这本书字不多,有三万多条,最头疼的就是这拼音。在坛子里也看了好多天了,终于学会了使用AutoMdxBuilder。我觉得这本书比较适合做成图片版的,做好了,以后有兴趣再改文字版吧。开始做索引,慢慢来吧,毕竟得一字一字校对。
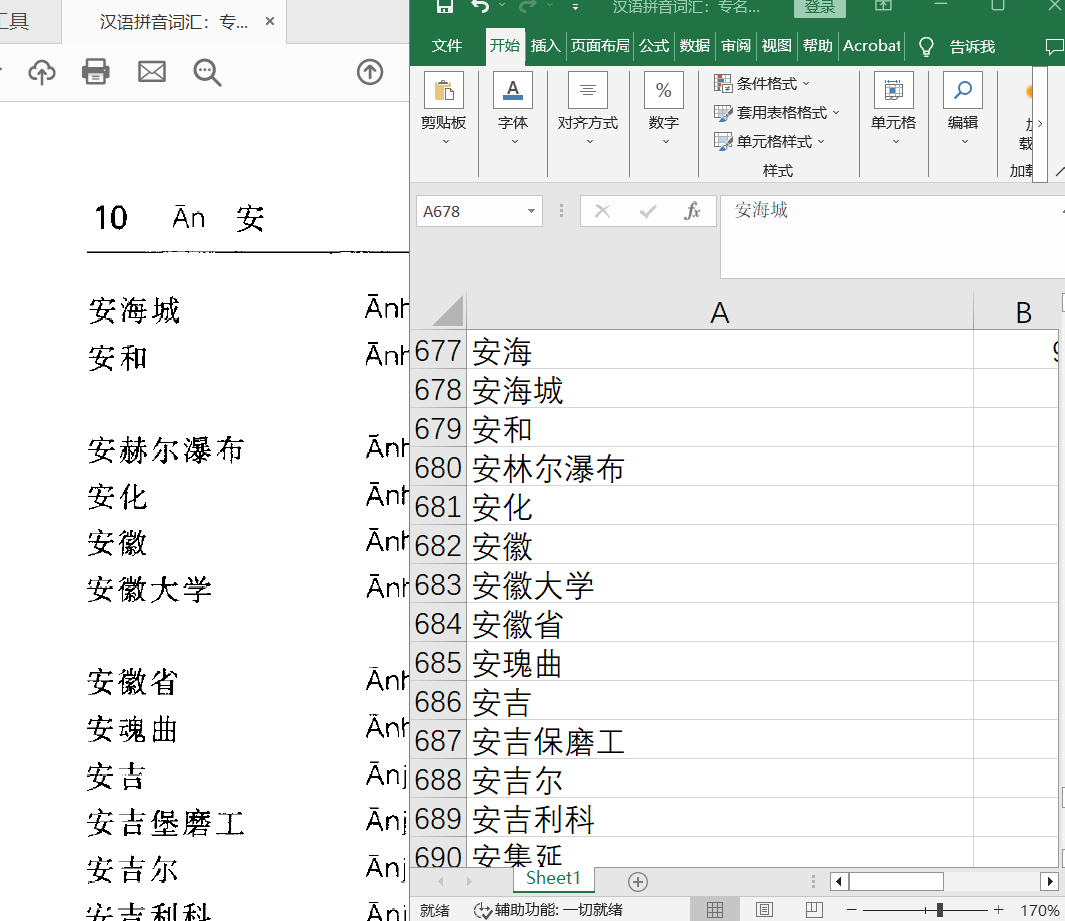
4 个赞
我是一条一条OCR的,边识边校。
你好,请问可以分享一份图片里识别语言中的“拼音”文件吗,谢谢。
这个可以自定义,无法单独提供。
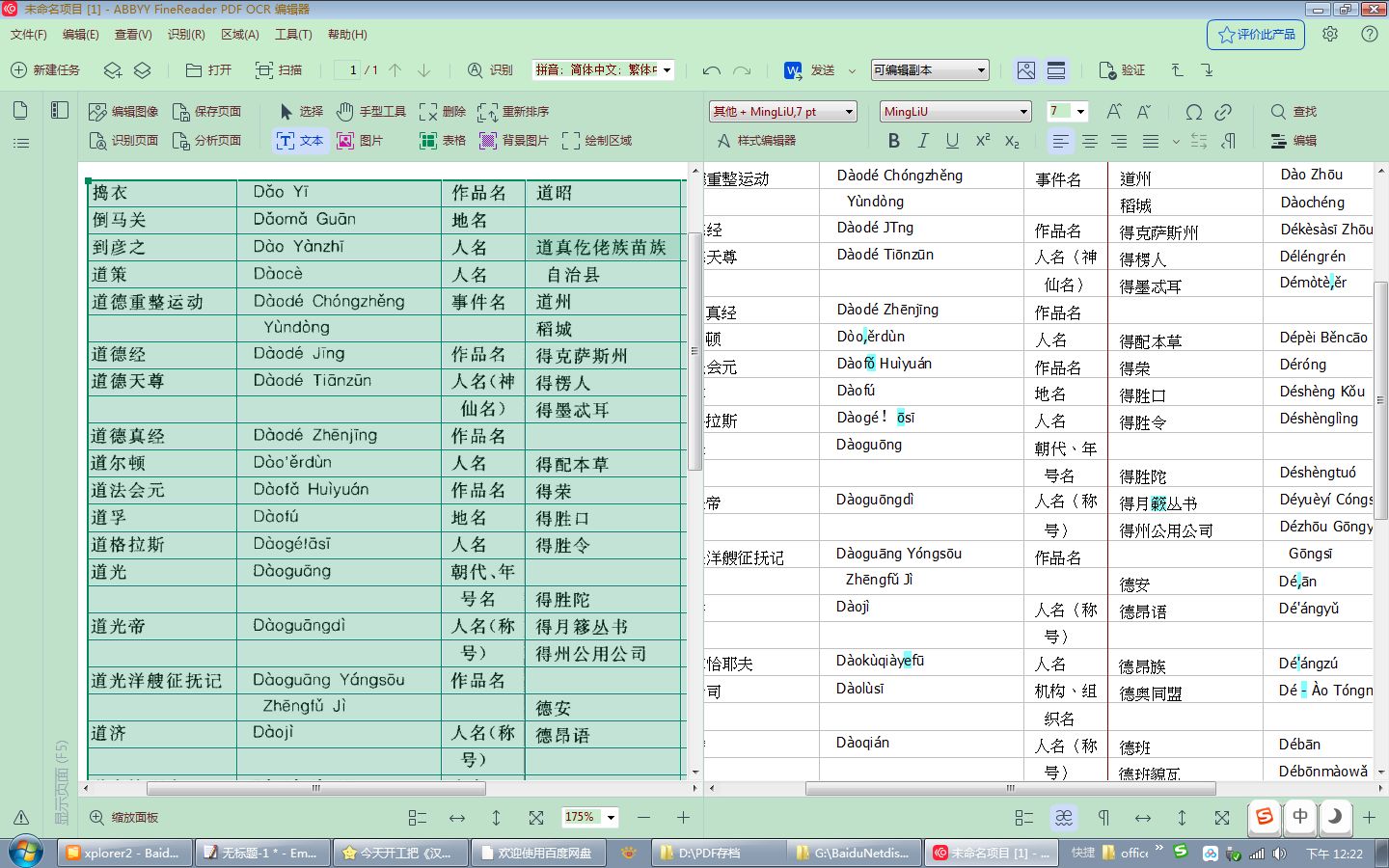
自定义拼音识别语言,提高finereader拼音识别率
你可以这么做
1,
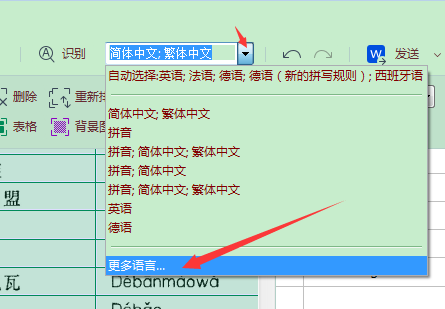
2,
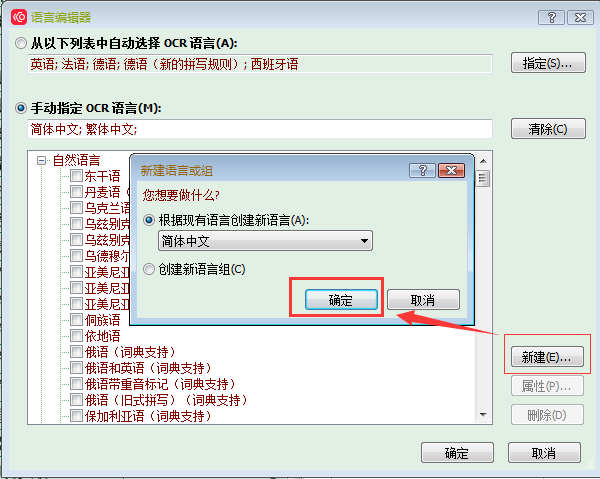
3,
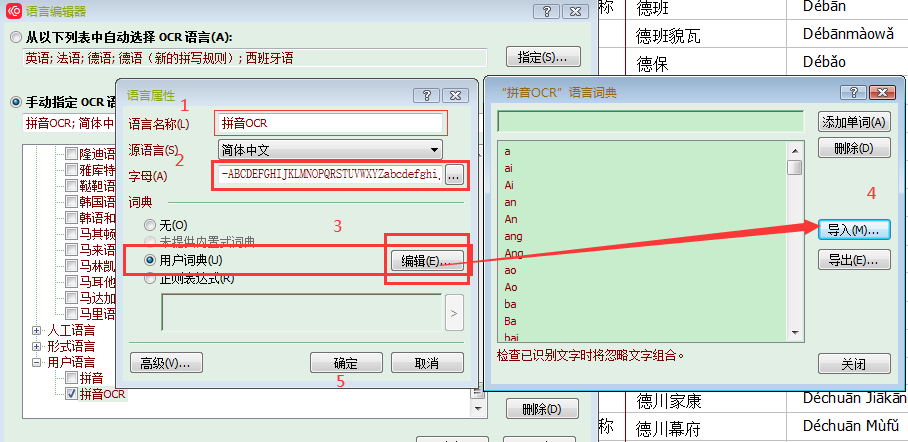
字母内容填这些
-ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzÀÁÈÉÒÓàáèéìíòóùúüĀāĒēĚěīńňŌōūǍǎǐǑǒǔǖǘǚǜǹḿếề’
导入拼音词典
拼音导入.txt (76.9 KB)
(如果修改此文件,注意保存编码为 utf-16le有签名)
4,
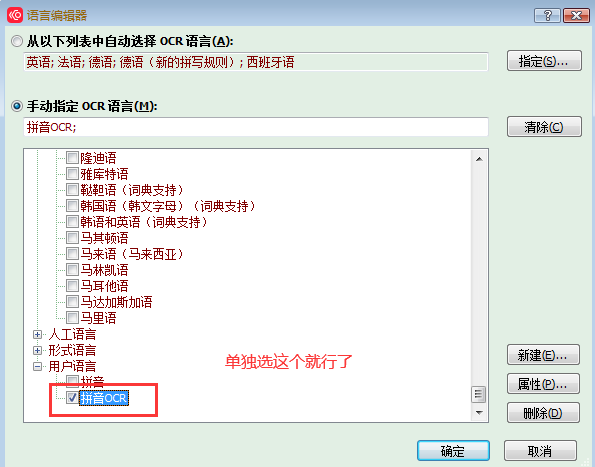
5,对页面进行识别。
这个方法能大大提高finereader的拼音识别率,减少误识。
但依然无法完美识别,剩下的就是得靠眼睛了。
1 个赞
这么详细的教程,非常感谢! ![]()
大工程 感谢您的制作
拼音这个东西现有软件(比如Word?)应该能标注吧,是不是可以将软件标注的结果与OCR结果进行比对,然后人工校对那些不一致的。
word拼音标注一次有字数限制吧。带声调的可用的词库确实也不多。一般都是没有带声调的。
今天词头已录入完毕。目前已校对到Y打头的词条。开工后不久我就发现该书词条在《辞海》第7版中均可以查到,且都有读音。也许此书是当初为无读音的《辞海》第6版补充的读音吧,一直当工具书在用,就算练个手吧。顺利的话图像版过两天就可以完工了。
1 个赞
今天终于完工了,试了一下AutoMdxBuilder,版面不太满意,最后还是费了点劲选了vim的MdxSourceBuilder,对于制作图像版已经不错了。这是我的第一个词典,里面难免有错,如发现请大家留言,下次再订正。里面有些字打不出来的,可能就用X代替了,以后再想办法完善吧。
图片V版.part1.rar (20 MB)
图片V版.part2.rar (20 MB)
图片V版.part3.rar (20 MB)
图片V版.part4.rar (20 MB)
图片V版.part5.rar (20 MB)
图片V版.part6.rar (9.0 MB)
4 个赞
下面加着重号的文字在识别的时候90%以上都是错的,这个有没有什么办法解决?