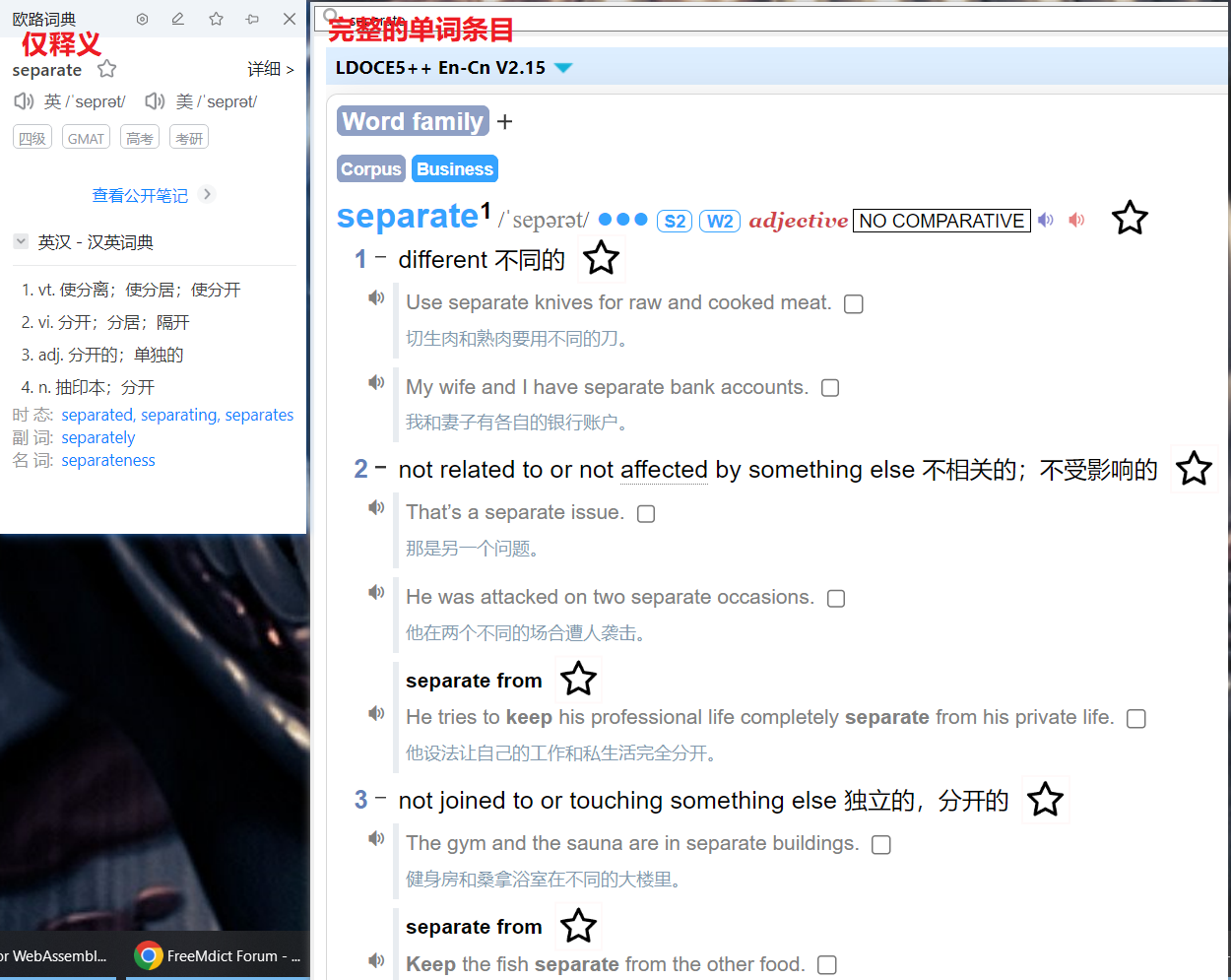
个人偏向查出完整的单词条目, 但存在一个问题, 如果这个单词释义和用法非常多, 定位到我需要的释义/用法会非常耗时, 想知道大家是如何解决或优化这个问题的
1 个赞
首先,欧路的查词和划词的词库可以分别设置和排序。划词可以把显示词典数设为1。
其次,可以在划词词库里置顶一个快查(现在坛里有朗文、牛津、韦伯等),同时,在查词词库关掉这个快查,打开对应的完整版(因为会有冲突,比如朗文)。
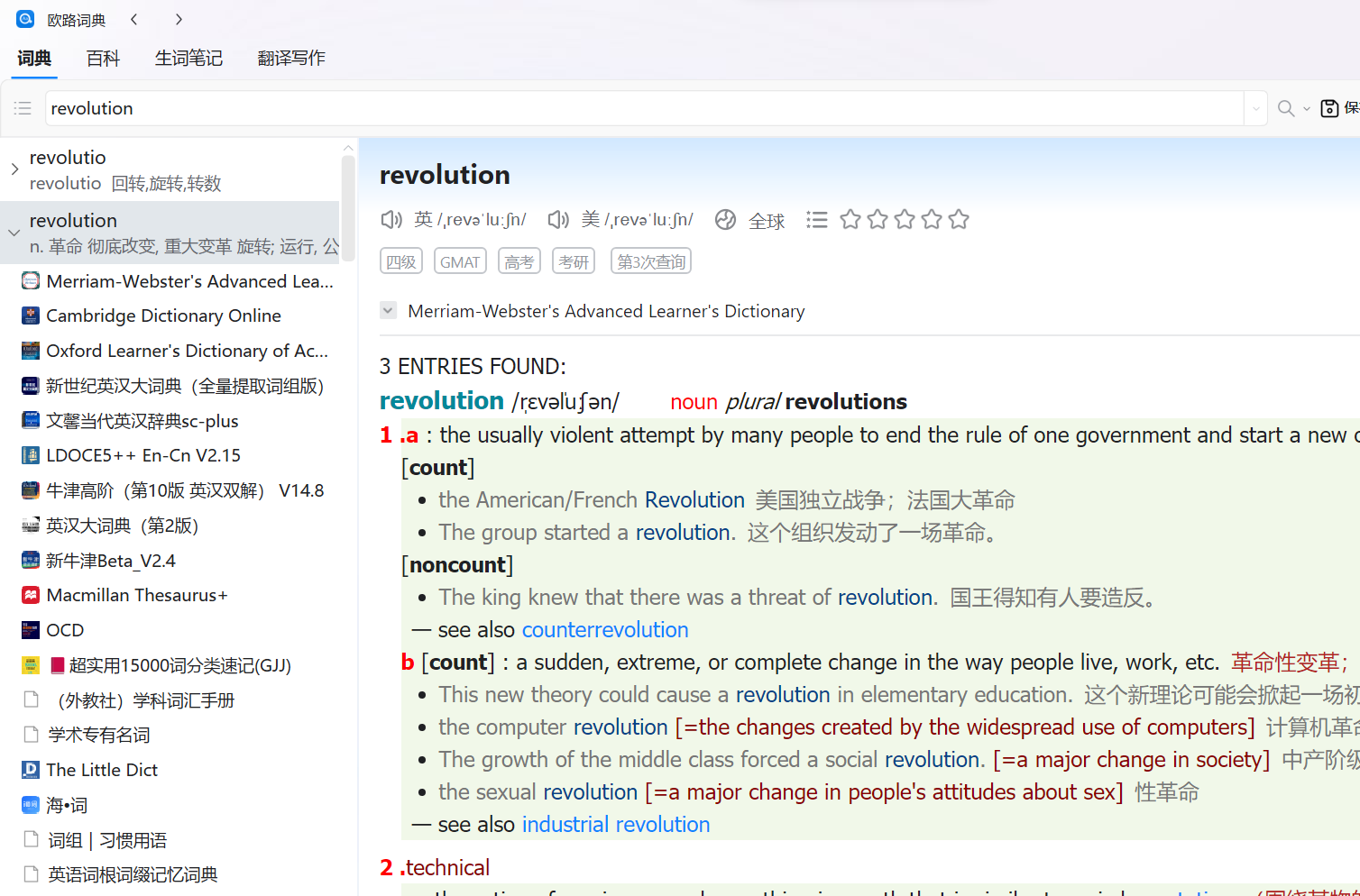
1 个赞
用坛里的ode glance
1 个赞
欧路鼠标取词词库我用TLD
1 个赞
如果是一个词词义内容特别多 而那个词义又不太好确定 这个是很难办的
1 个赞
我赞同,就大概了解一下即可。
1 个赞
之前研究过日语的划词查词优化算法,抛砖引玉分享下自己的思考,:
如果想通过写一个程序来自动缩小词典展示的条目,至少需要做到 2 点:
- 使用者愿意提供更多的上下文信息(先复制想查词所在那句话,然后再划词查找,由于多了一步,所以势必会多花一点时间)
- 开发者根据「词性」和「义项」对词典数据进行调整:如果想直接跳转词条那样,直接跳转义项,那么词典制作时就要基于进行义项分割,区分一个词条下的不同义项。但现有的词典,最小数据单元大都是「词条」,对于「义项」的处理更多是落在样式美化上。(考虑到论坛里精通 mdx 的大佬不少,提一下我个人的猜想:既然 MDX 支持 HTML 的内部跳转标签,那么词典软件是否可以通过多传入一个「词性」或者「义项」参数,从而快速跳转到相应的位置呢?不过,由于由于没有类似 Google Python Style Guides 类似的风格规范 (……English MDict Dictionary Style Guides?) ,在「内部跳转」和「词性标签」的实现上存在多种方案,适配起来会有点麻烦;而且同一个词典,会存在多个「美化版」,适配的难度和工程量会进一步加大)
上面说完了相对简单点的东西(即通过形态素分析工具判断词性进而跳转到相应词性位置(或者不展示其他词性的内容),进而缩短查找时间),下面提一个更有趣的猜想:能不能直接跳转到相应的义项上呢?
我觉得是可以实现的。原理上和通过词性跳转是一样的,但难点在于其他地方。
以下整理自本人的的读书笔记:
先补充一些背景知识:自然语言处理领域有一个专门的研究方向叫做「形态分析」,大致工作就是对一句话进行语法分析,判断主谓宾和词性。现有的开源工具的判断准确度都很好了,只是在上下文不完整的时候,准确度会受一定影响。有了较为完整的上下文,调用现有的开源工具得到词性后,搜索该词多传一个参数就可以直接跳转到相应词性的位置。(URL 中包含时<#section>可以跳到 HTML 页面的相应位置,MDict 基于 HTML,应该不难实现。但注意如何显示查询结果中的多本词典的结果呢?是只展开相应的义项,然后折叠其他的义项吗?还是说提供一个可以跳回完整义项的按钮,然后隐藏其他所有义项呢?)
回到前面的问题:英语词典的一个词性下面往往还有很多义项,找起来也很费时间。如果想直接判断是哪个具体的义项,除了以「义项」作为词典的最小数据单元外,还借助下面类似的算法进行优化:
比如,在机器翻译中,最难的问题是词义的二义性(歧义性)问题。比如 Bush 一词可以是美国总统的名字,也可以是灌木丛。(有一个笑话,美国上届总统候选人凯里 Kerry 的名字被一些机器翻译系统翻译成了"爱尔兰的小母牛",Kerry 在英语中另外一个意思。)那么如何正确地翻译这个词呢?人们很容易想到要用语法、要分析语句等等。其实,至今为止,没有一种语法能很好解决这个问题,真正实用的方法是使用互信息。具体的解决办法大致如下:首先从大量文本中找出和总统布什一起出现的互信息最大的一些词,比如总统、美国、国会、华盛顿等等,当然,再用同样的方法找出和灌木丛一起出现的互信息最大的词,比如土壤、植物、野生等等。有了这两组词,在翻译 Bush 时,看看上下文中哪类相关的词多就可以了。
(摘自《数学之美》第七章:信息论在信息处理中的应用)
目前我遇到的软件中,做过这方面优化的只有一个:「听阅」。软件内部的划词查词就会分析上下文,判断划词部分在上下文语境的成分,然后展示相应「词性」的内容(注意不是精确到义项)。
这里就不列举具体的使用感受了,有兴趣可以看看下面的文章:
3 个赞
听阅给出的词性是重新排序过的吗?如果词典里的排序是先名词,后动词,听阅会把动词排前面?
这问题本身比较模棱两可。
划词翻译功能,一般是在阅读时遇到生词(包括词组等)快速查一下,还是需要回到阅读本身。
那么, 就需要快捷确定当前合适的释义。
在手机上我用欧路词典付费版(好处是不限制外挂词典数量),欧路词典支持展开词典的设定,,支持分组,或词典排序。这三种方法都可以用来快捷看释义。
建立一个分组,放入词典专门用于阅读时快捷查词。或者,把一两本释义简洁的词典放前面,比如牛津4,或欧路自己的两本词典 ,释义简单,例句少。
至于学习时,需要查词典,另外建立一个分组,放入学习型词典即可。
分组功能是电子词典软件必须要有的功能。GoldenDict-ng里面也有。这应当是基本功能。
AI词典 ReversoContext
我往里面导入过mdx格式的词典,发现其没有进行优化。其内置使用的词典我手上没有mdx格式,所以也不清楚原来的排序是啥。
1 个赞
判断英语的词性相对容易,展示词典相应「词性」的内容很难。我觉得可能内置词典做了处理。重排 mdx 词典的排序不太可能做到。