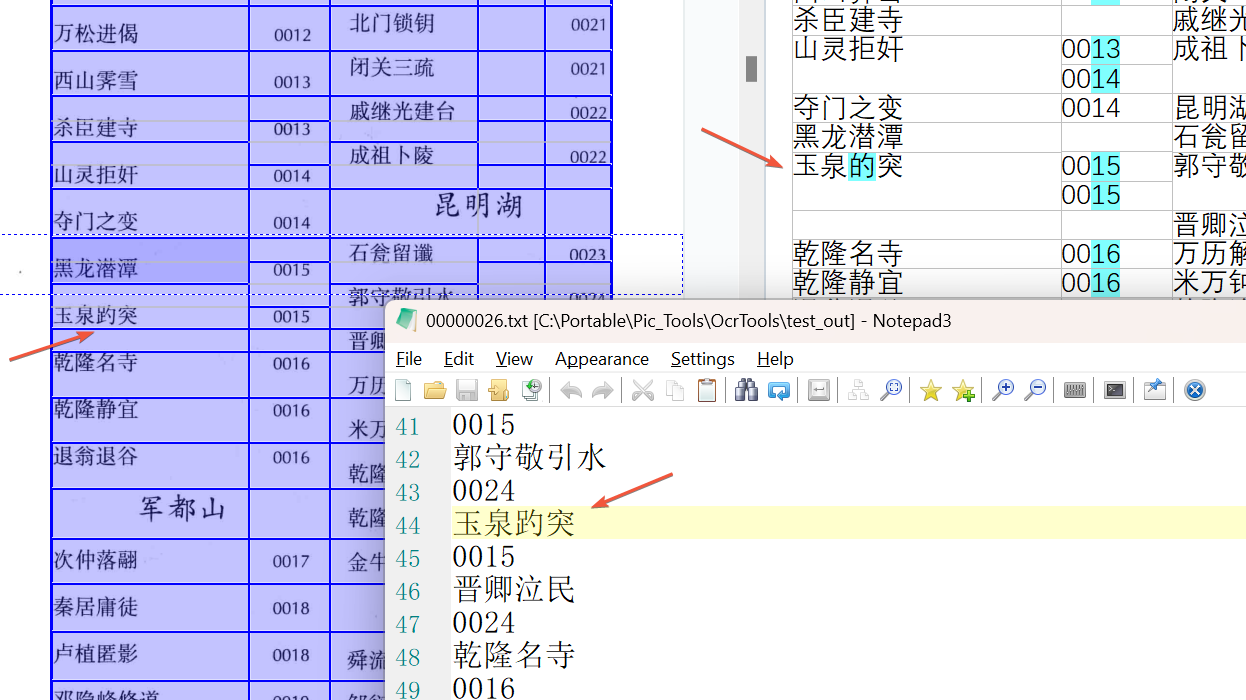
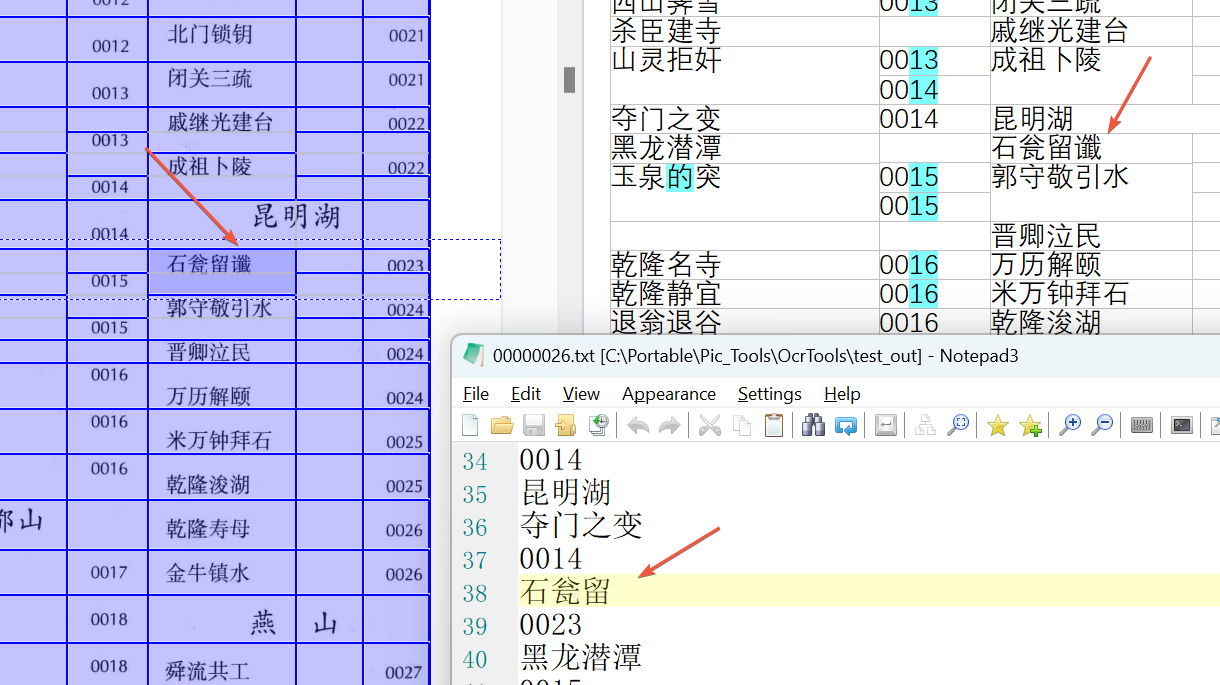
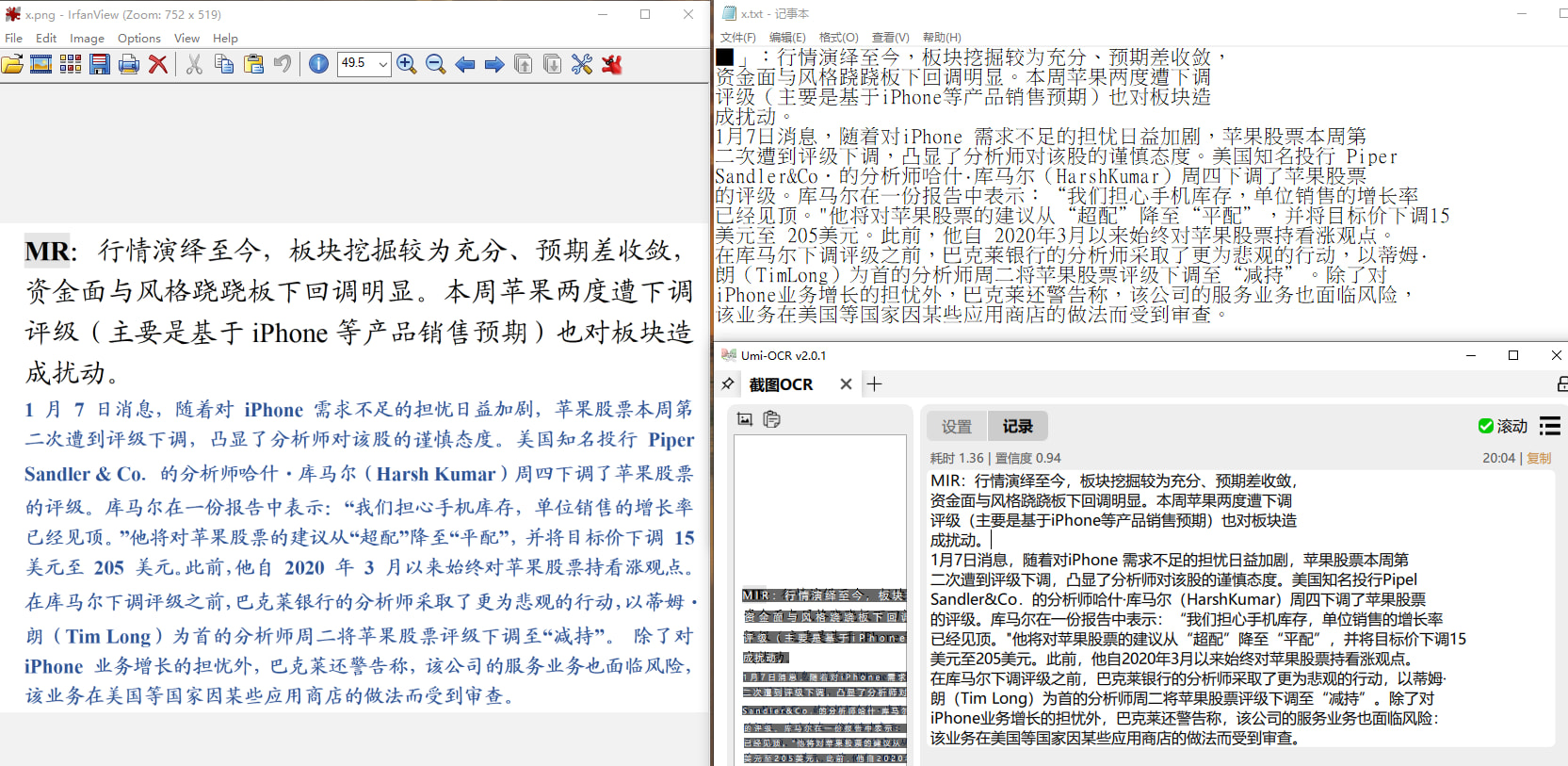
分享一个基于百度OCR与阿里OCR模型的离线OCR命令行工具,主要特色:
1、批量识别文件夹中的所有图片
2、两个OCR模型同时识别同一张图片,以方便交叉验证
3、支持JSON格式输出文本位置、文本内容、单字可信度
主要参数说明:
-m 指定识别模型
-f 需要识别的图片文件或图片文件夹路径
-o 识别结果保存文件路径,为空时如果是单文件直接输出结果,如果为文件夹则保存到图片文件夹的tmp目录中
-O 输出结果类型, 支持 txt json, 默认为 txt
单图片JSON输出使用实例:
ocr.exe -m ch_pp_ocr_server_v4_onnx -f 2.png -o t1.json -O json
输出结果实例:
{
"width": 427,
"height": 43,
"dbNetTime": 127.157, // 文本检测时间
"angleTime": 4.88721, // 文字方向检测处理时间
"detectTime": 213.825, // 文字识别时间
"image": "2.png", // 输入图片文件名
"text": [{ // 每个文字块的识别结果
"angleIndex": 0, // 文字方向分类类型
"angleScore": 1, // 文字方向可信度
"boxScore": 0.848114, // 文字检测可信度
"angleTime": 2.96191, // 文字方向分类时间
"text": "丙方(签字并按指印)", // 第一个模型识别的文字内容
"lines": [{ // 单字识别结果与可信度,每个模型一个对象
"time": 65.9409, // 文字识别时间
"chars": [{ // 每个文字对应的可信度
"score": 0.997489,
"text": "丙"
}, {
"score": 0.999176,
"text": "方"
}, {
"score": 0.97086,
"text": "("
}, {
"score": 0.999422,
"text": "签"
}, {
"score": 0.997928,
"text": "字"
}, {
"score": 0.99966,
"text": "并"
}, {
"score": 0.999627,
"text": "按"
}, {
"score": 0.999781,
"text": "指"
}, {
"score": 0.996935,
"text": "印"
}, {
"score": 0.9952,
"text": ")"
}]
}],
"boxPoint": [ // 文本位置 坐标,此处有BUG
[-4, -4],
[436, 1],
[436, 49],
[-4, 44]
]
}]
}
单图片两模型识别实例:
ocr.exe -m ch_pp_ocr_server_v4_onnx,ch_damo_document_onnx -f 2.png -o t1.json -O json
输出结果实例(结构同上):
{
"width": 427,
"height": 43,
"dbNetTime": 134.438,
"angleTime": 5.53687,
"detectTime": 298.456,
"image": "2.png",
"text": [{
"angleIndex": 0,
"angleScore": 1,
"boxScore": 0.848114,
"angleTime": 3.32397,
"text": "丙方(签字并按指印)",
"lines": [{ // 第一模型的单字识别结果
"time": 62.9211,
"chars": [{
"score": 0.997489,
"text": "丙"
}, {
"score": 0.999176,
"text": "方"
}, {
"score": 0.97086,
"text": "("
}, {
"score": 0.999422,
"text": "签"
}, {
"score": 0.997928,
"text": "字"
}, {
"score": 0.99966,
"text": "并"
}, {
"score": 0.999627,
"text": "按"
}, {
"score": 0.999781,
"text": "指"
}, {
"score": 0.996935,
"text": "印"
}, {
"score": 0.9952,
"text": ")"
}]
}, { // 第二个模型的单字识别结果
"time": 80.2739,
"chars": [{
"score": 23.8372,
"text": "丙"
}, {
"score": 26.5253,
"text": "方"
}, {
"score": 21.9118,
"text": "("
}, {
"score": 26.6864,
"text": "签"
}, {
"score": 24.6797,
"text": "字"
}, {
"score": 27.9038,
"text": "并"
}, {
"score": 27.2161,
"text": "按"
}, {
"score": 29.2181,
"text": "指"
}, {
"score": 27.8648,
"text": "印"
}, {
"score": 20.2918,
"text": ")"
}]
}],
"boxPoint": [
[-4, -4],
[436, 1],
[436, 49],
[-4, 44]
]
}]
}
批量识别文件中图片实例:
ocr.exe -m ch_pp_ocr_server_v4_onnx,ch_damo_document_onnx -f img -O json
输出结果:文件内容结构同上,此处省略
工具下载:
说明:
1、此工具为命令行版,没有好看的图形界面
2、两个模型对字母与标点符号的输出有差异
3、仅支持 Windows 系统,当前只在 windows10 x64 系统上测试过