想把一本意大利语反向动词查询的链接去掉,换成@@@link=动词不定式,请问如何用正则替换。就是想删除每一个单词的span class=verb style 这一项,有没有简单的方法。
你是想让大家凭想象力解题嘛 ![]()
建议你附上文件或者多来几张图
想删除span class标签,把跳转链接转换成@@@LINK,请问该怎么弄,简单点的办法,正则小白

后面相同的部分替换为空,前面的部分
.*entry:// 替换成 @@@LINK=
只是给你一个思路,自行探索一下
谢谢hua,前面知道替换,就是后面每个单词不同,不会删除,能教教我吗?

举个英语单词的例:
went
@@@LINK=go
</>
就是想输入意大利语动词各种变位直接查动词不定式,也就是动词原型。
hua的办法和我一样,就是把entry://直接替换成@@@link=,可后面每个单词跳转链接不一样,没法全删除,只能一个个删,几十万行,得删到猴年马月
是不是我上面那个图结果,再把 entry:// 去掉?
能不能发一段文本出来? 没文本,恩。。你自己朝着思路来吧
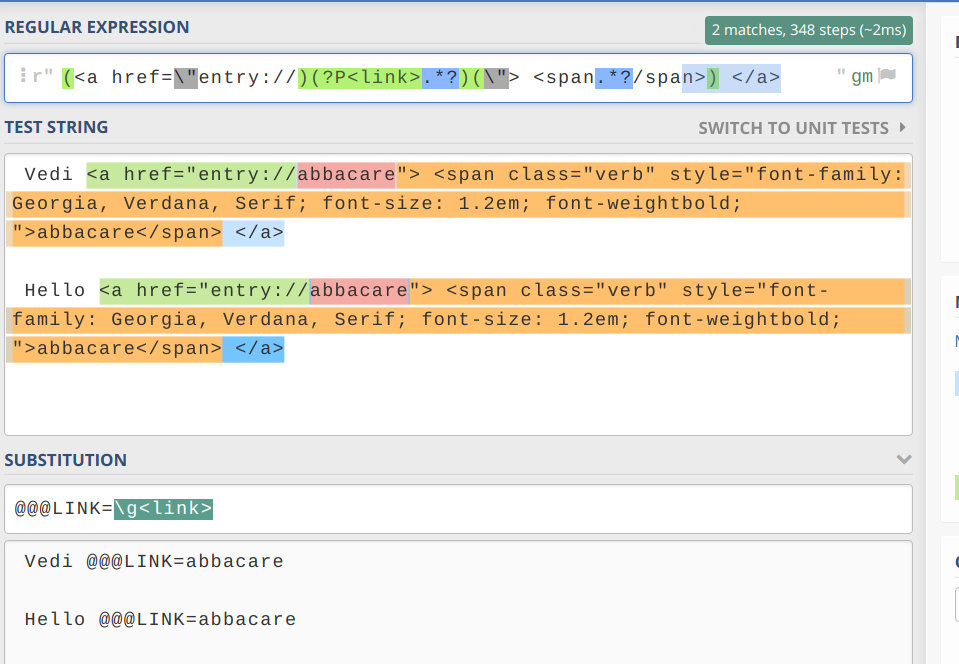
# coding=utf8
# the above tag defines encoding for this document and is for Python 2.x compatibility
import re
regex = r"(<a href=\"entry://)(?P<link>.*?)(\"> <span.*?/span>) </a>"
test_str = (" Vedi <a href=\"entry://abbacare\"> <span class=\"verb\" style=\"font-family: Georgia, Verdana, Serif; font-size: 1.2em; font-weightbold; \">abbacare</span> </a>\n\n"
" Hello <a href=\"entry://abbacare\"> <span class=\"verb\" style=\"font-family: Georgia, Verdana, Serif; font-size: 1.2em; font-weightbold; \">abbacare</span> </a>")
subst = "@@@LINK=\\g<link>"
# You can manually specify the number of replacements by changing the 4th argument
result = re.sub(regex, subst, test_str, 0, re.MULTILINE)
if result:
print (result)
# Note: for Python 2.7 compatibility, use ur"" to prefix the regex and u"" to prefix the test string and substitution.
没有文本,我 ocr 的文本,格式可能和你的文本不一致,因此仅供参考。
你直接拿出一段文本来,说它应该变成啥文本,不就好了? 你要是老这样解释,我是理解不了了,那我就溜了。
不明白,意大利语动词反向查询的跳转链接,跳转动词,变形词转到headword 啥我都不知道是啥emm。
没学过意大利语,没做过字典的我,瑟瑟发抖。哈哈。
嗯,就像我举的英语go那样的模版
谢谢你的耐心解答,我没有说清楚。这个是一份意大利语动词反向查询的跳转链接,制作者在txt里加了每个跳转动词的颜色,字体,所以后面除了跳转动词不一致,整个标签其实是一样的。不知道我这么解释,你明白了不?
谢谢你的耐心解答,我没有说清楚。这个是一份意大利语动词反向查询的跳转链接,制作者在txt里加了每个跳转动词的颜色,字体,所以后面除了跳转动词不一致,整个标签其实是一样的。不知道我这么解释,你明白了不?
其实,制作原理是一样的,英语词典里很多人都加了这种链接,就是把它的变形词转到headword
后面是不定式的字体和颜色,单词都不同,怎么替换啊?只能替换相同部分。说清楚点,可以吗?
觉得可以琢磨下vim应该可以搞定,查找替换应该就可以了