刚找到16,就跟15对比了一下ocr效果。用一本有代表性的扫描版pdf书做ocr后比较效果。16的提升很明显。
而之前曾经比对过15与其他3个ocr工具的ocr性能–万兴pdf 7.6.8,白描软件,acrobat 2021–15明显胜过这三个。不过,只做中文简体的pdf的ocr,也可以用万兴7.6.8(万兴8的ocr效果不如该7.6.8版本)。
这是从另外一个帖子引出的,那个帖子有16的下载。
刚找到16,就跟15对比了一下ocr效果。用一本有代表性的扫描版pdf书做ocr后比较效果。16的提升很明显。
而之前曾经比对过15与其他3个ocr工具的ocr性能–万兴pdf 7.6.8,白描软件,acrobat 2021–15明显胜过这三个。不过,只做中文简体的pdf的ocr,也可以用万兴7.6.8(万兴8的ocr效果不如该7.6.8版本)。
这是从另外一个帖子引出的,那个帖子有16的下载。
用Adobe acrobat 2021,abbyy finereader 15,万兴pdf7.6.8.5031,白描网页版分别对一本具有代表性的PDF书籍进行了OCR,并比较效果,结论是,abbyy finereader 15是最佳选择。
1,所用到的软件
Adobe Acrobat 2021(AA),
Abbyy FineReader 15,(AFR),
万兴PDFelement 7.6.8
白描网页版
Filelocator pro(FLP),
Araxis Merge,
2,用《德语语法表解》进行OCR和效果对比
(1)该书PDF格式共计210页,内容德语汉语混排,德语居多,约八九成,汉语约一到两成,极少的英语。扫描而成,页面清晰度较差,没有灰度。
(2)用abbyy进行OCR,选择多语,包括汉语,德语,英语,及一些辅助如数字等,OCR的速度很快。OCR后保存为一个文件。另外,进入页面校对,修改了几个单词,另存为一个文件,用于效果比对。得到2个文件。
(3)在Adobe Acrobat 2021中,分别OCR三次,存为3个文件,进行效果比对。
只选择德语进行OCR,存为第一个文件。在德语OCR后,再选择汉语进行第二遍OCR,然后保存为第2个文件。只选汉语OCR后保存为第三个文件。得到3个文件。
以上共计6个文件,大小对比很明显。Acrobat选择汉语进行OCR后文件体积增大一倍,增加德语再作一次OCR,体积再增加一倍。
而Abbyy的OCR后的文件,体积反倒减小了。
(4)OCR的效果的比对,
用了三个方法,分别是,
-在Araxis Merge中,进行文字型PDF的内容比对。
-在Acrobat 2021中进行文件比较。
-用Filelocator Pro进行检索比较。
最终,
(1)在Acrobat中,选择德语进行OCR,只对部分的汉语进行了OCR;只选德语,情况类似。在汉语的OCR中,才对全部的汉语进行了OCR。这点在Araxis Merge和FLP(FileLocatorPro)中得到印证。
(2)abbyy的多语种OCR得到的文件,不管是汉语,德语,识别效果都远胜于acrobat的。在FLP中,用一些单词或字母进行检索,选择专家模式。比如检索“Vater”,可以看到abbyy的识别文件和acrobat的仅仅德语或先德语后汉语的三个文件,命中18次,而仅仅汉语的,只有14次。
3,万兴pdf和白描
万兴PDF在OCR该书时失败。
用白描软件测试OCR,用其网页版,限制PDF为50页,遂选该书前40页。识别效果很不错,比acrobat还略高,但不能保留格式,如表格等。该白描软件用于局部是可以的。
结论,abbyy finereader 15。
在5月份对比了AFR15与其他几个常见ocr工具的ocr性能。这次得到AFR16,遂对比了一下15和16的ocr性能。
结论是:16比15的ocr性能有明显提升,值得升级。
1,怎么对比ocr性能
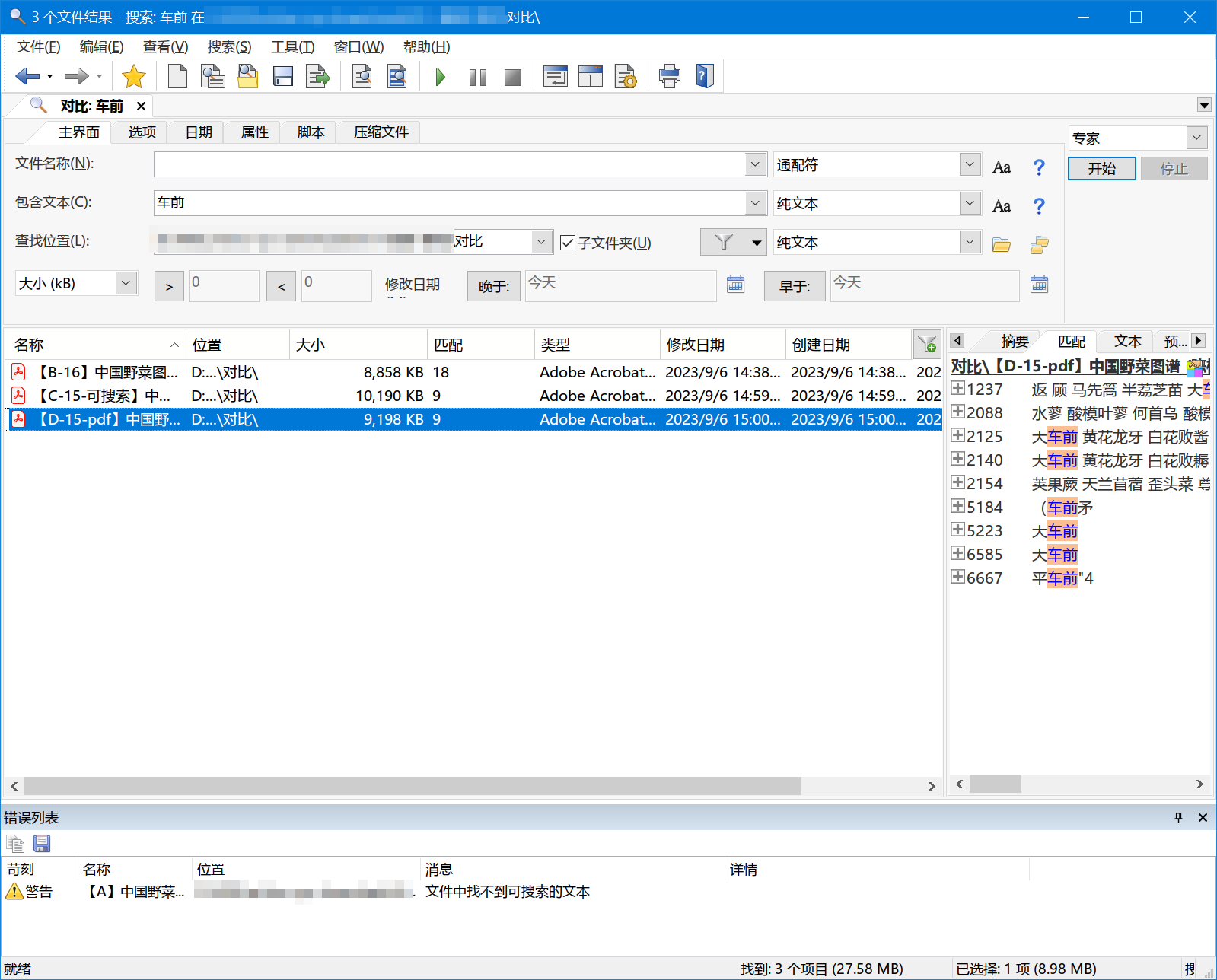
刚好有本书野菜图谱要ocr,该书恰好有代表性,代表了需要ocr的书中扫描质量较差的。一般的,需要ocr的书的扫描质量比它要好。该书89年印刷的32k的287页,文字黑白,有彩色照片和黑白表格等,显示在2004年制作为pdf,可能是读秀流出的。
原pdf大小8mb,标记为A。用16做了ocr,标记为B,文件大小几乎相同。再用15做了ocr,存时有2个选项,存为searchable pdf,标记为C,10MB;存为pdf,标记为D,文件大小是9MB。得到3个ocr的PDF文件。
2,具体过程
与之前方法完全一样
(1)首先对比了一下C和D的差异。
在acrobat 2021中对比文本,结果是相同。
见附图1,
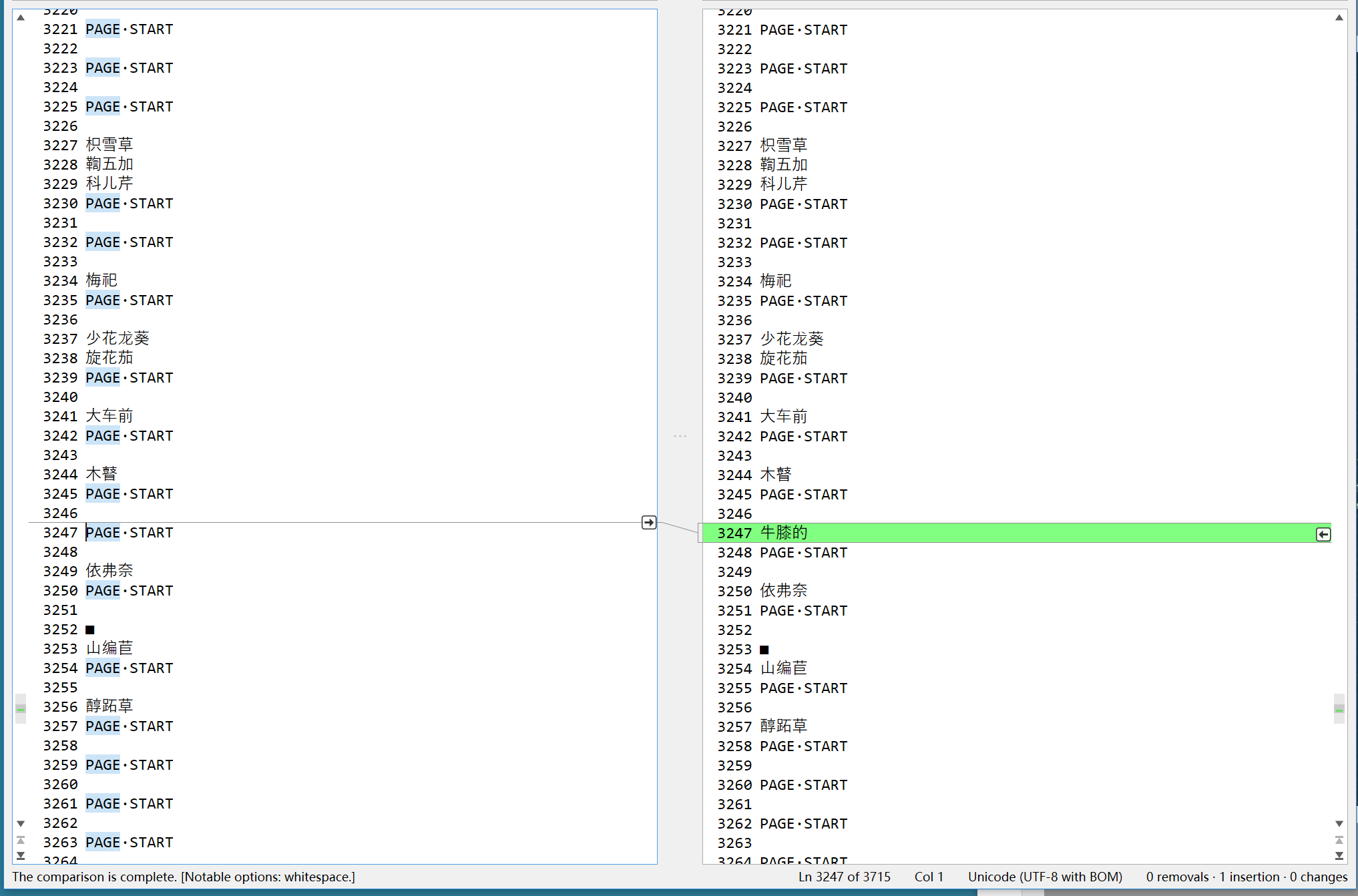
(2)在AM中对比,发现仅有一处不同。见图2。
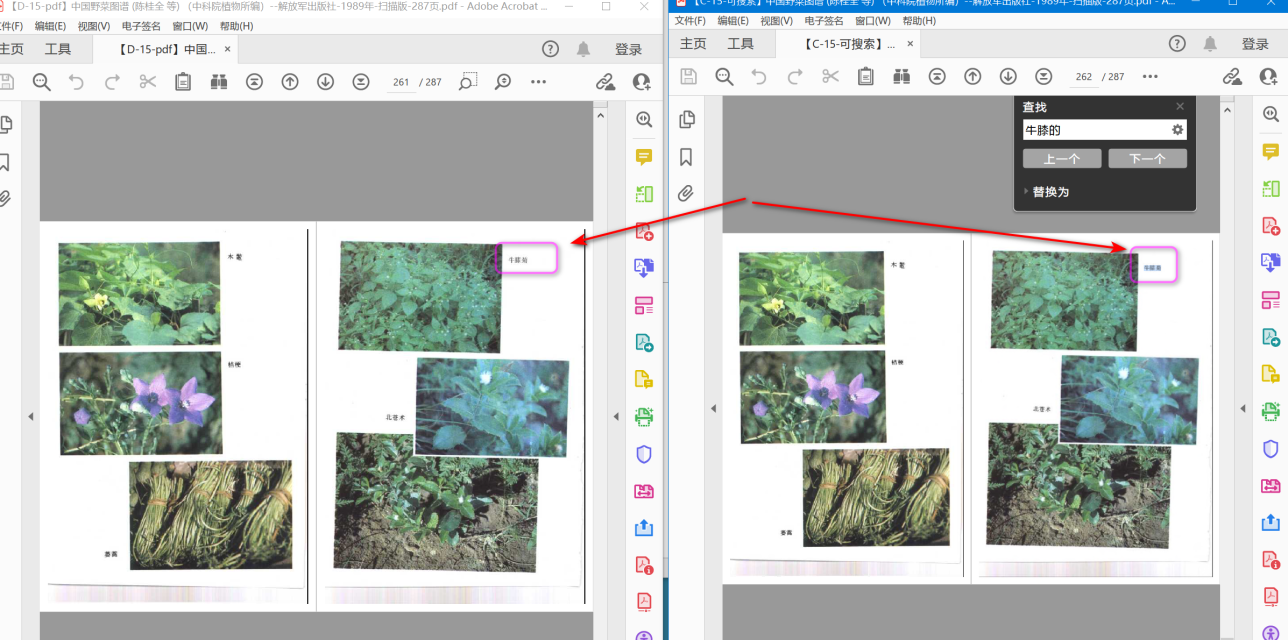
查看了一下具体页,是字262页,其中C识别为“牛膝的”,D未识别出,仍当作图片。见图3。
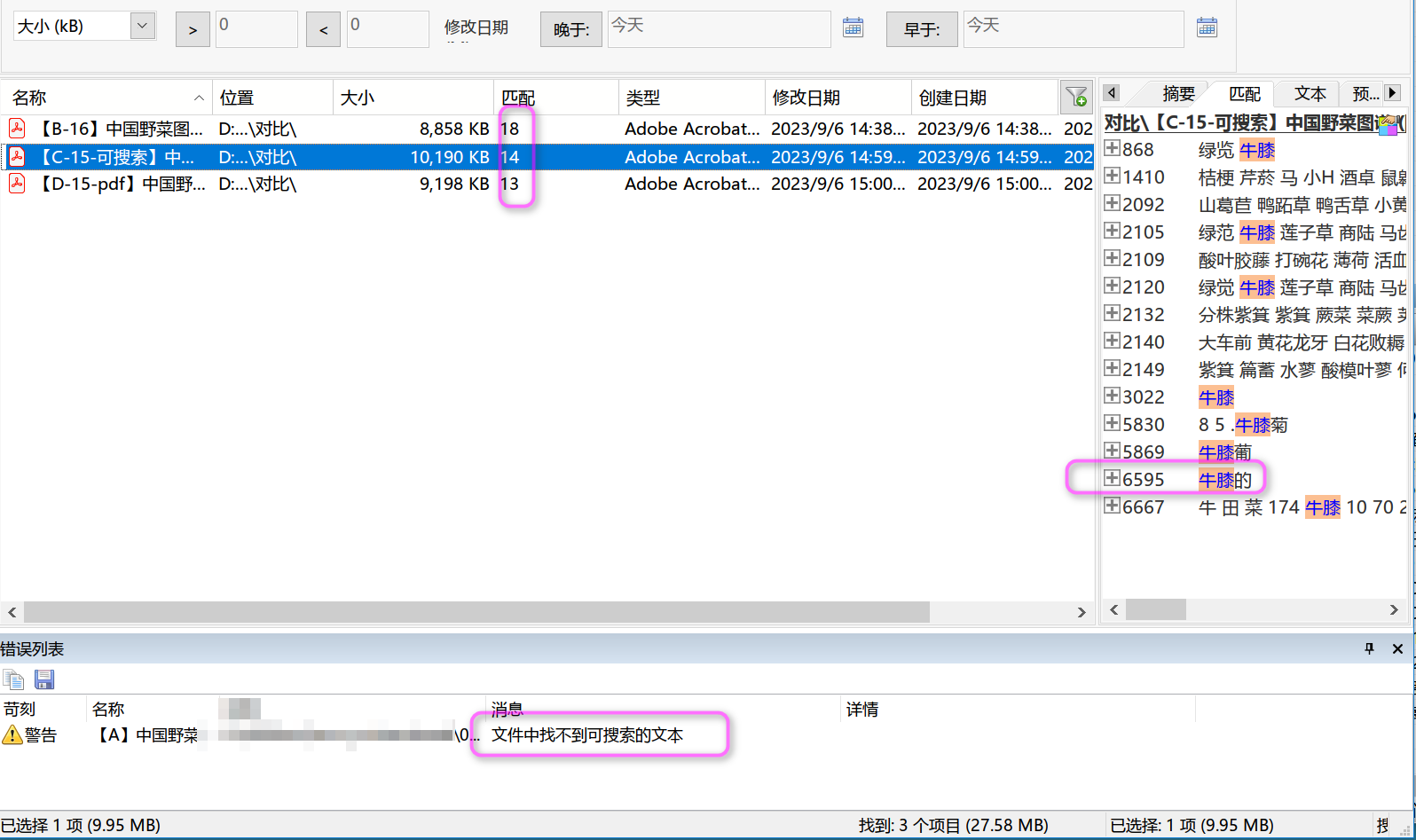
(3)用FLP,对A,B,C,D进行检索关键字。
搜“牛膝”,FLP告警,说A未见文字,真是好样的软件!B命中18,C命中14,D命中13。详细看了一下就知道了,ocr性能上,B明显要比C好,差了3次。而C和D相差一处,被FLP发现,AM也发现,而acrobat未发现。见图4。
(4)再检索一个字吧,“车前”,B命中18,C和D都是9,9处是相同的。差距更大了。见图5。
足够得出结论是,ocr性能,16明显优于15。
另外,在acrobat中,对比文本的结果有失误,它的对比能力不可信。
ocr速度上,16比15要明显快一点。不过,考虑到总时间不长,因此这点可忽略。
16是,ABBYY-FineReader-PDF-Corporate-16.0.14.7295-Portable。绿色的,可能就是sandyd大神的封包,注册应当是TCCS大神搞的。感谢两位普罗米修斯!
—end— - -结尾 - -
依次是截图1-5
其实我不太建议用特别复杂的例子进行极限测试,比如扫描质量差、多国语言混排,因为不太符合日常使用场景。如果要测试,也是作为其中一项,更多地还是测试扫描质量尚可、只有中文、只有英文、中英文混排(例如词典,这个属于本坛常用场景)。
楼主是想要制作双层的PDF。
大侠,分享一下,我也试试
我对abbyy16的评价是:没太大变化,但又变化很大。
没太大变化的是识别引擎,准确率等方面个人感觉没什么变化。
变化很大的是终于升级为64位程序,无论是速度还是大文件的支持都有很大提升(同时也具有了把我48G内存吃干抹净的能力)。
个人认为中文的OCR面临这一很难解决的问题:生僻字和常用字的字形差异太小,出现频率差异又太大。一个完全不认识“彧”,全都当成“或”的OCR软件大多数时候都不会造成问题,但一个认识“彧”,会把百分之一的“或”识别为“彧”的OCR软件也会造成很多问题,毕竟人们并不是每天都在研究三国历史。这就好比对一种罕见病进行人群普筛,假阳性会比真阳性多很多倍。
想解决这些问题必须要用上些自然语言处理的方法(“彧”字出现时往往都是那一种情况),而且需要比较大的语料库。
这里可以分为2个子话题,
1,什么情况,需要对图像型pdf作ocr?ocr要达到什么效果(识别率想要多高可以接受)?
2,pdf的语言种类
单纯就纯简体汉语的pdf书图像型,16比15要强。若pdf的扫描质量不高,可能区别就更大。
有效期对比的,可以贴一本书,我用15,16各自ocr一下,不做校对,对比效果看看。
若书若太大,任意取出50页即可。
我觉得OCR未来的方向是ChatGPT之类的生成式AI进行校对,给出建议,这样人工只要扫一眼就行。只是感觉大厂对于OCR这种基础的落地用途不感兴趣,反正总体识别率已经不错,却不知道即使识别率能有99%用户也不满意,因为依旧需要大量的校对人工。
大厂甚至连周边辅助功能都懒得做。目前这种周边辅助功能做得最好的无疑是Abbyy,但是Abbyy似乎甚至连识别本身都没用上AI,识别率是不太行的。
懒得做才是正常的。校对书籍文本不是非专业人士的常用需求。
识别率当然越高越好,16比15好点,只是强的有限,制作文字版PDF+校对,Abbyy是绝对的王者,但比较ocr的识别率,还是在线ocr的结果更好,之前论坛里有人贴夸克的ocr,比这两都好。
16的改进范围很大,我只关注了ocr功能。自己手工搞了对比,16的ocr比15有明显提升。在免费升级情况下,自然要用16替代15了。
一,识别率这个东西,够用即可。对于重要的东西,哪怕软件说100%识别了,在ocr后也得人工全部核对一遍,甚至多遍。 二,说到我的使用场景是,对图像型pdf作ocr后,重点看一下目录和章节,有时页看一下索引或词汇表部分,不要有太大偏差。三,对我来说,ocr的目的主要是便于看书时检索某些内容。有时是对比一下内容,用软件粗筛对比,再肉眼对比。15的识别率足够了,16可以更好,自然要升级到16了。
文本化词典,不精校对没法用,一万字修正100字错误和修正500字错误,体感完全不一样。如果你只是制作双层PDF,满足你自己的需求,我同意你的看法。
年初使用Abbyy OCR制作了六本中文书电子书。分别用了11,12,15,16这四个版本的软件。结论是总体识别15比较均衡。生僻字识别只有11最好。
厉害,对比了v11,v12,v15,v16四个版本。我早已清除了旧版本,现在只有v15和v16。
不过,生僻字只有11最好吗?这个能不能发你的样本来验证一下,可以摘取原书中20-50页做成pdf样本,提供一份图像型pdf,一份用v11做过ocr的双层pd(f或干脆导出的word)。用我手头的v16,v15验证对比一番看看情况。
肯定,确认,绝对,11是生僻字识别最好的,因为我是OCR识别后逐字校对,一一比对过。本来我也只想保留最新版ABB,无意中发现这个生僻字识别问题。图书是繁体字,生僻字尤其多,11识别了85%的生僻字。其他版本只能50%左右。不好意思,文本是版权图书,不便外传。
从软件模型的开发分析,新版的肯定比旧版的功能有改进,识别率绝对提高,有软件设计常识的都懂!
这可不一定哦。我以前玩ABBYY发现,它在某次升级时,图像文件的大小突然增加了好几倍。仔细检查发现,ABBYY抛弃了以前的我认为很好的图像格式,直接导致双层(图像+文字)pdf的大小增加了很多。