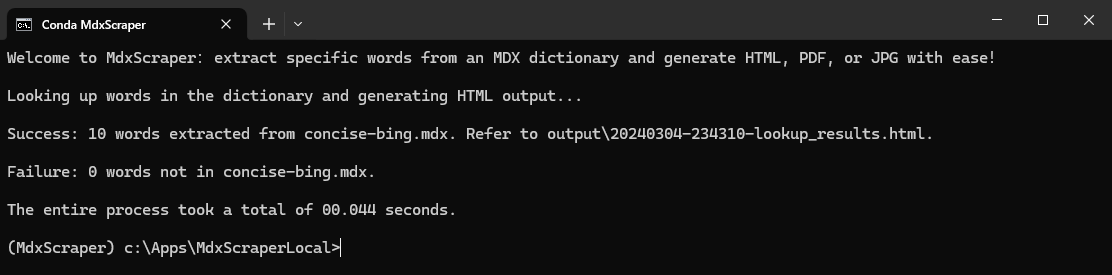
多mdd的支持,其实是在mdict-query.py文件里,需要从头理清原作者的思路。建议还是直接合并mdd更方便。
Vim
2024 年1 月 14 日 11:32
3
Update:Release MdxScraper v1.1 · VimWei/MdxScraper · GitHub
Enhancing Compatibility for Windows, Linux, and Mac.
Implement ‘utf-8’ encoding for file handling to enhance compatibility.
demo
2024 年2 月 28 日 12:18
4
正在学习 Python, 顺手把 mdict-query 改为支持多 mdd 查询了。
def multi_mdd_test():
mdx_name = '說文解字.mdx'
mdx_name = Path(mdx_name)
dictionary = mdict_query.IndexBuilder(mdx_name)
css_key = dictionary.get_mdd_keys('\C0001*.png')[0]
css = dictionary.mdd_lookup(css_key)[0]
print(css_key)
print(css)
改好的文件:mdict_query.zip (3.5 KB)
关于小白门坎高了一些,windows系统,没有exe或msi等一键安装的文件提供吗?
moran
2024 年10 月 24 日 16:23
10
请问运行了主程序出现以下报错怎么处理?谢谢!
’, ‘lxml’)
File “/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/bs4/
init .py”, line 250, in
init
raise FeatureNotFound(
bs4.FeatureNotFound: Couldn’t find a tree builder with the features you requested: lxml. Do you need to install a parser library?
moran
2024 年10 月 24 日 16:50
11
找到问题了。原来是没有装lxml,装好了运行就OK了。谢谢!
谁能本站上传个最新版的zip包, github经常响应时间过长,无法完整加载,访问!!! 谢谢!!
Traceback (most recent call last):init
楼主和大神们,报错,怎么解决呀?
Vim
2025 年9 月 21 日 23:50
14
base64不需要安装,是pythoh标准库自带的。
你的错误是,没有找到 mdx 词典,需要自己放入 mdict\
Vim
2025 年9 月 22 日 05:08
18
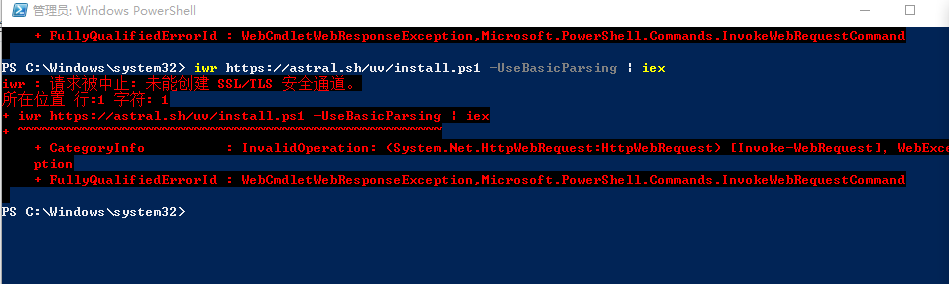
按照 uv 官方的指引:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
uv --version
uv self update
Vim
2025 年9 月 29 日 01:39
22
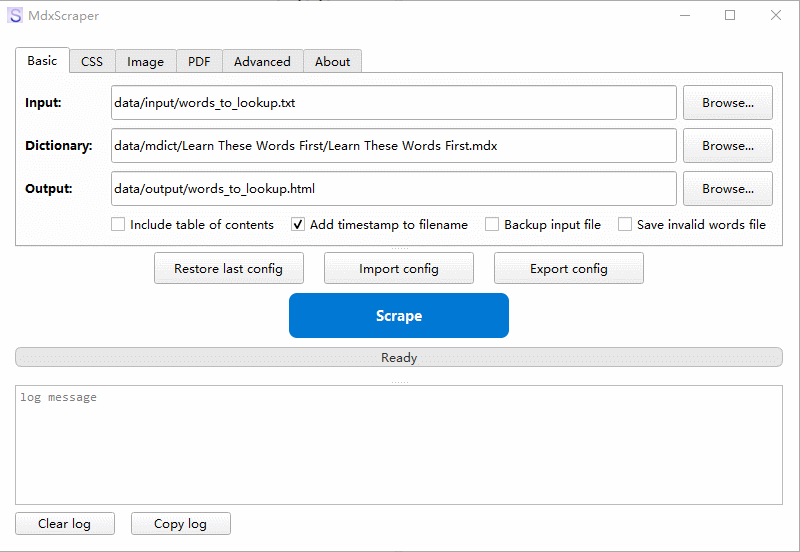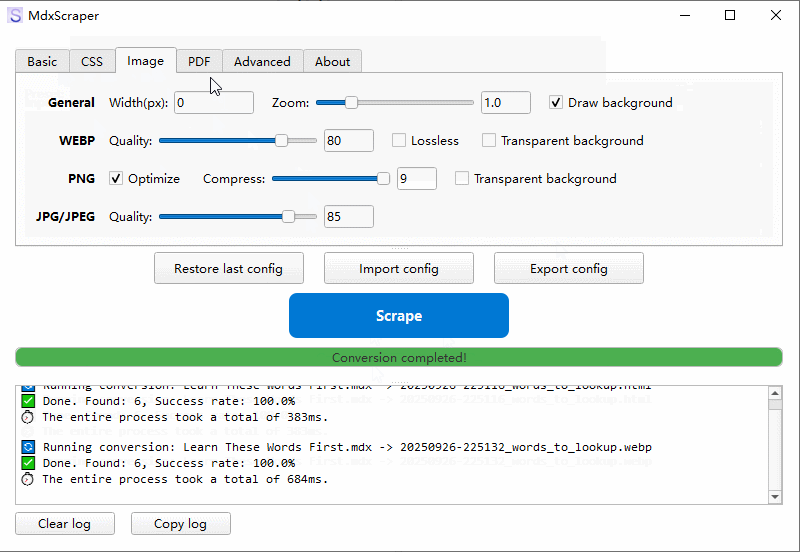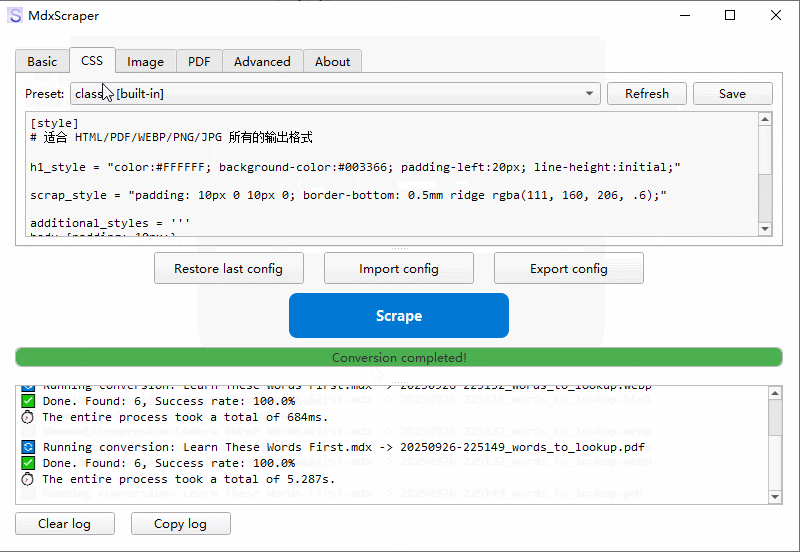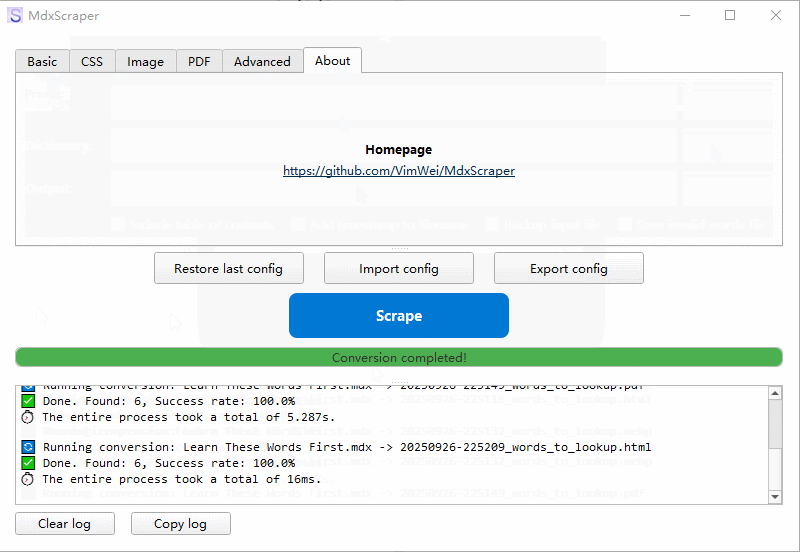
持续更新到 v5.0 了,主要是提升用户体验和程序质量。