Capture2Text 有 Linux 的移植版本,本质上就是带界面的 Tesseract。对 Linux 用户来说太臃肿了,因为只要几行命令就可以:)
调用截图工具 存到临时文件,然后用 Tesseract 来做 OCR 传给 GoldenDict
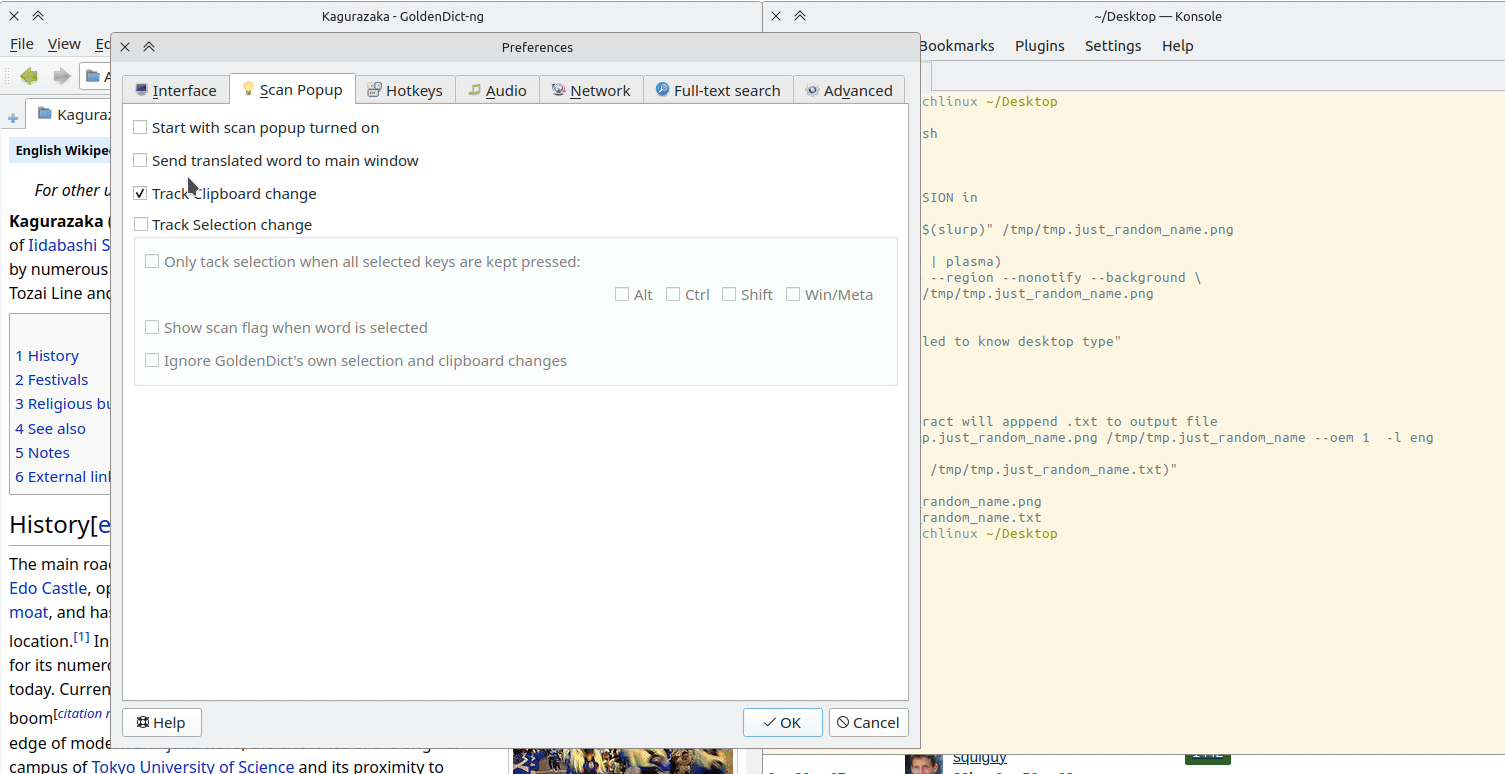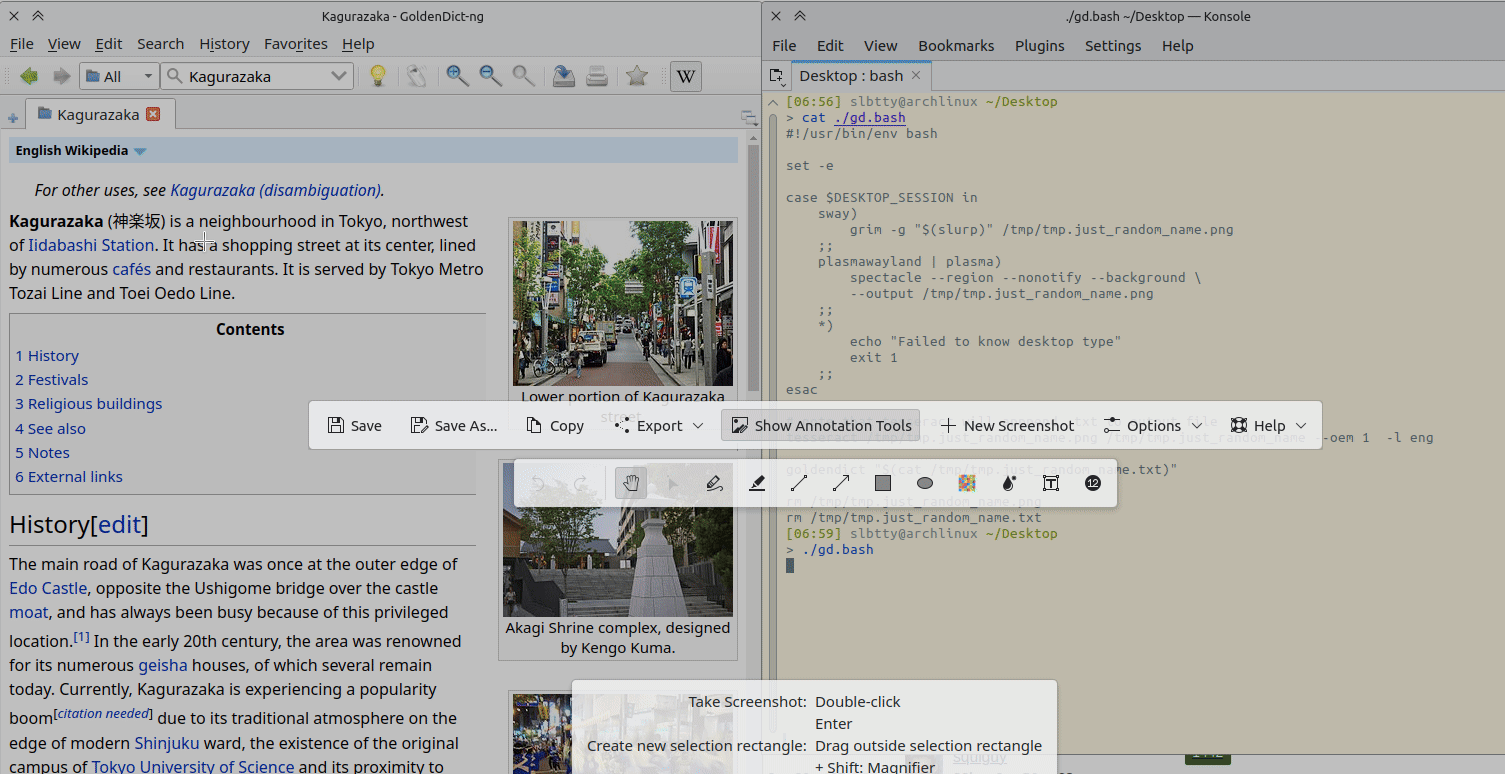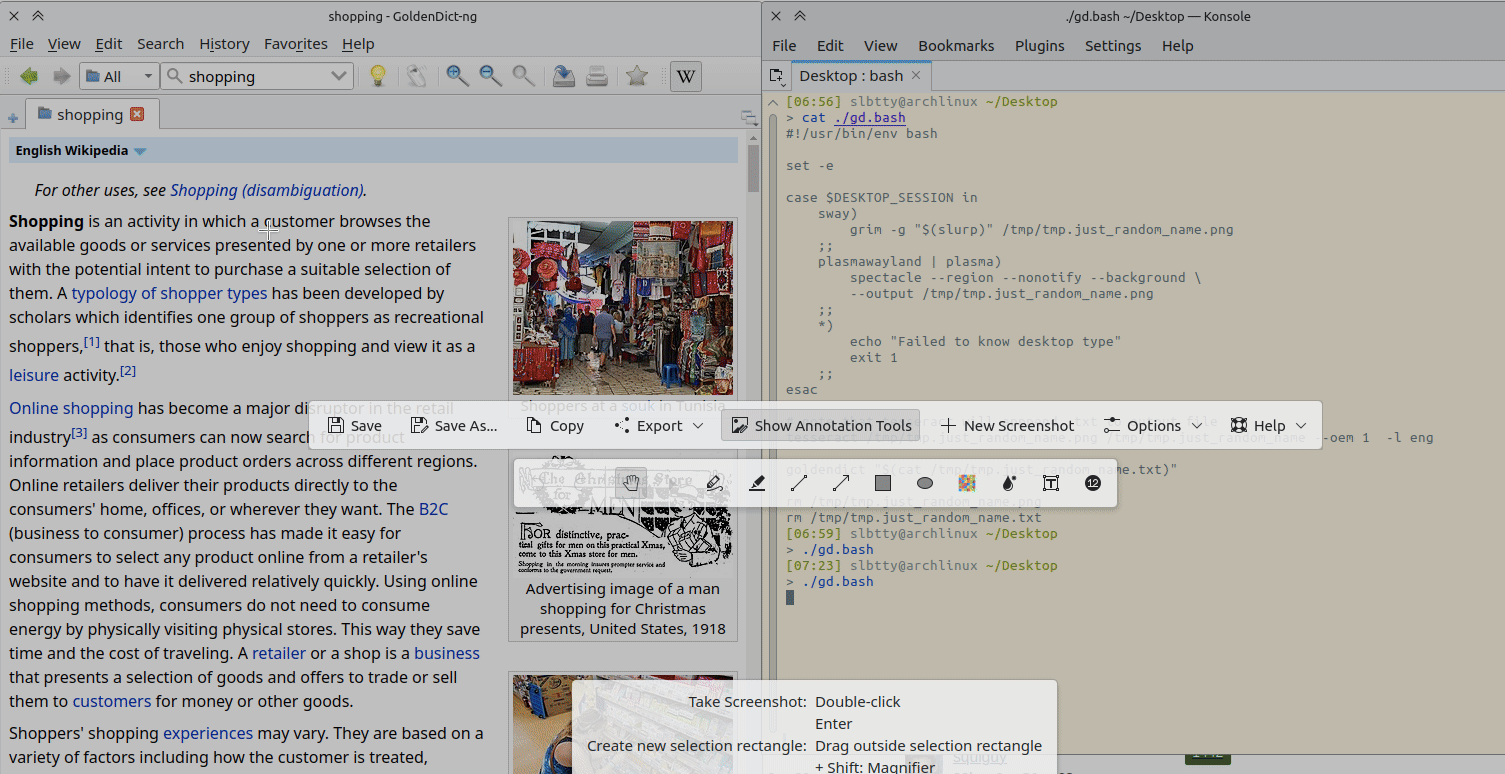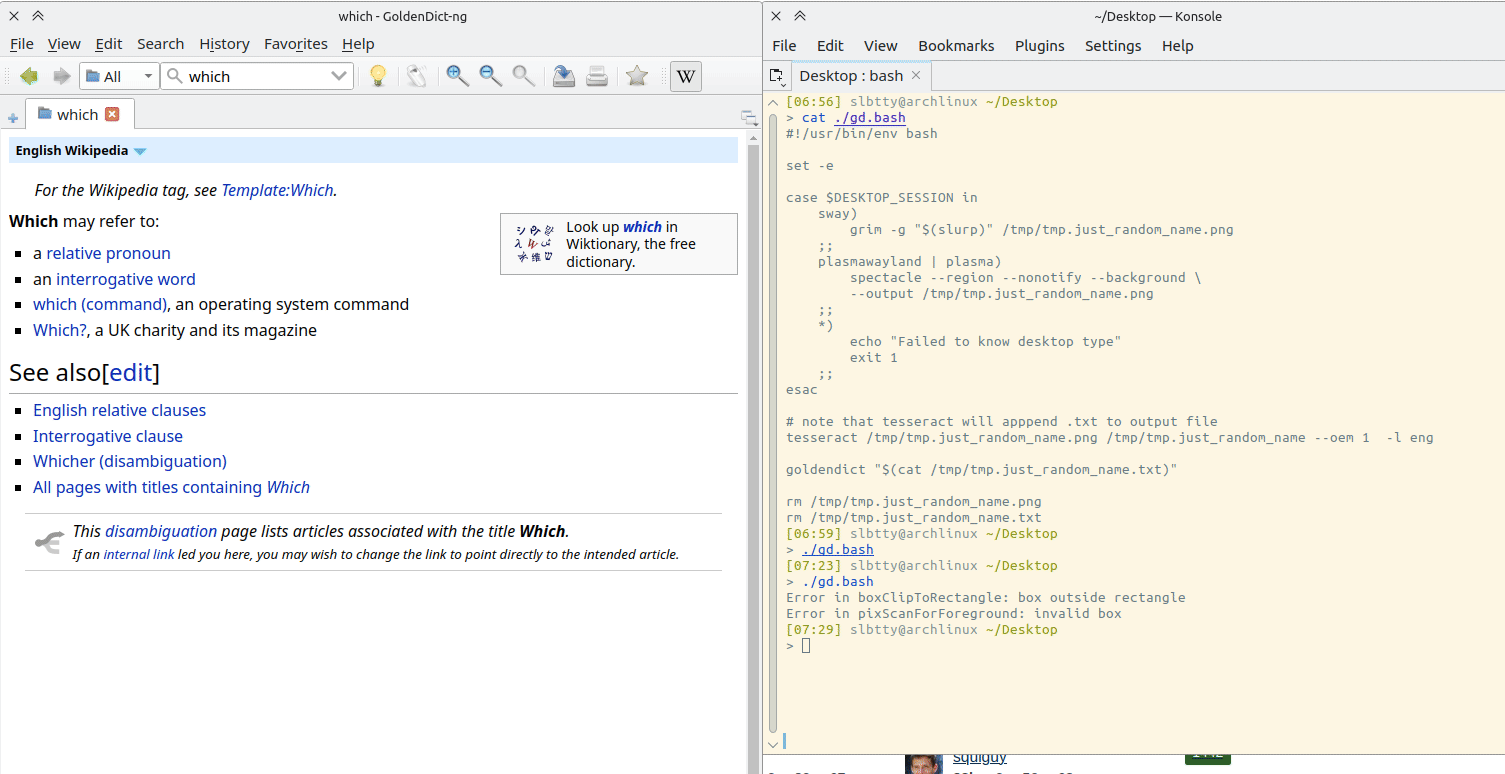
截图在 KDE 里用的是 spectacle ,Sway/wlroot 用 grim + slurp
tesseract 需要切换语言在 -l eng
#!/usr/bin/env bash
set -e
case $DESKTOP_SESSION in
sway)
grim -g "$(slurp)" /tmp/tmp.just_random_name.png
;;
plasmawayland | plasma)
spectacle --region --nonotify --background \
--output /tmp/tmp.just_random_name.png
;;
*)
echo "Failed to know desktop type"
exit 1
;;
esac
# note that tesseract will apppend .txt to output file
tesseract /tmp/tmp.just_random_name.png /tmp/tmp.just_random_name --oem 1 -l eng
goldendict "$(cat /tmp/tmp.just_random_name.txt)"
rm /tmp/tmp.just_random_name.png
rm /tmp/tmp.just_random_name.txt
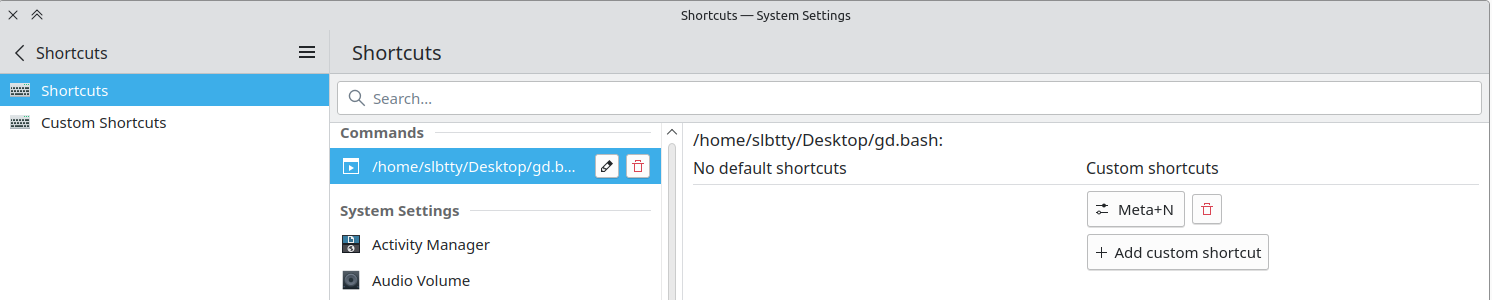
KDE 里设置全局快捷键: