英英是不是缺 dragon 这字?
真查不到,很神奇,我回溯一下。

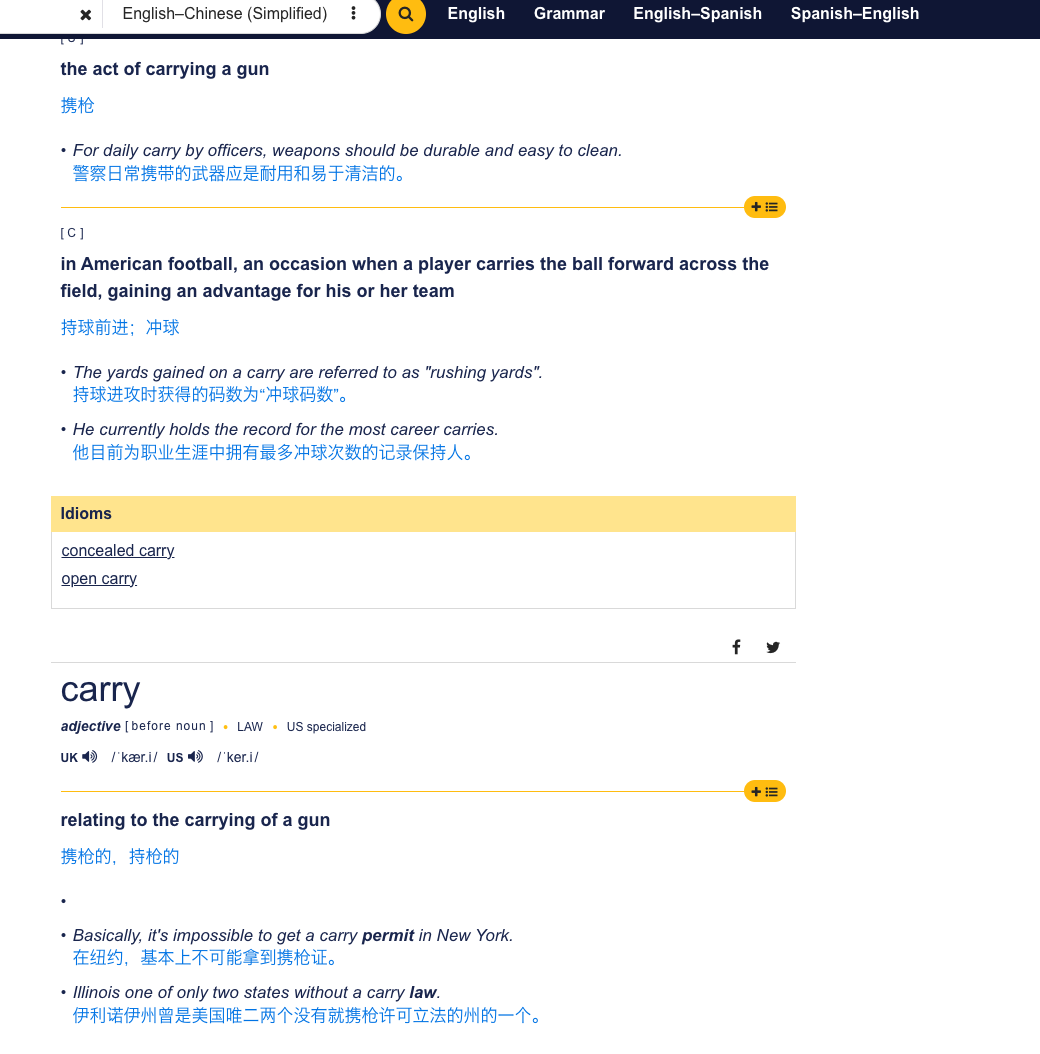
看不懂,哪里有子弹?
哦哦,由此发现,原来坛里的那个剑桥在线carry只有动词。
另外,我不想做下去,既没有能力,也用不上。但开了头,接连不断的问题逼着不得不搞下去……
那就用旧的嘛,一味地求新反而容易适得其反。
多谢理解!已经要晕了。因为21#的提醒,发现了一些问题:
以为改了就ok了,谁知编译后发现还是少了一条,少哪条呢?哪个地方出问题先不管了,先找出来再说。那把词头提取出来与官网词表比对一下不就知道了,谁知一比对,吓了一跳,对不齐的有几百条。
浏览一下,原因大概有两个:
一、官方词表把idiom和phrase直接加在了词条后面,所以连同一楼的比对和替换表都得更新;
二、还是用bs4提取词头的问题。因为英英版包含了几部词典,所以标签结构比较复杂,一般正则不易提取,只得用bs4,也许是分析存在问题,更可能是网页标签存在问题,所以某些词头提取出现问题。
上面说的都是英英,英汉应该没啥问题,如果没人做,我有空可能会处理链接、删除冗余、增加js。英英不打算弄了,包括数据,至少暂时不再弄了,先把目前已知的问题上传,希望有高人接盘。
感谢!!但是我个人觉得在楼主提供的版本中把字号改小一点就可以了,当然“更多例句”可以收起来就更好了 ![]()
英汉与英英的比对结果也富于戏剧效果,比如英汉比英英竟然多出个a,难道英英没a?mdx查不到,在线却能查到,原来词头变成了A, a;再如英汉多出个zoom in on sth,原来英英中是zoom in on something;your own flesh and blood在英英原来是 someone’s (own) flesh and blood:数据格式不统一给数据处理带来很大麻烦。
折叠不方便全文搜索
对照英版,并无缺漏,只是多了占位符,此类情况有十几处,已修。

深蓝词典英英词典也不显示图片
图片没有补全绝对路径,默认不显示
请问怎么补全呢?
Can anyone make and share Cambridge Thesaurus and collocations dictionary in separate mdx? Thanks
鸿篇巨制!老师辛苦了!!!
官网显示英中不是半双语词典了