这个重拼法起到的作用类似音标,也是发挥标音作用帮助拼读。网上经常有否定音标的言论,说什么美国人不学音标,只靠自然拼读,实际上自然拼读有天生的缺陷(因为英语很多单词不符合拼读规则),美国人也是要标音工具的。
而我们二外者为什么不用这个而用音标呢,当然是因为这个不如音标好用。
这个网站音节很好,发音不是国际音标。
有没有显示音节和国际音标一起的网站?
我没有那样的网站。提醒你学发音其实靠多听和对着音标多念就够了,知道音节数没必要。
牛津高阶(第10版 英汉双解)V14.3可以像第8版一样加单词音节划分吗?——在哪里下载的?老大。
请教一下 可以介绍分享一下您的牛津高阶双解V3.1.2版++5版本吗? 谢谢
非常感谢 ![]()
之前看到这个帖子后,突发兴致,写爬虫去爬多个音节划分的网站,但是数据存在一些问题,有的单词划分不一样,没有做mdx.
这周看到论坛有贴牛10 app,反编译出数据库,看到有音节划分.今天抽空,基于v14.8, 修改出v14.8+.
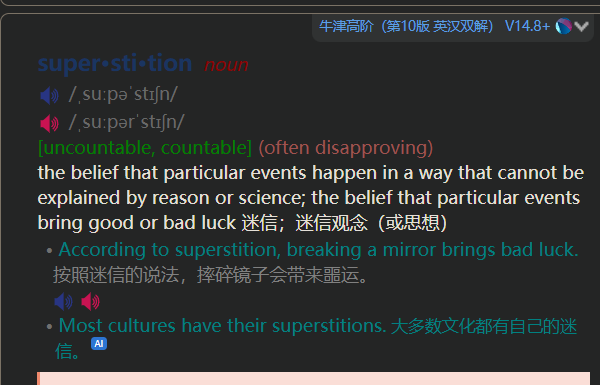
附上mdx地址, 记得改后缀和文件名
2 个赞
能否分享下app数据?老实讲拿app数据再做一版就完全碾压了。
这个hanyl05卖的牛10是拿很久以前的官网英文数据结合牛8汉译,再把没汉译的用ai来翻译,质量参差不齐,赶不上时代。
apk:
解压assets目录下ciku.db就是了
3 个赞
Amazing 竟然没加密的。
3 个赞
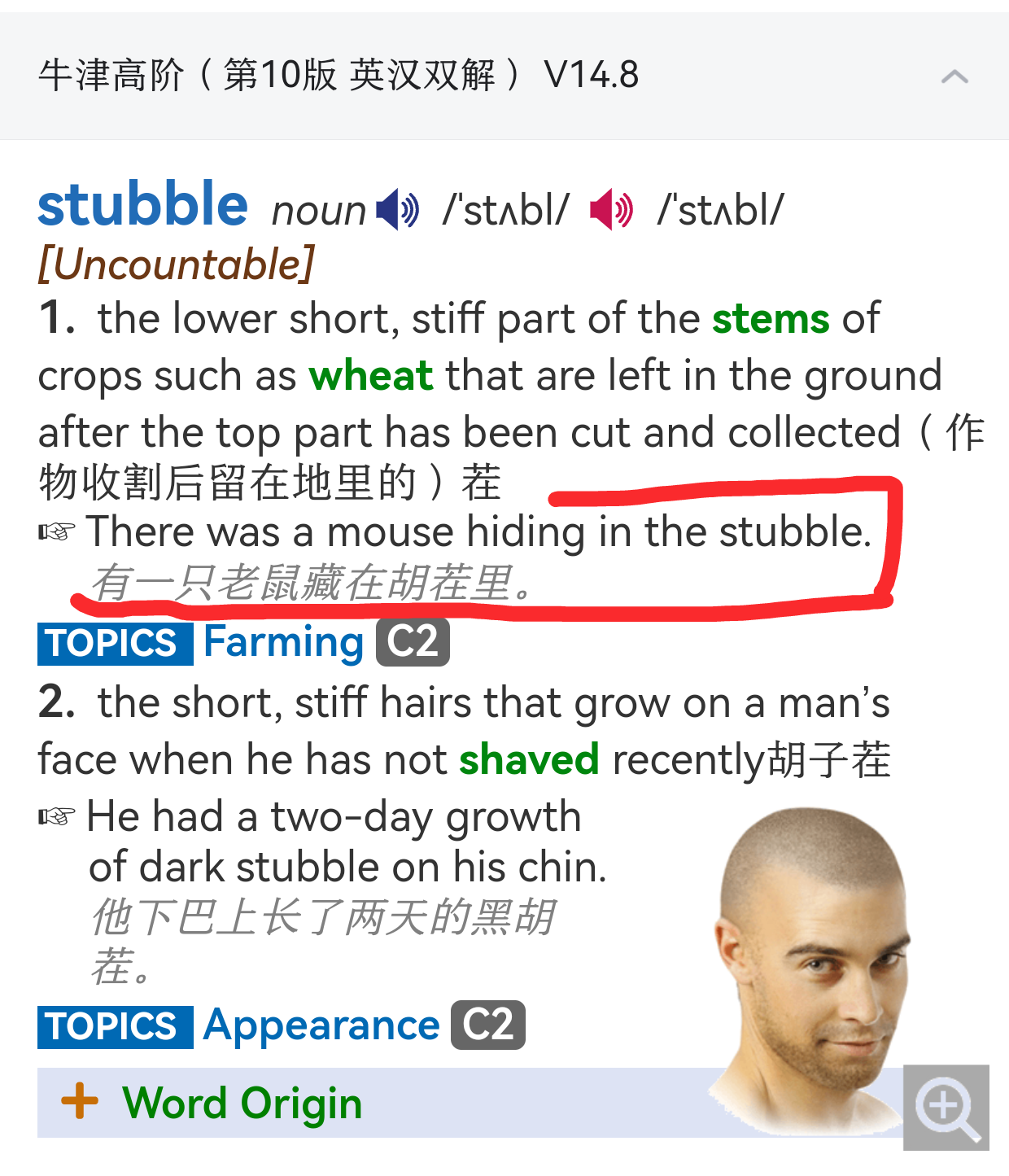
粗略看了一下,有详细的 word_body 的词头只有 40974,这个数量似乎不太对劲,比如 abaft,zeugma 等以前版本有的词,在这个数据库里就找不到,不知道是初期的 bug,还是有什么隐藏部分
没详细比对,检查数据库,词头少了5k条,变形词少了16k条,词组少了2k条。没有实体书不知道是不是真缺词。不知道港版的数据库会不会更全,楼上这个版本光看数据表就少了很多。
查了纸书,没有abaft,zeugma词。
你好,港版没有apk,我用的ios。ios版牛津英汉辞书高阶第10版中有abaft,但是没有zeugma。
- mdd文件共用之前版本的,任意牛10都可以, 只提供修改mdx
- 发帖就说明了, 不同网站部分词的划分会不一样, 直接采用牛津10标准的划分的
你好,能分享一下V14.8吗
多谢了,终于不用旧版了