网上一搜遍地都是 [\u4E00-\u9FA5]
但是在EmEditor和NotePad++ 里用它一搜,连英文字符也搜出来了呢?
3 个赞
我用 VS Code 是能区分中文的,说明正则应该没问题。会不会是因为文件使用的字符集不是 unicode。
3 个赞
就是utf-8的啊。 用JavaScript编程使用这个正则的确没问题能区分出中文,但一放到编辑器EmEditor和NotePad++ 里用它一搜,连英文字符也搜出来了。
在EmEditor里这个确实不好用。可以用别的方式。
在EmEditor中好像使用[一-鿆]来匹配汉字好用,[一-鿆]+用来匹配多个汉字。
用9FFF换掉9FA5试试
![]() ?
?
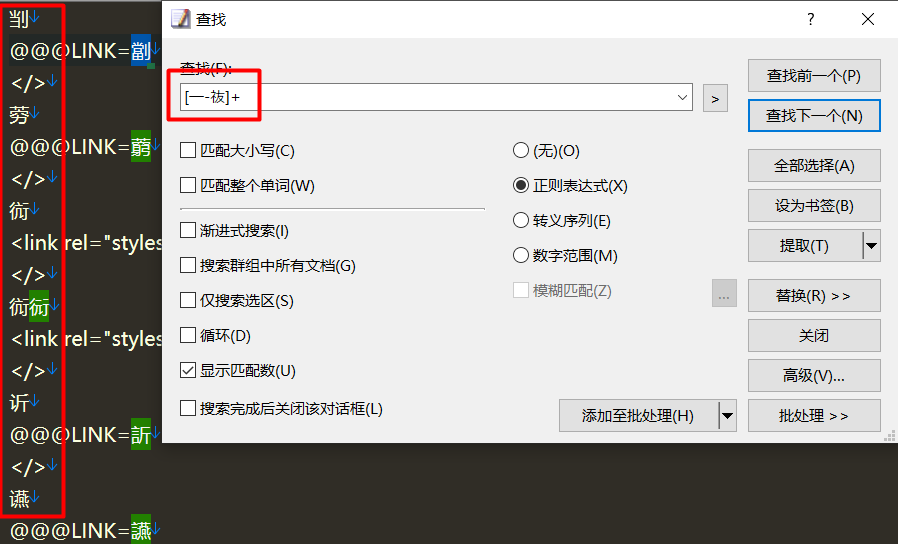
你这个可以根据位置写正则表达式。可以根据LINK=标志和</> 这些位置标志去写。这样很容易选定所有的汉字。
Emeditor汉字匹配
注意:重要一个,正则表达式引擎修改为:Onigmo。
基本汉字 [\x{3007}\x{4e00}-\x{9fff}]
扩展A区 [\x{3400}-\x{4DBF}]
扩展B区 [\x{20000}-\x{2A6DF}]
扩展C区 [\x{2A700}-\x{2B73F}]
扩展D区 [\x{2B740}-\x{2B81F}]
扩展E区 [\x{2B820}-\x{2CEA1}]
扩展F区 [\x{2CEB0}-\x{2EBE0}]
扩展G区 [\x{30000}-\x{3134A}]
兼容 [\x{F900}-\x{FAD9}]
兼容扩展 [\x{2F800}-\x{2FA1D}]
部首扩展 [\x{2E80}-\x{2EF3}]
注音 [\x{3105}-\x{312F}]
笔画 [\x{31C0}-\x{31E3}]
康熙部首 [\x{2F00}-\x{2FD5}]
注音扩展 [\x{31A0}-\x{31BA}]
私用SSP [\x{E000}-\x{F8FF}]
私用PUA-A [\x{F0000}-\x{FFFFF}]
私用PUA-B [\x{100000}-\x{10FFFF}]
7 个赞
我也想回这句,发现大佬回复了。哈哈哈,![]()
我在EmEditor内,中文、日文汉字都是用[[:unicode:]]来匹配,您也可以试试。
1 个赞
这个匹配范围太宽了,除了ASCII和拉丁补充外,任何编码大于255的字符都匹配上。
1 个赞
emedior和notepad++的默认正则引擎都是Boost::Regex,它的\u语义和其它引擎不同,这个在boost里表示大写
https://www.boost.org/doc/libs/1_80_0/libs/regex/doc/html/boost_regex/syntax/perl_syntax.html
3 个赞
[〇-龟]+ 匹配大部分汉字