已经将原始PDF拆成单栏OCR结束,并将可能的词头标好了。
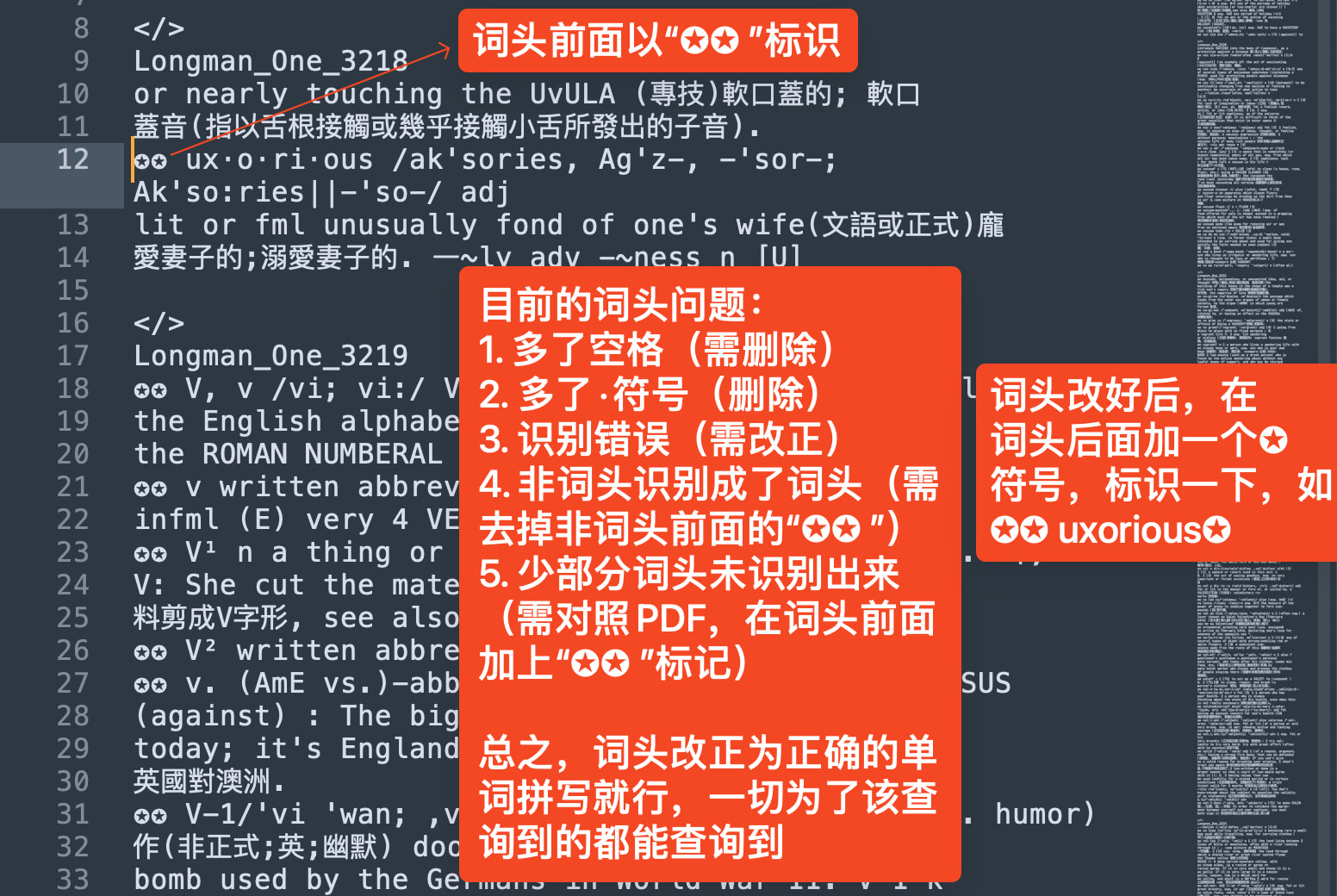
不过有些词头可能多了空格,或者少了引号,问题不一而足,需要17人分工校对,每人大概200页,也就是原PDF的100页(因为原始PDF是双栏的)
因目前PDF无法公开获取,感兴趣的童鞋,可以私信我获取:
- 校对的200页左右的PDF
- PDF对应的OCR文本(修改词头是在这个文本里修改)
目前剩余11份PDF待校对。
目标词头格式: ✪✪ abandon✪
(方便后期提取词头,制作图片词典)
像✪✪ bay³ 这种带有右上角数字的词头,上标数字不要包含在词头里,改成 ✪✪ bay✪³ 即可。
A-1 这种:数字属于词头一部分的就带上数字(这种也不是上标)
![]() :只需要校对词头即可。音标,中文翻译,英文释义都不需要校对。因为制作的是图片词典,只要有词头就够了。
:只需要校对词头即可。音标,中文翻译,英文释义都不需要校对。因为制作的是图片词典,只要有词头就够了。
后续也可以将英文例句添加为索引,不过这个不需要校对了:只校对词头即可
校对的时候有疑问,随时联系