(建议新开一贴讨论)
会处理xml的话,可以考虑一下我从PDF转成Word的原档:
英文字用法指南.7z (2.6 MB)
里面都是XML,我完全不会弄,暂时还是PDF为主、MDX为辅。。。
你的数据
三个我都试过了,至于那俩个数据问题我上面都说了。
你最后发的要友好多了。
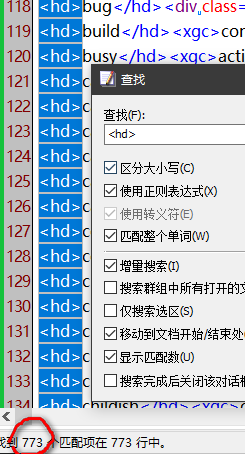
不能很快做出来(除了其他原因)问题在这,一千多的词头只抓出7百多,剩下的3百多都要手工调整(跨页数据文本后都给分开处理了)。
https://forum.freemdict.com/t/topic/1902/51?u=w2k
目前还没有讨论出最终可以完善的思路,还在试着弄。 ![]()
英文字用法指南.txt.css (3.9 MB)
試試這個
那个PDF是扫描版,文字也是ocr而来的。
不如 文字版 Все словари для ABBYY Lingvo® - Rodale's Synonym Finder (Eng-Eng) 或 https://www.amazon.com/dp/B01E67HHOE 可靠。
这本在主站不是已经有一个dsl转制的mdx吗?
FineReader 可能英文识别得好,但中文简体繁体不一样了。
可以的话开个新帖发布mdx,多一种选择总是好的,大家用的过程中可以查漏补缺。
目前觉得这里交流就好,提取的数据都有问题,目前发现的问题有的解决得了,有的根本就是体力活。新开个帖子拿不出东西来。呵呵呵!!! ![]()
目前弄得比较多的是我自己在https://convertio.co/zh/转的和 @MicroX 发的最后那个document.xml文件,Convert PDF to HTML Free Online | Xodo

@MicroX 里好多单词都这样 ![]() ,其它还好,
,其它还好,
<ken>intri<w:r><w:rPr><w:i/><w:spacing w:val=“-2”/></w:rPr><w:t>n</w:t></w:r>sic <w:r><w:rPr><w:spacing w:val=“-1”/></w:rPr><w:t>weaknes</w:t></w:r>s of design
词头缺(也没数据)
communicable
leave(2)
lurk
make
move
leave(1)就有部分数据。
你们都弄咋样了?
我自己转的。大家可以看看。错误还是很多,懒得弄了。
拆分时把类似young man,young woman这样的正则拆成单个的字了,比如young man,拆成了young和man。
052720.zip (1.7 MB)
没有把每一个字拆成单独的词条。
我只会用Python的abc.replace(‘abc’,‘xyz’) ![]() 这样…
这样…
等待完美转换内容不现实,该下一步了
可以参考
爬楼爬懵了,现在是只有w2k在弄?
分头行动中?都在等最好的转化文本再动手?
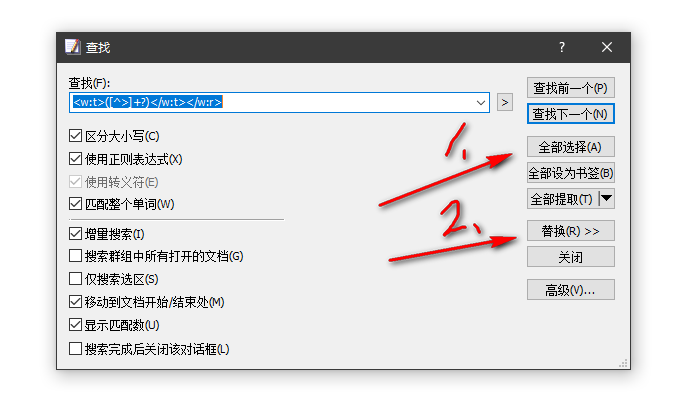
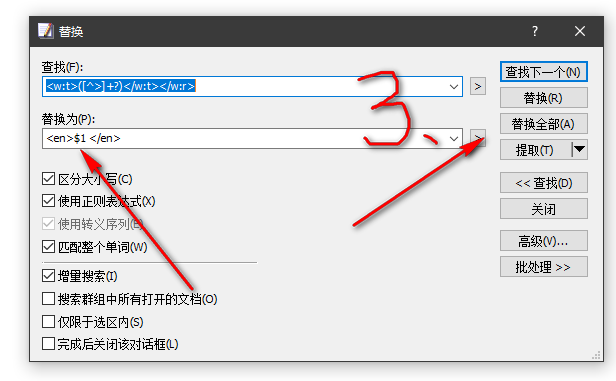
([^>]+?)查找,替换用 $1 或 \1 。
\n下一行。
emed64_16的key,不好用的话自己搜个。
DMAZM-WHY52-AX222-ZQJXN-79JXH
Regular Expression or Coding都是天书,我已放弃追随![]()
就在Office Word里面繁体转一下简体好好看、好好学习、天天向上
老哥分享下Synonym Finder?你这版本看起来挺好的