这节课讲了 if 语句 和 while 语句
有什么不懂的欢迎提问~
这节课讲了 if 语句 和 while 语句
有什么不懂的欢迎提问~
雖然看不到視頻,還是支持一下!
老大,YouTube上的视频已经认真看了好几遍,讲得很精彩,一下就有开窍的感觉,接下来啥时还有更新啊? ![]()
![]()
![]()
有什么不懂的,给我说就行,针对性更新。甚至可以 zoom 之类的给你讲。
老大,可以开通B站课程吗
主要想请教一下,比如有的网站的单词并不是按照数字来排序的,这种情况怎么办?需要按照单词列表吗?如何用python处理?另外,假如下载了好多的html文件,怎么用python把这些文件合并起来?谢谢! ![]()
![]()
需要找到对应网站的单词表。有实例的话我比较好讲
不,那儿要实名。
求教只有右边单词前后索引的小列表,没有完整a-z索引的词典该如何抓取?比如wordreference里面的thesaurus就是只有前后临近单词的列表,没有总索引,这类该如何抓取呢
看到视频有讲,明白原理,但是自己操作还是有些困难。
老大,经过几天摸索,已经学会下载单词页面并合并成txt文件了,但是词典页面的发音文件怎么下载呢?还望老大指点一二!!! ![]()
![]()
![]()
你得说是哪个词典(网页)呀。。
就是你举例子的那个啊,下载音频各个网站方法不应该都是一样的吗?
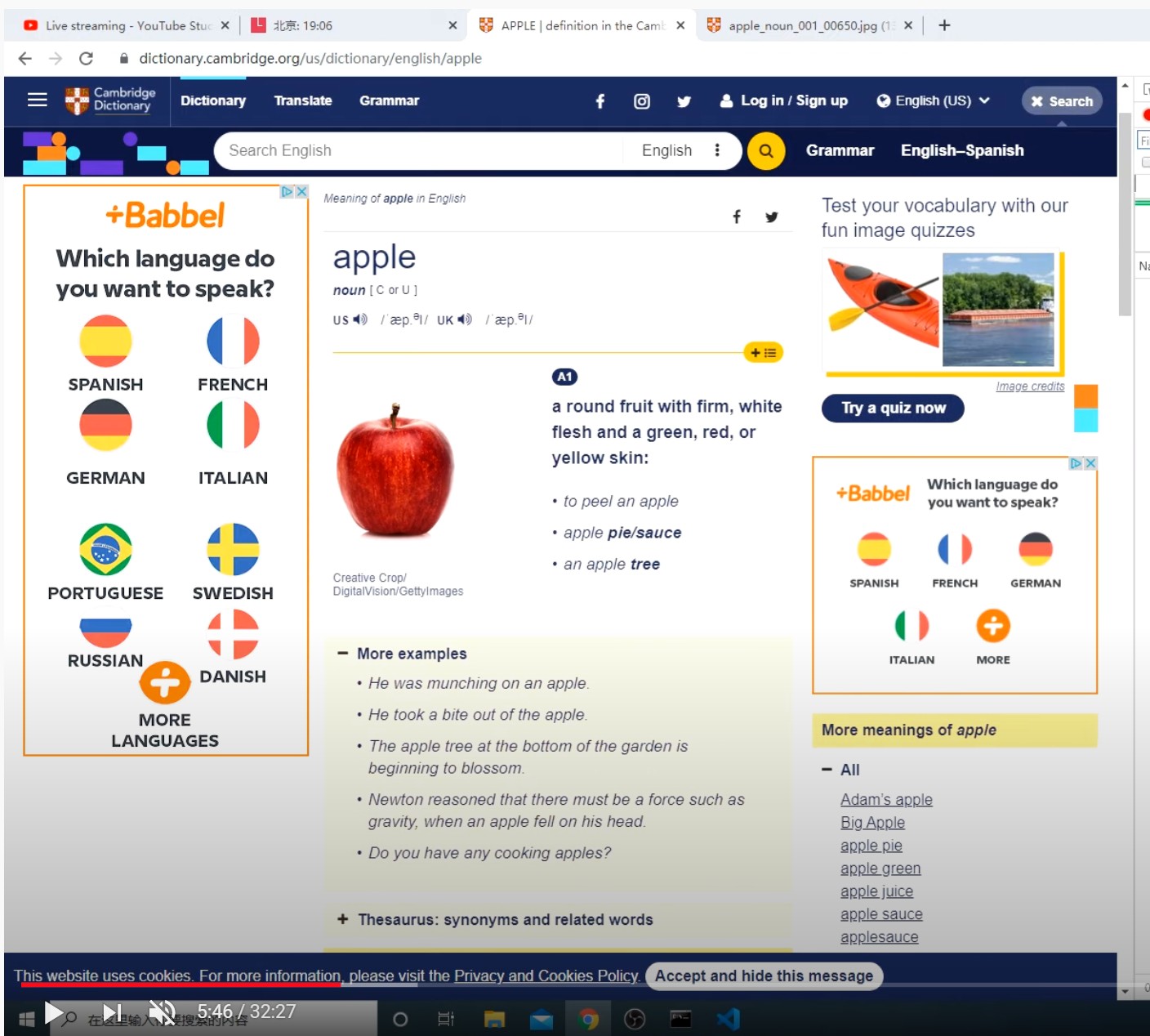
就是这个例子:APPLE | definition in the Cambridge English Dictionary, 你只讲了怎么下载网页,没说怎么下载音频啊,就是apple的发音,能否在讲解一二?感谢!
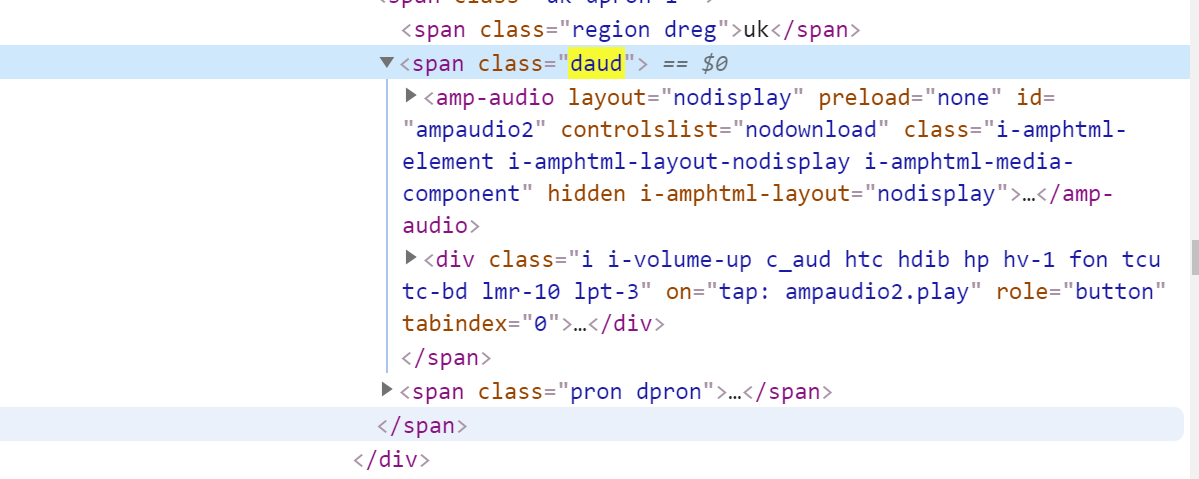
首先找到 span class=“daud”
再找到 这个里面的 amp-audio 标签
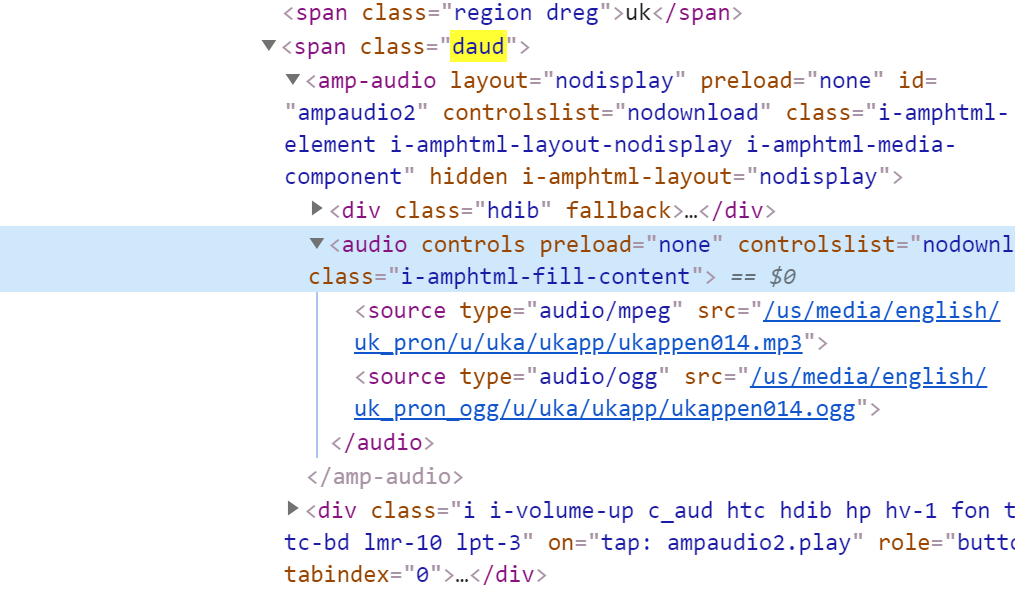
再找到 amp-audio 标签里面的 audio 标签
两种格式的 链接就在这个 src 里面。
<audio controls="" preload="none" controlslist="nodownload" class="i-amphtml-fill-content">
<source type="audio/mpeg" src="/us/media/english/uk_pron/u/uka/ukapp/ukappen014.mp3">
<source type="audio/ogg" src="/us/media/english/uk_pron_ogg/u/uka/ukapp/ukappen014.ogg">
</audio>
然后 需要拼接一下完整的链接。
/us/media/english/uk_pron/u/uka/ukapp/ukappen014.mp3
拼接成
https://dictionary.cambridge.org/us/media/english/us_pron/a/app/apple/apple.mp3
另外python下载这种音频文件
import requests
url = 'https://dictionary.cambridge.org/us/media/english/us_pron/a/app/apple/apple.mp3'
file_path = url.split('/')[-1]
with open(file_path, 'wb') as f:
f.write(requests.get(url).content)
明白了,胜过自己摸索好多天啊,多谢老大!!!感觉自己距离学会不远了!! ![]()
![]()
![]()
问题越学越多啦,还需要学习:代理池,断点续传,爬虫框架等等。。。。。