GD作法等於一刀切。兼容字實際上有三類:
第一類:字形重複而棄用。平面 0 兼容區(U+F900-FAFF; 512 字碼),大約 70% 字是完全重複字形,應該棄用。(其他字形,大同小異,關鍵是這種 “小異” 不是字典一般會關注的異別,所以用不上。)
例如,豈 (F900)兼容字是淘汰字,因為完全重複 豈(8C48)標準字的字形。查 F900 時,適合跳到 8C48,畢竟是同一個字(形)。在這情況下,軟件或 mdx 提供跳轉是對的。
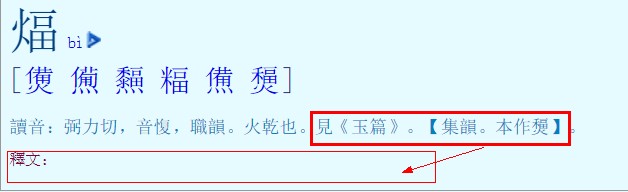
注意:平面0兼容區,其中12字,雖然在兼容區,Unicode 定為為標準字:﨎、﨏、﨑、﨓、﨔、﨟、﨡、﨣、﨤、﨧、﨨、﨩。這裡最常見的字頭是 “﨩”(FA29)。原則上,商業字型(font)應該支持。
平面0又有一群字,Unicode主張棄用,但還是適合用,而且mdx群眾用了很久了。例如:滋 xuán(FA99),收在漢語大字典、辭源、王力字典。字典分辨 滋 xuán(FA99)與 zī 滋(6ECB):字形、音義都不相同。Unicode主張棄用FA99,用 6ECB 替代,等於是把兩個字混成一個字!所以別管他是兼容字,基本道理是:與其用私有區字,寧可用兼容字。起碼,兼容字的 字形—字碼 關係是官方標準,是固定的。
第二類:字碼的字形是獨特的。 這類不要排擠,可以當做標準字一樣用。據我預算,平面2兼容區(U+2F800-2FA1F; 542 字碼)80% 是這類的。
你提的 巢(U+2F882)屬於這類。巢是巢的本字,字典既然分辨,就用 Unicode 分辨。在 Unicode Code Chart (跨區的規範字形表),2F882 與 5DE2 之間沒有任何重出的字形,分明是兩個不同字。所以如果你要的是 巢 字形,就應該用 2F882 來表現,這就是 Unicode Code Chart 的道理。

附言:給 2F882 字碼提交的 UTC-00136 字形,據說是按照大字典第一版。in any case,“UTC” 與 “T” 字形都繼承康熙字典字形。巢 也是說文小篆字形的隸定。
用兼容字才能分辨:滋 FA99、滋 6ECB、滋 2F90B。如果字典不分,兼容字就不必用。
說個玄奧的例子,說文:“成:从戊丁聲”。如果要表現這個 “丁” 部件,就用 2F8B2。


在個現代漢語字典,讓 2F8B2 跳到 6210 算了,但在說文裡,只有 2F8B2 才能表現 “从戊丁聲”。兩個字形大同小異,但大幅度的字典,像中華大字典,就在分辨這種所謂“小”異別,不得不利用兼容字。回到原來的話:與其用私有區字,寧可用兼容字。中華大字典電子版都用上私有區字,但又排擠兼容字,豈有此理!
第三類較特殊:嚴格來說,字形是重複的,但對某個地區或電腦環境來說,他當作補充。例如《通用规范汉字表》:

865C,一碼多形,在“簡體字”電腦字型會顯示 “G” 形;在“繁體字”環境會顯示 “T”:


所以,任何一個電腦字型無法並陳 G 與 T(因為兩個佔一個字碼),所以兼容字可以用來當補充。
- 在簡體字環境,“虜”的 G 形用標準字 865C 來表現;T 形用兼容字 虜(F936)來表現。
- 在繁體字環境,“T” 形用 865C 表現;“G” 形用兼容字 虜(2F9B4)。
in short, these are for situational, localized use. 等於把 Unicode 地區化了,或是說,局限於一個地區的標準。這樣有點違背 Unicode 的旨意,本來應該是個跨區的國際標準。但這樣有點不得已,為了應付 “並陳” 的需求。並陳有別的方案,但用兼容字最簡單。
總之,第二類盡量用,而且大規模的字型(例如方正中華)幾乎都支持。第三類的,看字典標準,看電腦環境。
有時平面0的兼容字,還是適合使用,但要考慮字型是否支持。例如上述的 滋 xuán(FA99),中華字型缺,反而把這字形掛在其私有區 (F6169) – 私有的是沒準,兼容字起碼有固定的 字形—字碼 標準。








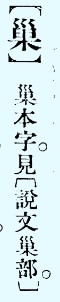




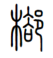 明顯从 "邑⻏”。
明顯从 "邑⻏”。
