这个个人校对难度太大了
这两天比对那个版本,发现错误很少,确实是目前最好的版本。现在主要问题是注音,我打算先对全文ocr,然后把前面有括号(不管前括号还是后括号)的词头提出来一一检查,虽然这样肯定还有不少遗漏,但也是目前最可行的方法了。
你觉得怎么样?如果有意,一起校对怎样?
2 个赞
感谢楼主的辛勤工作~
最终版没有高清的mdd了吗?
今天晚上把高清版的上传到
哦哦,十分感谢~
可以,不过人少的话,你就得做好长期的准备
嗯!我有心理准备。很多时候与其去招集人手,不如自己动手做起来。无它,爱好!
我现在先把我原来的汉大与这个版本的词头比较一遍,然后再开始语音的订正。
也许要学习如何调教tesseract。
1 个赞
感谢楼主的工作!
那个新出的汉大2.0就有好多可以校对的地方。
謝謝老兄的修改。我跟我的版本對比了一下,讓我糾正了四五個字,例如把舊體“弒”改成王力字典的“弑”。集體合作修改mdx總是最有效的。
比對之後,兩個版本之間還有250多字的差距,例如:
(字頭、頁碼、版本)
㗲 WL0136頁 MM
嚍 WL0136頁 DTLZ
嚏 WL0139頁 MM
嚔 WL0139頁 DTLZ
㘊 WL0140頁 MM
娜 WL0196頁 MM
挪 WL0196頁 DTLZ
婧 WL0201頁 DTLZ
婜 WL0203頁 DTLZ
媐 WL0203頁 MM
嶭 WL0256頁 DTLZ
𡾆 WL0256頁 MM
MM-DTLZ - Wang Li comparison.zip (1.6 KB)
標“MM”條:我版本有、該版沒收納;標“DTLZ”條:該版有,我沒收納。
標“MM”每條,我重新查了,最後保持原樣。(“MM”條,只指字典字頭,不包括我另外加的異體字跳轉。)
字單250多條,參考紙書就能校訂,但也有些特別狀況,涉及到電腦字型和Unicode標準的複雜問題,值得注意,也蠻有趣的。
王力1576頁:

該版用“”(⿵門爲)—這是私有區字,普通使用者打不出來;而且離開全宋體的環境就是亂碼了。實際上,“⿵門爲”字形已經有標準字碼:“䦱”。
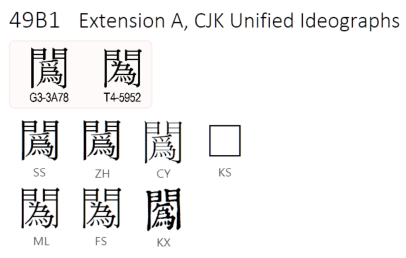
SS=Windows SimSun (Simplified Sung) 中易
ZH=Zhonghua 中華書局
CY=FZCiYuanSong 辭源
KS=KaiXinSong 開心宋
ML=Windows MingLiU (Ming Light - Unicode) 細明
FS=FSung (Full Sung) 全宋體
KX=康熙字典
上面的字型譜,說明中易字型(SS)、中華書局字型(ZH)、辭源字型(CY)都能顯出王力字典的“⿵門爲”。我建議,最好用電腦字型解決問題,盡量避開用私有區字。
王力761頁,字頭第二的字形:“⿸疒⿱罒乑”
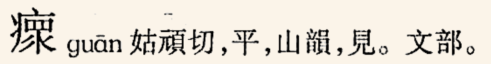
該版用相容區字:瘝 U+FAA4。在宋體顯,顯出“疒罒乑”,看來是對的,但我建議不要用這個字碼:它屬於被廢的相容區字,之所以中華書局、Windows中易、Windows細明等等字型都不提供;而且大多使用者打不出來,無法用它來查這個字頭。
再說,全宋體(FS=FSung)這個字有點問題,不符合Unicode規範字表。Unicode只提供“KP”的字形,說明這個漢字來自北韓!(KP=People’s Republic of Korea);北韓字形是“疒罒水”,跟王力字典不合。
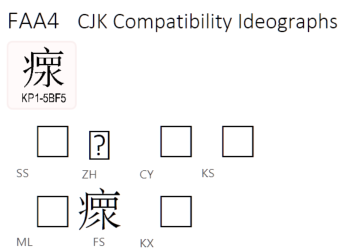
我建議用“瘝”:U+761D。若參考規範字表,會看出日本來源(“J”)和韓國來源(“K”)的字形卻是符合王力字典的字頭。雖然兩岸三地的字型,沒有一個符合王力字典的字形,但是以Unicode標準來講,這個字典字頭的標準統漢碼就是“瘝”:U+761D。

而且,U+761D 字碼也符合《漢語大字典》的字形。兩個字典能夠通用最好;字碼不該有分歧。
漢語大字典,2878頁:

(全宋體的私有區字也有“” U+F0F77 “疒罒乑”),但已經有標準字,沒必要依賴私有區字。)
mdx可以這樣寫:
瘝(標準字)
@@@LINK=WL0761
</>
瘝(被廢的相容字)
@@@LINK=瘝(標準字)
</>
瘝(全宋體私有區字)
@@@LINK=瘝(標準字)
</>
電腦字型與字典字形的關係有很多微妙、奇怪的狀況,而且Unicode本身也有錯誤,他們一直沒改因為想保持穩定,這是製作mdx群體值得注意的現象。
我上面列的字型譜,我花了一點時間作出來,大概一個禮拜能完成我要加的層次,已經收了~95,000的標準漢字碼、和mdx群體所重視的字型,另外也有70,000私有區的字碼(主要針對全宋體、開心宋的私有區)。
最近,很多人從開心宋轉到全宋體,在這個轉變中特別需要意識到每個電腦字型的特點。
2 个赞
我正在考虑咋让全宋体能在手机上使用
非常感谢楼主分享,制作字典很辛苦,谢谢
手機上怎用全宋體,這跟我上面說的重點好像沒關係…
而且這種純粹圖像mdx,沒有顯示文字的需求,使用者能輸入、搜尋到字是關鍵。(除了糾正字頭以外,我上面另外的重點就是這方面。)
我作的王力mdx,同時有圖像、有文字,就得考慮電腦字型問題 – 簡單來說,光是用一個字型是不夠的。這不是全宋體全不全的問題,而是unicode漢字碼經常有 ”一碼多形“ 的狀況,所以字典若有 ”並陳“ 多形的需求,任何一個字型就不夠用。任何字型再“全”也避不開 Unicode 這方面的基本設計。
个人认为大陆的出版物就应该使用大陆字形,台湾出版物用台湾字形
全宋体是台湾字形,不适合用于本帖的王力古汉语字典,也不适合手机
這把問題想簡單了,講大陸、台灣不如講新字體、舊字體。古代漢語字典有很多字形,以新字型為主的電腦字型無法顯示。再說 G, 擴展區的字 中華書局字型根本沒有,更早的字也沒跟上unicode 13.0。除了G以外,漢語大字典 有的字形只有全宋體能準確顯示。而且僻字的簡體字,全宋體有,大陸字型反而不見得有。
我是美國華裔,所以大陸朋友對台灣的態度就不用噴到我身上。
主要大陆的字体现在以简体为主,所以繁体字没有那么强势,台湾那边还是繁体字,虽然不想用繁体,没有办法
1 个赞
只谈词典,不谈其他
1 个赞
上文说过仅代表我个人想法
大陆字形当然有分新旧,当然有古籍上的某些字无法匹配到合适的字体,但显然也不应该直接照搬台湾字形(诸如全宋体)
其他没什么说的了。我也不想扯到别的方面
講舊、新,不如看各字、各字型的狀況, on a case by case basis。我個人覺得,若是講究字形這方面,處理mdx,尤其是超過基本字區的字典,不能全靠一個字型,必須混用。但這樣做,在CSS 和tag方面要填上更多事兒。
另一方面,因為Unicode擴展區的歷史,一般採用台灣標準的 細明 字型,有不少字形實際上來自北京中易字庫,所以說大陸、台灣,沒有很多意義。要看字嗎、字表才能具體講。Case by case.
全宋体搭配WFG的部件检索很好用,缺点是丑,手机上没法用,不过没有更好的代替品了。
免费无版权的,已经是用爱发电了。再说美丑是因人而异。
这个是操作系统的差异造成的,显示字体的机制不一样