一:元信息
一甲:帖
- 如何在topic中创建TOC的指南,文章右侧有目录,显示了在文章中距离较远的目录,强调了分类高层紧密的上下关系和并列关系
- 标题的OODDEE,为了减少曝光度,与原帖一致
- 为什么不在原帖更新
- 我水平有限,对JS的理解需要很长过程,没法直接在原帖给出结果。所以要作为长期更新、修改的帖子。
- 为了隔离内容,专一主题的处理,不想混淆于原帖的各种信息。
- 为什么不用123而用甲子? 因为123有序数和数量的一词多义,这里只需要名字标记不同点不同层级、不需数量混进来。
一乙:.js 文件
- 网站不准上传 .js 文件,故在 .js 文件加了 txt 后缀。
- online 版的 common.js.txt (163.4 KB)
- 基于此的 MDX中的 ode.js.txt (167.0 KB)
一丙:术语缩写
跟代词一样,只不过自定义的代词,方便写作,不利于阅读(非通用规范的代词)
- 总分:时分、境分
- 主次、需与不需、唯一的必要和多种的可选、多种的可选与更具体的每个的有无不选(最大的权限、自由)
- 抽象具体:以共性为统领的一对多的嵌套形成的信息抽象树。与之有关的同异、略术、数等,再结合相对分还是相对全局,有条件无条件,依赖数量(是上一条的需要的反向关系命名)
- 文义意:涉及文字、人、人的意图、文字的释义等元素;文表示义、义反映文、义暗含意等多个单向、双向关系,不区分易造成一词多义、一义多词的关系残缺、对应物错误。
二:具体分析
由于上面给出了基本元素,和以下的对应关系(各文,文的义,义再加惯用、修辞而表现的意)请对号入座尝试比较即可试出,不再赘述。(这里有地方未使用标准的标点符号国标GB,是因为其表达力太弱)
二甲:common.js
二甲子:总。共1959行,不考虑字数
- 但有的行仅仅是乱码注释,非常短;有的一行是压缩代码,很长的一行,如一行2000字。除非特别长的要提醒注意,一般能翻页的不再记录。
- 有的功能是网站的,可借鉴用以开发新MDX的功能,但非本文主要解决的MDX 例句展开例句无效的问题,所以带分类标记(可删用于MDX,摘要用于新功能)。
- 对于压缩代码,VSCode 默认 formatter 不够用,需插件 Prettier-Standard - JavaScript formatter
二甲丑:分。
L:line
L1-8 可删,长代码 => 引入 jQuery 压缩的源码,用以作扩展、自定义新功能、直接从现有lib加工更快。
L9-314 可删 => 用以自动补全、选择、修改、实时推荐用户的查词时的输入。
摘要
- 可以用这个接口把爬下来专门做个索引词典,用以解决查到显示之间的问题。不过GoldenDict己经做了最主要的实时搜索功能,其他推荐词条用的少,砍掉。
- 开发新功能:形近模糊搜索。e.g. 11个字母错一个也能推荐出最接近的10个字母、9个字母相同的单词,按相似度排列
- 还可以对字母和音标的对应关系,进而从对输入错误的单词推荐出
- GoldenDict己经做了,但不好用,e.g. fundemental 就没有提示)
- ODE online 做了这个功能,fundemental 就提示 fundamental
- 404页面应该不是提示找不到,而是提供办法怎么样才能找到
- 用中文搜
- 用相近词搜
- 听音辨词
L315-326 可删,长代码 => 重写了 jQuery 的 cookie 帐户过期相关代码
L327-330 可删,长代码 => 输入密码、单方时的占位符功能
L331-403 可删,在输入框左侧,选择在哪一本词典中搜索单词。
L404-456 可删,响应式布局。电脑、平板和手机因为尺寸不同而页面布局不同。分了3档。
L457-467 存疑,长代码。css 样式的 Bootstrap tooltip组件的,用来显示信息提醒。不会有数据是用css才显示的情况吧。。试了下官网,好像没啥用。就几个没啥用的提示,但就试了几个词,可能不全面。
L468-470 存疑,jQuery 弹窗功能? 例句是用这个弓单得吗?
L471-482 存疑,单选有关的代码。问题是有关词典数据的js片段,会不会因为删了片段就不显示词典数据了呢? 难道还要细看代码内容逻辑,学jQuery…词典的数据是有限的,但掺杂了js的各种考虑的功能,全混一起了,没有文档好难整理。
L483-524 存疑,叹号和safari的某个bug的补丁。用在哪里呢!!!!
L525-575 可删,视觉增强的丝滑滑动,非数据相关。
L576-640 可删,菜单相关
L641-654 可删,radio 图片,哪里的?
L655-947 可删,俄语、阿拉伯语支持。
L948-1294 可删,初始化,语言判断、自动补全、自动选词典。
L1295 找到 例句点击操作绑定的函数,需要看jQuery的$和ga函数等的实现和MDX中实际所需的函数……
// more exemples links
$(".moreInformationExemples").click(function(){
ga('send', 'event', 'example', pageDictCode, entryId);
var link = $(this);
var panel = link.nextAll(".sentence_dictionary");
moreInformationLinkClick(link, panel);
});
Lxxxx-1641 可删,一堆网站的边角功能
L1641-1695 存疑,大小写和强调的处理。
todo:
L1696-
L1795 例句发音,需要企业级商业密钥,听起来还没微软的像人。
L1847 单词发音? 需要结合HTML验证。
L1946 cookie相关
暂时处理到这一层,我还得补js,希望有助于其他朋友处理这个词典的 js。
自己搞砸了
- 小号忘密码
- 而匿名的草稿编辑中第二天会自动换帐号内容就丢了

那以后写一点传一点不存草稿了,不求在 topic 主楼用目录结构化文字的方便阅读了,先保证信息不丢。
- 解码 mdx → txt
- github 里 搜索 mdict-utils,自带说明
- 2GB 大小的 txt → blue 词条内容单拿出来分析
- grep
- 是 Global Regular Expression Print 的缩写。个人理解是 run Global Regular Expression then Print 或 and Print。为什么记录,加强一遍,以及有文章介绍但更多文章没有提到,强行塞入我脑一个单词,我不胜惶恐。
- 为什么用 grep ? 百度 “linux 支持正则 文本” 而来、好像是一堆方案中最普遍自带少折腾环境、简单低学习成本的一个。
- RE pattern (抽象规定其未知的位置)是:‘^blue$’
- 已知的部分就是文字 blue ,目标是其相关内容,不知的是其位置,位置的特点是仅需要它单独作为一行的位置,不需要blue在其他位置的内容,因为mdx的约定协议是词头单独一行,保证了区分的准确。
- 数量可能多个,都要提取。(不过 grep的g就是 Global 的缩写,默认应该是显示所有结果的)
- 内容是这个正则的下一行(压缩成一行的HTML会卡顿,利于数据处理、不利于查词的速度、感观)
- 由于人类对A和a经常视作表示一物的不同符号,而GoldenDict会通搜,为模拟一致,要 -i ignore-case
- 可能GoldenDict还做了其他加dash -的处理,再结合HTML的实际内容再处理,先想这么多
- 搜索百度:
- grep 下一行 →
- grep -A 1 (After-content的缩写)
- 好像还有其他子表达式的方法,更通用、不过不够简单,我先找找有没有已经提供好的
- grep 的 re 和 文件的命令格式风格? →
- 直接搜索太杂内容
- 其特点是最基本的,所以直接看教程的开始例子,比如:https://m.runoob.com/linux/linux-comm-grep.html
- 没有严格精确的找到,但类似的可以尝试下,尝试失败,再次搜索
- 一个帖子没找到,尝试 grep --help,找到简单方案“-e” 尝试失败,好吧,我得读读书,原因有
- 网文结构比较不全、不准,可以借鉴思路。
- 可能有好帖,筛选成本高,百度差评(不过它的翻译比其他好,尤其德文),换bing
-
- 开始排查,删去拿不准没使用验证过的一半命令。从
grep -A 1 -E "^blue$" ODE2022V4.mdx.txt >> tmp.txt,删减成grep -i -E "blue" ODE2022V4.mdx.txt >> tmp.txt
- 参数删一半
- re 删一半
- 结果有200M的文本数据了,说明
-i -E 没问题,E是Extended re; 文件位置、加的双引号也没问题。
- 再加上一半的参数
-A 1,结果有数据了,说明出在行首行尾这个问题上,怎么会有问题呢?
- 调整参数顺序,没问题。
- 先整理到这,因为我突然想起来,mdict 好像 可以 直接提取出相关词条,人家已经做好了,目标已达成,工具的修炼先放一边,所以 grep 只作记录到这。
-q query word mydict.mdx
mdict -q blue ODE2022V4.mdx >> temp.html
含有重定向到 blues,也提取出来。
重排版HTML。
依赖有
- css
- 查找css时,删掉刚刚不用的测试文件,减少负担。
- 但凡有对文件有改动,先复制为副本再改动,理想是用脚本控制、记录所有行为,不过已经记录为帖子了,而且处于尝试阶段,先方便着来。
原始问题、事件的时间顺序不一定是解决问题的顺序。把最最后直接的mdx里的html代码反而放到最后看了,结果需要的内容,需要改的地方的 mp3 地址和例句都是现成的内容,官网的js一大堆,没看到主要用的功能,有几千行可能会有用的功能代码也混淆加密了,暂时没得办法。
索性重写个 js 先试试吧。
正好图片形式的信息实现了不利于检索,尊重原帖的用意,一致。
js 的绑定变量时,其组成部分的声明和传值分开,悄悄只提升声明部分的顺序。
所以为了方便,用新的 let 变量。但第二次时不能覆盖,那就再加个大括号,隔离开第一次第二次。
初始化为"" string 只是为了和"ode1"不一致性,不在于其自身是哪个字符。
有时候并不需要载入html就运行javascript,而是用户点击了HTML某个对象,触发了一个事件,才需要调用javascript。这个时候通常将这样的javascript放到html<的head>里。——来自百度
js先于HTML运行? 可是 head里的怎么也执行了。。
要在运行的时候给每个例句加onclick 事件,需要例句事先存在,所以
- mdx.txt 要做改动,把js置于body最后
- 顺道 mp3 的标签和属性批量 改成默认的 a href file://,这样直接点击软件会自动处理成播放,而不用 audio
- 或者js里判断等待html加载完,好,搜到一个 window.onload 的原先支持
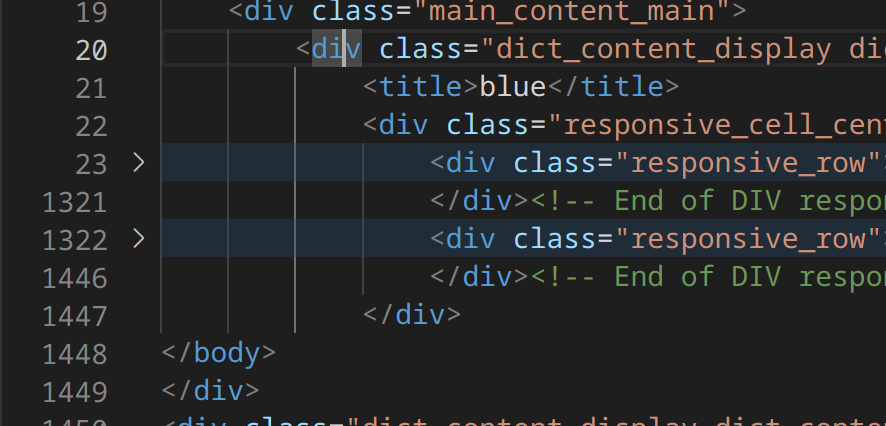
标签 /div 应该在 /body 之前的现在跑到后面了。
我的老上帝,因为这俩标签有问题,所以反而被忽略了,反而剩下内容是这个 main_content_main的子标签。。。。这用bug写feature!
todo:
/*
1. 展开折叠switch func
a () {
}
2. 把这个 func 绑到所有 moreExam, syn 等
3. 切换词典的功能之后都要触发一次绑定。
4. 需要事后 HTML onload 后才能初始化 js 的绑定
1. 有需要事后才能确定的,也就有事先就能确定的。
2. 比如抽象不知的是内容是,以已知其部分模式,做成另一个func,隔离开已知未知。
3. 这一步是为了速度,五六个词典一块添加事件,太卡了,应该只渲染当下选择的词典。
5. 词典ode.js 多次加载的问题
1. 隔离 直接用大括号
2. 判断隔离,直接用if自带的大括号
3. window onload
*/
// 防止多个ode.js加载时,上下代码重复,隔离开
// 那么为什么要运行多个呢?最后一个HTML渲染完, on load 再绑定事件不行吗
// onclick 和 js 手动绑的顺序呢?
// onClick绑定js时需要其调用的另一个func已存在吗?
{
// console.log("isJsAtStart");
// onload 绑定的事件,不仅是自个代码加载完、HTML加载+渲染完,这还不够,在所有同词头的多个映射内容加载完才开始执行
function ode2022v4_clickToDisplaySwitch() {
console.log(this);
}
window.onload = function() {
// 先完成搞个能用的,以后再速度的优化
// 先抽象跑通,再细化各环节(目的的优先队列),想到细节时只做记录,不立刻做实现,先做必要的,再选可选的改进。
// 记录:
// 词源中的 more, 例句中的 More example sentences 和 Example sentences 名不一样,关键的内部结构一样;
// 同义词是 div.entrySynList
// 鼠标移上去的小手是因为 a tag自带的click,而非js绑定的click.
// 点击 a 标签,触发 其young sister 的 display.
// 2例句+1词源:a.moreInformationExemples => ul.sentence_dictionary
// 同义词: a.moreInformationSynonyms => div.entrySynList
let ode2022v4_nodesToBindEventClass1 = document.getElementsByClassName("moreInformationExamples")
// .getElementsByTagName("a");
console.log("ode2022v4_nodesToBindEventClass1");
console.log(ode2022v4_nodesToBindEventClass1);
// 两者顺序换一下,简单提速
// 提速代码,日后完善
// 开始只绑定必要的当下词典,切换才加载其他词典的事件,或者加载完当前词典后幕后再加载绑定。
// 重复加载 ode.js 时如何避免对已有的click 再次进行 绑定。
// 不优化的话,take 这种词就会一个词典200个事件,6个词典 就是1000多个,重复六次,就是1+2+3+4+5+6 共21×1000 = 2万个事件。
// onload 没有解决重复问题,只解决了js先加载于HTML前无法找到HTML的问题
// let ode2022v4_dictsNav = document.getElementsByTagName("javascript_tittle_box")[0];
// console.log(ode2022v4_dictsNav);
// let ode2022v4_dicts = ode2022v4_dictsNav.nextSibling.nextSibling.childNodes;
// console.log(ode2022v4_dicts);
// let ode2022v4_dictsLength = ode2022v4_dicts.length;
// let ode2022v4_curDictK = -1;
// for (let i=0; i<ode2022v4_dictsLength; ++i) {
// console.log("in for");
// console.log(i);
// console.log(ode2022v4_dicts[i].style.display);
// if (ode2022v4_dicts[i].style.display == 'block') {
// ode2022v4_curDictK = i;
// break;
// }
// }
// console.log(ode2022v4_curDictK);
// console.log("isJsInAtLoadEnd");
}
// console.log("isJsAtEnd");
}
// 理解注释。一会在前一会在后?
// 在前的更抽象,用于分类子内容;在后的更具体,用于解释父内容。
// 还可能是原始顺序时提示。
// 还可能已发挥完作用的注释
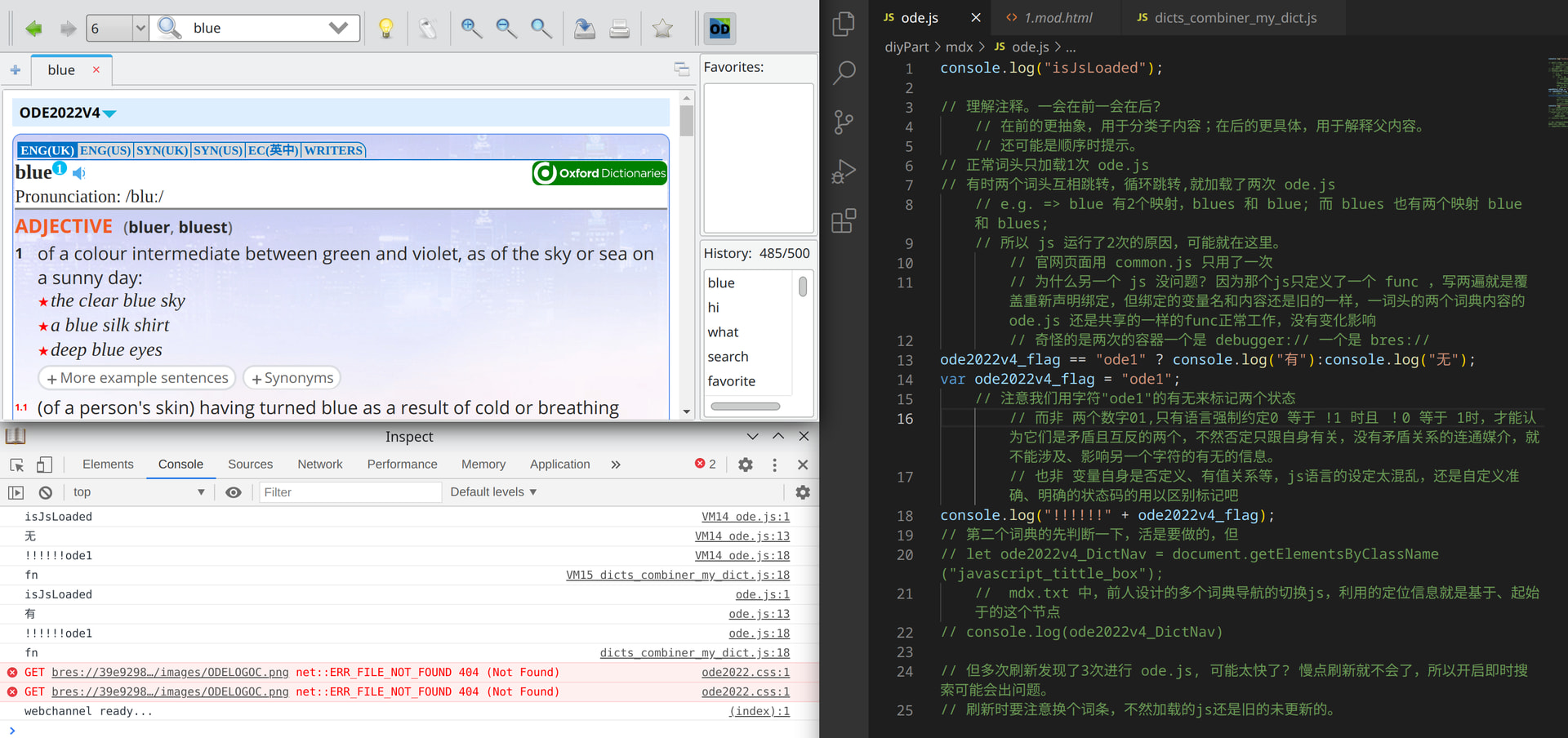
// 正常词头只加载1次 ode.js
// 有时两个词头互相跳转,循环跳转,就加载了两次 ode.js
// e.g. => blue 有2个映射,blues 和 blue; 而 blues 也有两个映射 blue 和 blues;
// 所以 js 运行了2次的原因,可能就在这里。
// 官网页面用 common.js 只用了一次
// 为什么另一个 js 没问题? 因为那个js只定义了一个 func ,写两遍就是覆盖重新声明绑定,但绑定的变量名和内容还是旧的一样,一词头的两个词典内容的ode.js 还是共享的一样的func正常工作,没有变化影响
// 奇怪的是两次的容器一个是 debugger:// 一个是 bres://
// 注意我们用字符"ode1"的有无来标记两个状态
// 而非 两个数字01,只有语言强制约定0 等于 !1 时且 !0 等于 1时,才能认为它们是矛盾且互反的两个,不然否定只跟自身有关,没有矛盾关系的连通媒介,就不能涉及、影响另一个字符的有无的信息。
// 也非 变量自身是否定义、有值关系等,js语言的设定太混乱,还是自定义准确、明确的状态码的用以区别标记吧
// 第二个词典的先判断一下,活是要做的,但
//
// mdx.txt 中,前人设计的多个词典导航的切换js,利用的定位信息就是基于、起始于的这个节点
// console.log(ode2022v4_DictNav)
// 但多次刷新发现了3次进行 ode.js, 可能太快了? 慢点刷新就不会了,所以开启即时搜索可能会出问题。
// 刷新时要注意换个词条,不然加载的js还是旧的未更新的。
toBeFinished
/*
1. js 找不到 html 进行绑定
推测原因: html中,js 定义于 词典的节点 前,所以默认运行顺序也是此序。js 已经 0->1 时,html还是 0->0
办法之一: windows.onload = func1(){}
原理: 绑定这个事件后,html 加载且渲染完后才运行 func1,而且是该词条对应的 自身内容 和 @@@LINK指向的其他词条内容 对应的 html 代码全部 加载完 才会运行 func1。
2. ode.js 多次运行
推测原因: 搜索一词,自身 html 内容 和 @@@LINK 指向的其他词的内容 会在不同时间运行多次这同一个 ode.js 文件
办法之一: 新建变量判断以示区别,判断未定义变量用 typeof
*/
/*
typeof test
console.log("{ typeof test ")
if (typeof ode2022v4_isOdeJsLoaded === "undefined") {
console.log("f : 0")
let ode2022v4_isOdeJsLoaded = 1;
if (typeof ode2022v4_isOdeJsLoaded === "undefined") {
console.log("f2 : 0")
} else {
console.log("f2 : 1")
}
} else {
console.log("f : 1")
ode2022v4_isOdeJsLoaded = ode2022v4_isOdeJsLoaded +1;
}
console.log("typeof test }")
*/
/*
其不存在知道bool值了,那存在呢? 法跟存在时的值无关,其他就更不操心了。
1. 不能用 !==、!typeof,必定不同。
2. !变量,此时变量不存在,typeof 可以这么干,toBool 不行
3. 其他包括 === !==是怎么比较的 ,不知道其实现是
1. 各自转成bool值再比较
2. 还是类型相同再比较值,0和1值都是obj,都是true。
3. 我能不能自定义它们toBool的值是随机变化的,所以依赖
1. toBool,=== !== 的实现是怎样的
4. 各种可能取最可能的猜,即
1. === !== 是先两边toBool,后对比
2.
*/
console.log("\n{ ode.js test ");
/*
这里只用 ode2022v4_isOdeJsLoaded 一词多用
1. 与typeof 时,仅代表不同状态,是 undefined 或 非undefined(那么多非undefined,为什么选number,因为数字有其他用处。) 来判断其是否已存在
1. 不代表自身矛盾即 !ode2022v4_isOdeJsLoaded 没有意义,不用这个信息
2. 自身值的变化时又是数字起作用,和名字 isOde... 有冲突,不改了。。。
*/
if (typeof ode2022v4_isOdeJsLoaded === "undefined") {
console.log("flagBranch flag undefined");
// 想要突破{},可以用 var,var虽然差,但不同的地方就有优点
// 而且 var 还速度快,话说谁差呢。
// let ode2022v4_isOdeJsLoaded = 1;
var ode2022v4_isOdeJsLoaded = 0;
// 声明提升,但值是undefined, 绑值为0 的操作仍在原地定义。
// 所以 ode.js 执行entries.length个,声明就执行了多少次
// 那怎么换个突破法共享变量呢? 或者换个法共享信息呢?
// 不管了,反正是空变量没内容,重复也消耗不大。
console.log("I'm entries[" + ode2022v4_isOdeJsLoaded +"]");
// dicts switch
console.log('I\'m a switch of dicts.')
function js_display (s, num) {
console.log('js_display start')
// 需要插入一个每次顶部导航的切换都绑定一遍例句事件
// 多个词典内容组
var contents = s.parentNode.nextSibling.nextSibling.childNodes
// 多个词典在顶部的多个导航按钮组
var titles = s.parentNode.childNodes
for (var i = 0; i < contents.length; i++) {
contents[i].style.display = 'none'
titles[i].style.background = '#DBDBDB'
titles[i].style.color = '#0072c6'
}
titles[num].style.background = '#0072c6'
titles[num].style.color = '#FFFFFF'
contents[num].style.display = 'block'
console.log('I\'m dicts switch' + "[" + num +"].")
}
// binding
} else {
console.log("flagBranch flag existed");
ode2022v4_isOdeJsLoaded = ode2022v4_isOdeJsLoaded +1;
console.log("I'm entries[" + ode2022v4_isOdeJsLoaded +"]");
}
console.log("ode.js test }");
搜索+尝试的推进太慢,看了下书,应该早看的
上面说的推理猜测有很多问题,比如var 只能突破非func 的大括号,判断加载信息用tpeof和window onload 的函数绑定的 func 作用域不兼容,可以通过BOM中的window hasProperty. 等
不过主要问题就是一形查到多词时,ode.js 就会多次加载运行,,所以造成混乱。js书说声明判定是反模式。。竟然不说办法。
需要熟悉那几个获取节点搜索的方法,属性值的获取和个API,以及音频audio标签的动态添加。就这么几个逻辑,但是要从js提供的方法来,就得受它约束,顺序、次数,callBack的语法,判断方法是什么等,结构化阅读伸缩自如的找到所需一直是我的重大缺点。因为目录的分类并不是严格分隔,所以需要的某个特性散落各处,而且有的问题应该改动HTML,而改动数据理想情况用raku加sql处理以方便文本处理和文本数据完整非破坏性,或全部pl/sql化以保证数据的完整任意回退的低成本而学习成本增加,或者考虑个人效率而只采用python方便抓取重新处理在线数据,或者只采用JS 方便mdx的功能使用和速度优化。附,爬取可以只用默认的js,内存中处理文本,再加文件下载的方式,而不必用node.js的API和额外学习成本,反正不用多效率。JS all!
显然我的垃圾学习能力目前hold不了这几个东西,python是为了方便抓取但引入语言差异的临时记忆负担,还可以选择学习网络模型基本api用node js自已搭建爬虫存储验证登陆操作,这样mdx的html处理也可以用js, 额外功能也可以用js。看那个成本更高点,以后更通用。显然是学习网络更通用,而现有目标是考虑已有html的全部不能改动而由js控制其数据,不知道怎么用js控制js之后的html数据的加载,比如删去后面entry的script标签,而控制其html的其他内容的显示。读书读文档读google! 
应该有坛友一下就写出来了,可能照顾我感受没发出来
客观借口可以有好多,头疼睡觉看书慢理解差js本身设计奇特点意向不到多,我改了好几版的尝试方向都错了。
我受您的2022 2021帮助良多,我今天不睡觉也会给您一个交代。
 不急,不考虑发音问题,JS 我精简一半了 你不用考虑发音问题 只管打开收缩就行
不急,不考虑发音问题,JS 我精简一半了 你不用考虑发音问题 只管打开收缩就行
window.onload = () => {
let nodesNeedClickExa = document.querySelectorAll("a.moreInformationExemples")
let nodesNeedClickSyn = document.querySelectorAll("a.moreInformationSynonyms")
let nodesNeedClickExaAndSyn = [nodesNeedClickExa, nodesNeedClickSyn]
for (let nodesNeedClickExaOrSyn of nodesNeedClickExaAndSyn) {
for(let aNodeNeedClick of nodesNeedClickExaOrSyn) {
let aNodeNeedExpand = aNodeNeedClick.nextElementSibling
let aNodeIsExpand = false
aNodeNeedClick.addEventListener('click', (event) => {
aNodeNeedExpand.style.display = aNodeIsExpand ? "none" : "block"
aNodeIsExpand = !aNodeIsExpand
})
}
}
}