with open(r’C:\a.txt’, ‘r’, encoding=‘utf-8’) as file:
content = file.read()
替换错误的前引号为正确的前引号,仅替换前引号前面不是空格的情况
content = re.sub(r’(?<!\s)”', ‘“’, content)
将修改后的内容写回文件
with open(r’D:\桌面\字典制作\113.txt’, ‘w’, encoding=‘utf-8’) as file:
file.write(content)这段代码中,我们使用了正则表达式 (?<!\s)” 来匹配前引号,但仅在前面不是空格的情况下进行替换。这样就可以避免替换掉正确的前引号和后引号。
打开文件
with open(r’C:\a.txt’, ‘r’, encoding=‘utf-8’) as file:
content = file.read()
def main():
oldString = "你的”原内”容das”fasdf”as"
newString = ""
isLeft = True
for i in oldString:
if i == '”':
if isLeft:
newString += '“'
isLeft = False
else:
newString += i
isLeft = True
else:
newString += i
return newString
def main():
oldString = "你的”原内”容das”fasdf”as"
newString = ""
isLeft = True
for i in oldString:
if i == '”' or i == '“':
if isLeft:
newString += '“'
isLeft = False
else:
newString += '”'
isLeft = True
else:
newString += i
return newString
def main():
oldString = "你的”原内”容das”fasdf”as"
newString = ""
isLeft = True
for i in oldString:
if i == '”' or i == '“':
if isLeft:
newString += '“'
isLeft = False
else:
newString += '”'
isLeft = True
else:
newString += i
return newString
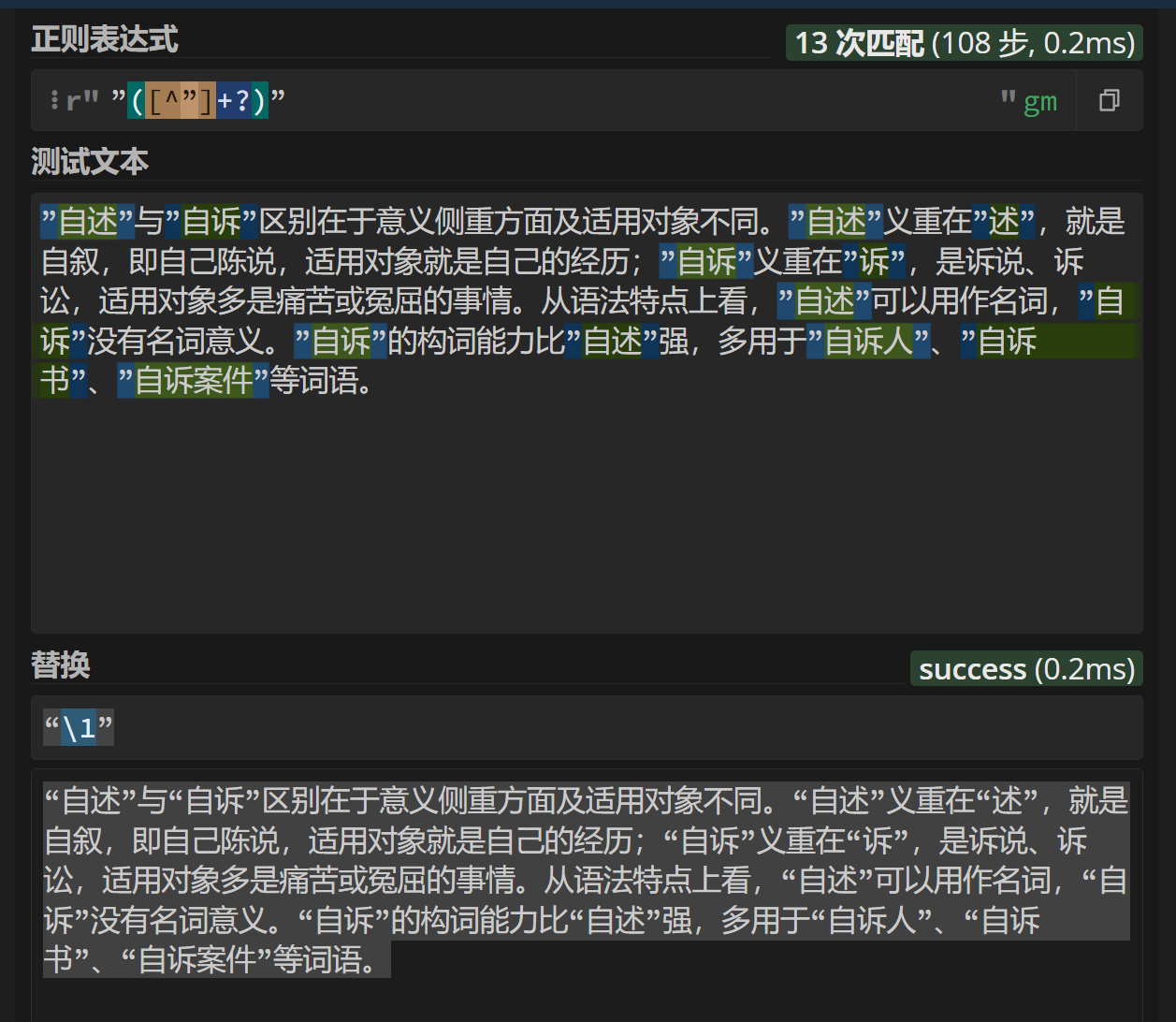
from re import sub
results = []
# 你的内容放同目录的 input.txt 中
with open("input.txt", "r", encoding = "utf-8") as f:
lines = f.readlines()
for line in lines:
result = sub(r"”([^”]+?)”", r"“\1”", line.replace("“", "”"))
results.append(result)
# 结果会输出到同目录的 output.txt 中
with open("output.txt", "w", encoding = "utf-8") as f:
f.write(''.join(results))
非正则写法:
results = []
def convert(oldString):
newString = ""
isLeft = True
for i in oldString:
if i == '”' or i == '“':
if isLeft:
newString += '“'
isLeft = False
else:
newString += '”'
isLeft = True
else:
newString += i
return newString
# 你的内容放同目录的 input.txt 中
with open("input.txt", "r", encoding = "utf-8") as f:
lines = f.readlines()
for line in lines:
results.append(convert(line))
# 结果会输出到同目录的 output.txt 中
with open("output.txt", "w", encoding = "utf-8") as f:
f.write(''.join(results))
with open(r’C:\a.txt’, ‘r’, encoding=‘utf-8’) as f:
lines = f.readlines()
for line in lines:
result = sub(r"”([^”]+?)”“, r”“\1”“, line.replace(”“", “””))
results.append(result)
结果会输出到同目录的 output.txt 中
with open(r’D:\桌面\字典制作\113.txt’, ‘w’, encoding=‘utf-8’) as f:
f.write(result)
这个脚本运行无输出。
第二种非正则写法运行完美,太感谢了。保存以后这种问题就可以解决了。
```<代码类型,如 python>
<代码>
```
例如:
```python
from re import sub
results = []
# 你的内容放同目录的 input.txt 中
with open("input.txt", "r", encoding = "utf-8") as f:
lines = f.readlines()
for line in lines:
result = sub(r"”([^”]+?)”", r"“\1”", line.replace("“", "”"))
results.append(result)
# 结果会输出到同目录的 output.txt 中
with open("output.txt", "w", encoding = "utf-8") as f:
f.write(''.join(results))
```