
请选对分类。
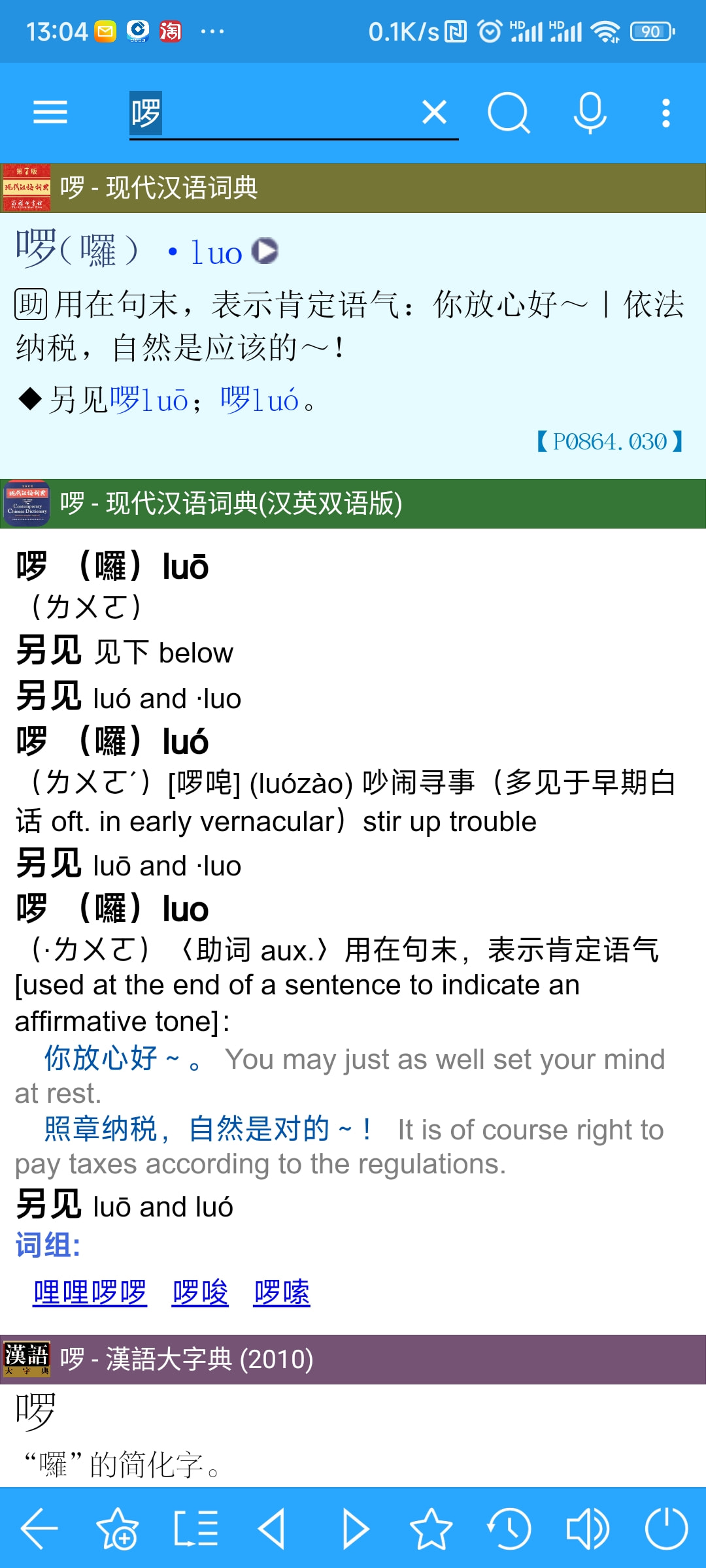
我询问的有问题的版本就是链接里的, 所以我在等@顺其自然的回复哈
多谢~~~~~
资源库版:
8mb压缩档版 62485条
解压后文本:42.2mb
无css (内部文本指向xdhybl.css)
未见作者讯息
顺其自然所提供版本:
9mb压缩档版 62059条
解压后文本:35.7mb
有css (内部文本指向xdhycd.css)
by Robot,2019-9-17
这两个版本应该同源,其中一个大概是另一个的改本。哪个比较好,单从词条数目难以判断。有兴趣的书友可以用程式比较。
词条多的也许是增订过的,打包时掉了css文件。
不要被压缩档大小骗了,得看mdx解压后文本大小。
两个大概都不全,不会给人什么意外惊喜。

我只能说:换个词典软件试试看吧。


你必须用最新版的Goldendict-Ng。旧版的Gd无法显示生僻汉字。
用的是Goldendict-Ng吗?
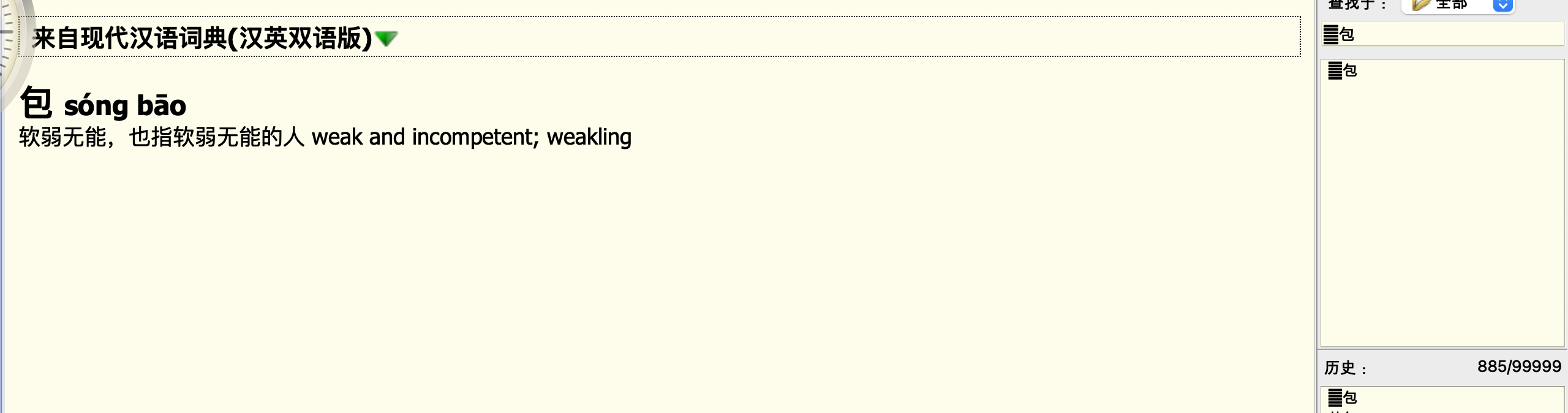
我看了一下:
包
软弱无能,也指软弱无能的人。
这是私用区字,不是标准Unicode。这个版假如要用,还得下一番功夫,把私用区字都替换成Unicode才行。
好吧,这不是换个词典软件能解决的问题,得费不少力气改造这个词典。
8mb不像是增订的,因为是2015年做的,而且没有组词功能,理论上讲9mb更好用。8mb另有作者。
我看那些生僻字不多, 都集中在那一块儿了, 可能有几十个?
9mb的版本比8mb少的词头都是私有区用字。难怪hanyl05版缺单字,自己删掉的。不过hanyl05没删包含私有区字的词语。这应该从某电子辞典提取的,原生字体肯定找不着了。
私有区用字无视就好,你打不出来搜不了的。
像𤆵这个字是扩展B区,电子辞典估计至少十几年前,那时候打不出来字只能自造了。
电子辞典搜索逻辑是用拼音搜索,对电子辞典使用者没有影响,所以从出版社拿来的数据是自造字也不用处理。
8mb版
1.Emeditor
Search – Find
在检索框内贴入: [\x{E000}-\x{F8FF}]
在“regular Expression”框内打勾。
有2685个匹配。
9mb版
只有98个匹配。
所以9mb版是个阉割版?
有人说缺少字母开头的词,这个现象也很正常,在我认知范围内,至今没有任何电子辞典(最先进的卡西欧也不行)支持英文和汉字同时输入,完全没人考虑到这个需要。
多半这是官方数据处理时剔除的,怪不得mdx制作者。
hanyl05自作主张想去除豆腐块,完全不管别的,只希望保证显示效果,留给后人残缺数据。
他是卖词典的吗?假如这样,懒得下大力气修订数据,只把产品弄得表面漂亮,能卖出去就算了,这倒是符合商人思维。