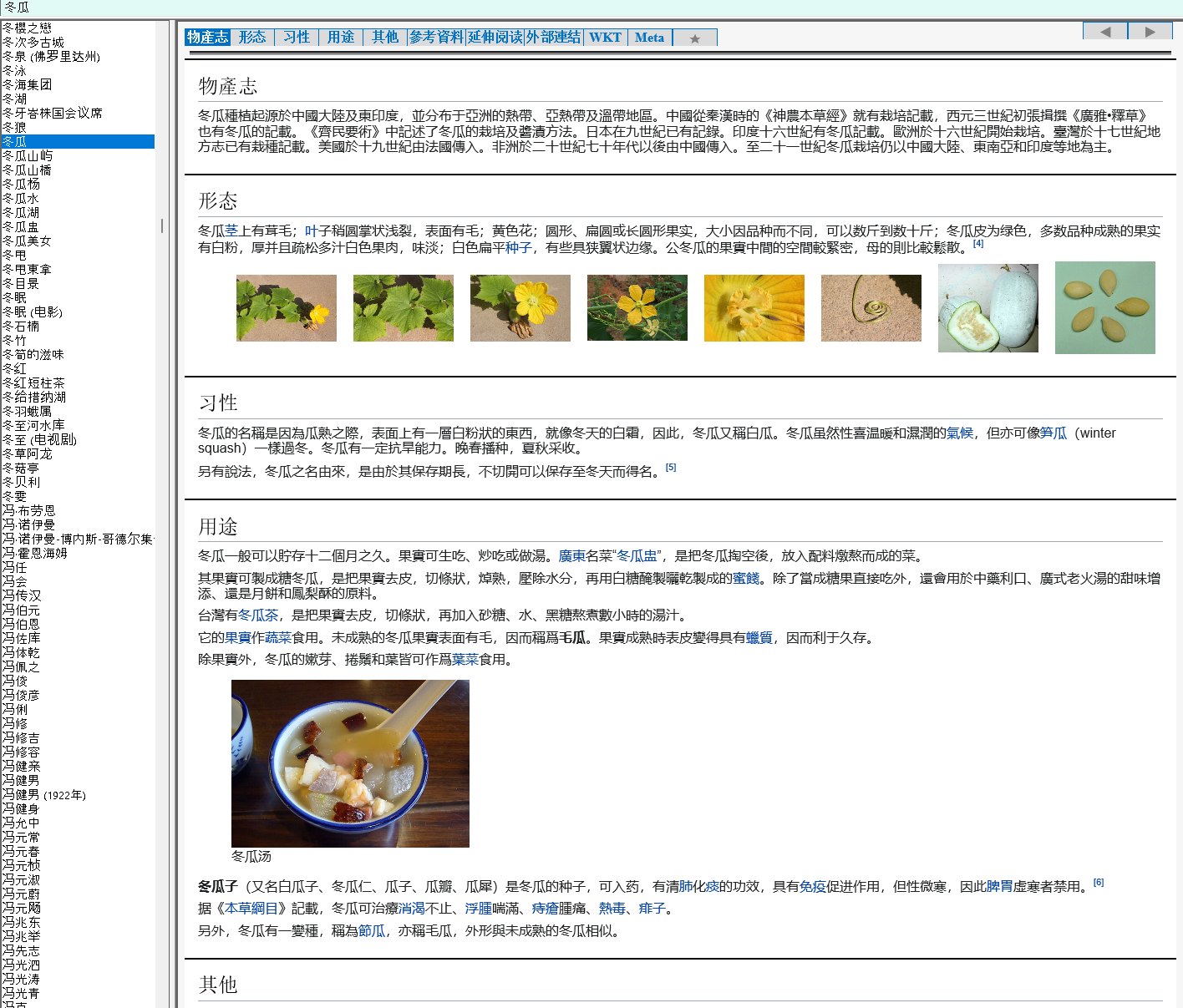
I do use multithreading, and even with that, it takes a very long time to process, memory and disk intensive too. Probably more than an hour per json file (2GB data) and average 20 hours per mdx.
It wasn’t designed for big data, wiki is orders of magnitude larger than the largest dictionaries, such as OED. I guess the process is adequate but slow given the file sizes.