再次感谢分享
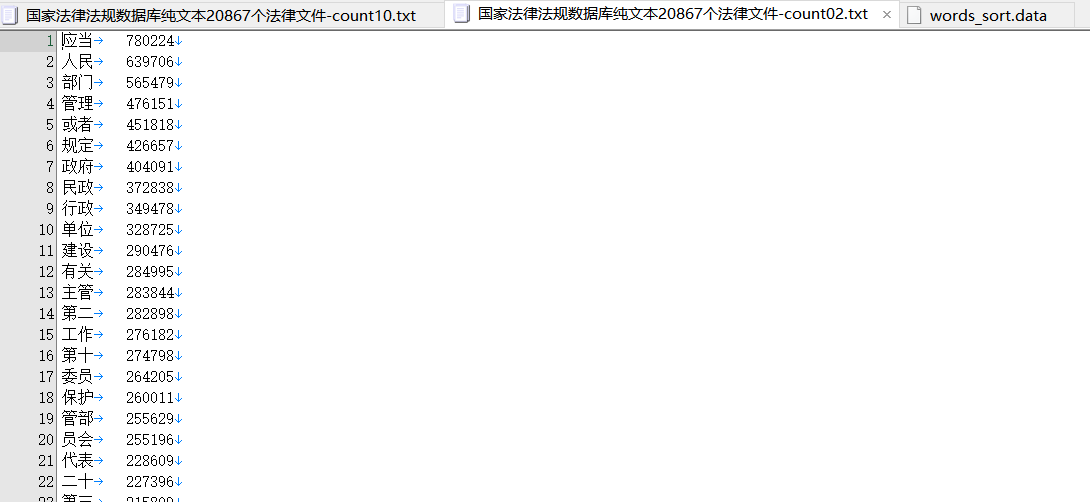
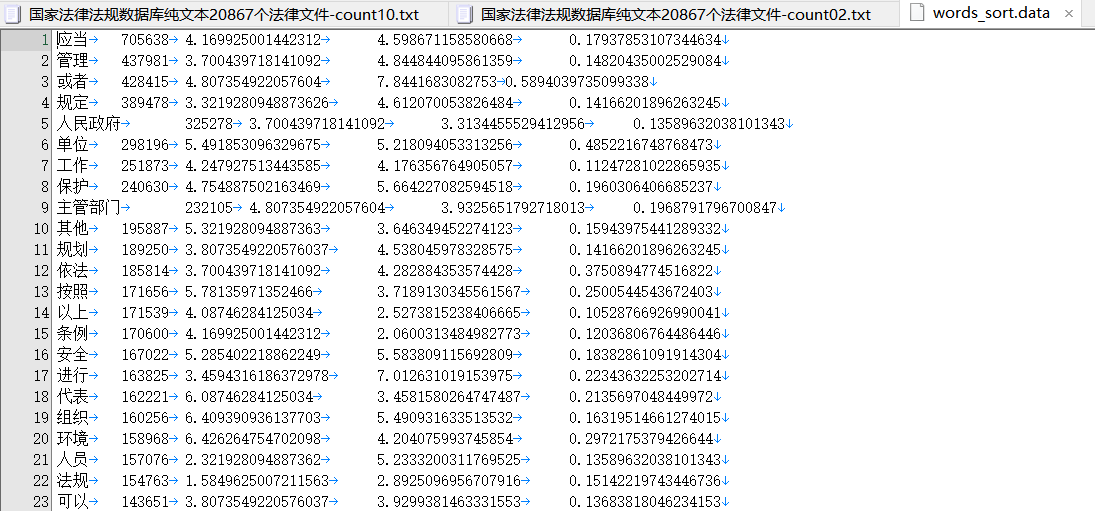
对用一个语料采取dict_build-0.0.3 分词和楼主自己的机械分词比较
dict_build-0.0.3 分词结果准确率更高,遗漏 了不少词语
也不能发现长度更长的固定词组。
只能说各有优点吧。
机械分词虽然存在冗余的词汇,却不会遗漏任何一个词语。
鸿雁输入法目前的方案是先统计出机械分词,然后让重叠的机械分词内部竞争。
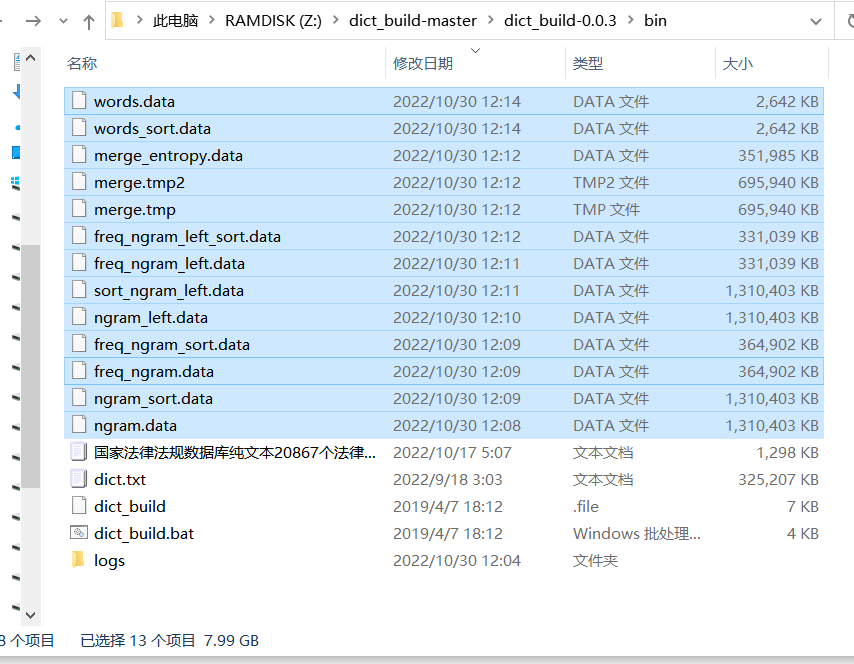
dict_build-0.0.3 想要应用分词,还需要改善。一个是长词的发现功能开启,另外一个是300MB的原始语料临时文件高达8GB
1 个赞
win 10版64 ,安装了。重启了。不能用。装的是加强版。无法输入汉字,只能显示拼音。望解决。
加载词库需要一段时间。
查看一下 用户文件夹 下build文件夹里面有没有hongyan_pinyin_simp.table.bin 这样的预编译词库文件
查看系统进程有没有7.0的算法后台进程。
可以用小狼毫助手重启一下输入法算法后台进程。
可以试一试重新部署一下。
目前最大的可能是:
下载了文艺基础版。下载后马上被报病毒。在英文版的Win10下运行时被拦截,用管理者权限也不能安装。
输入法的可能敏感操作
del /F /S /Q “%SYSTEMDRIVE%%HOMEPATH%\AppData\Roaming\Rime*." ”
md “%SYSTEMDRIVE%%HOMEPATH%\AppData\Roaming\Rime\build”
:x64
if not defined num (taskkill /F /IM WeaselServer.exe)
if not defined num (start “” “%PROGRAMFILES(x86)%\Rime\weasel-7.0.0.0\WeaselServer.exe”)
终止输入法后台进程,删除用户文件夹的原有配置文件。移动词库预编译索引文件。
这些都是正常的操作。
windows安全中心经常误报的,鸿雁输入法7.0现在已经有一千多下载量,现在提到报病毒的还是第一次。
mxlcpu
2022 年10 月 31 日 12:04
66
安装了文艺强化版,里面没有小鹤双拼,请问怎样添加?
安装增强版
打开 C:\Program Files (x86)\Rime\weasel-7.0.0.0\data\hongyan_pinyin_simp_flypy.schema.yaml
修改为
translator:
保存,重新部署
1 个赞
终于找到了一个好用的输入法:手心输入法。与我此前一直使用的百度输入法特别类似,但比百度好用,纠正了百度的几个缺点,也没有任何广告之类的东西。
知乎上的一篇文章:干净无骚扰的输入法——手心输入法 - 知乎
kapas
2022 年11 月 5 日 02:04
70
这东西到底是个人还是公司做的?
M303
2022 年11 月 9 日 10:43
73
我这里有个中文之星智能狂拼Ⅱ 在2003年的时候光盘版里复制的,在XP和win7下都可以使用,就是没法使用在win10上,不知道你能否把这个修改成win10系统下可以使用的输入法。智能狂拼有个好处是自学习功能。这输入法在2003年的时候就实现了整句拼音输入,支持部分不完整拼音输入。另外这输入法应该没有那些监控用户的行为,在那个年代程序员比现在还算是正常点。序列号在readme里的第一行中文之星智能狂拼II.part01.rar (10 MB)中文之星智能狂拼II.part02.rar (10 MB)中文之星智能狂拼II.part03.rar (10 MB)中文之星智能狂拼II.part04.rar (10 MB)中文之星智能狂拼II.part05.rar (10 MB)中文之星智能狂拼II.part06.rar (10 MB)中文之星智能狂拼II.part07.rar (10 MB)中文之星智能狂拼II.part08.rar (4.5 MB)
M303
2022 年11 月 9 日 10:45
74
手心输入法也不干净。之前用过,后来看到有人分析过就删了。
win 10 和 win 7 输入法架构发生了变化,接口发生了变化
简单一个补丁是没法搞定的。
内嵌技术
《智能狂拼》软件在后台的处理上采用了中文之星公司历经三年开发的CLM(中文语言模型)核心技术。该技术是在分析了覆盖经济、政治、文化、科技、教育、文学、历史、哲学、军事、体育、法律、社会新闻等众多领域100亿汉字(相当于228年《人民日报》的总字数)的基础上开发出来的新型中文语言模型技术。
鸿雁输入法也是基于语料库的分析,目前的语料库有350GB,包含1638亿个字符,有效汉字字符886亿个。
鸿雁输入法的方案是暴力穷举词组,词组最长的有16个汉字
鸿雁的方案覆盖的词语更为全面,不过多余的机械词语也增加了,这种方案在技术上实现也比较简单
智能狂拼的技术依赖建立在分词技术上的三元组技术,和前者的作用差别不大。
M303
2022 年11 月 9 日 11:21
76
可用的就是数据。这些拼音输入法智能狂拼算是比较早的整句拼音输入,后来出了google拼音输入法,紫光拼音,搜狗,讯飞,卡饭拼音输入法,手心输入法,客观说基本都是相互抄袭的。其实你这个鸿雁也是基于小狼毫输入法的模块
谷歌的整句输入还真的是自己自己研发的
可惜,输入法市场免费大行其道。
M303
2022 年11 月 9 日 11:28
78
其实早期的微软拼音就不错,不过不能整句拼音输入,后来才有这种输入法。输入法不赚钱太正常了,因为软件很容易盗版。光盘很容易复制。所以开发出来之后很快就被复制了。赚不到钱当然就做不下去了。