只要你按下回车就会记住你输出的词语
C:\Users\你的用户名\AppData\Roaming\Rime\build\hongyan_pinyin_simp_wenyi.schema.yaml
这个文件里面有全角符号的对应关系
只要你按下回车就会记住你输出的词语
C:\Users\你的用户名\AppData\Roaming\Rime\build\hongyan_pinyin_simp_wenyi.schema.yaml
这个文件里面有全角符号的对应关系
实践证明,还是记不住自造词啊。比如我随便输入一个人名,回车后,再输入这个词还是没有。这个输入法感觉基础不错,但毛病、问题也多多,有待完善吧。
词库再大,总不能将所有人名、专用名词都纳入吧?所以不能造词真是大问题。
这个一个bug,是rime输入法存在的问题
造词 是有顺序的
先造 出 柳泓
再把许 和 柳泓造出 许柳泓
许,柳,泓
许,柳泓
许柳泓

谢谢!总之是太麻烦了,不符合一般人的输入习惯。这个输入法需要完善的地方太多。我也赞同词库大并不是最重要的,重要的是使用方便、运行稳定,没有广告、升级等的干扰。
rime下是可以轻松自造词的,包括四叶草拼音方案,打一遍就行了。
许柳这个词语本来是有的
出现词语竞争
你根本就没明白我意思。
是需要用词频将伪“词组”打压平衡,但不是个体用户词频。
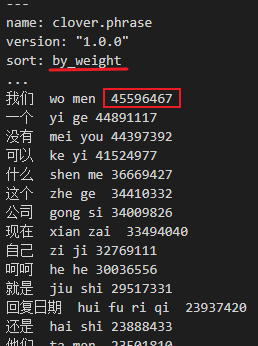
在早期,通过赋予真正的、经过历史确认的(主要体现在收录到词典中)词组比较高的权重,比如10万,乘以在相关资料中出现的次数(常用的可能几万几十万,比较偏的可能只有几个),那么就会大量的真正词组超过那个出现了166万次的“大自”。
而且可以通过不同材料组赋予不同权重,进一步降低不常用词组的词频得分,比如口语篇10万,古代文学10,那么一个现代词组比如“打字”它的词频得分就会大大超过“达子”。

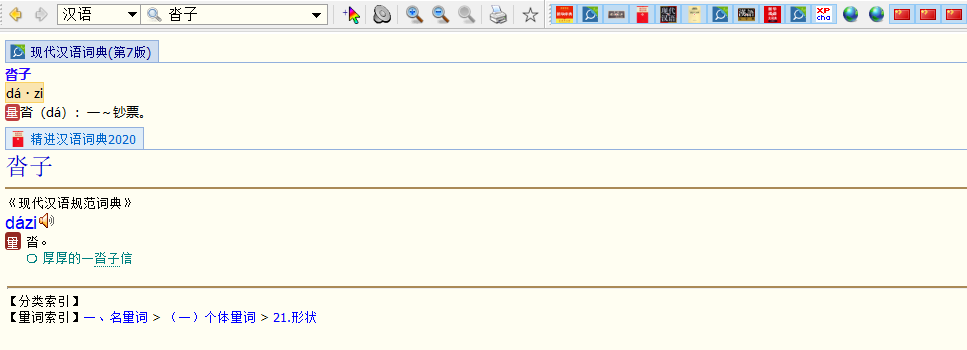
这是我刚安装的搜狗拼音输入法,里面没有那个机器分词出现166万的“大自”,反而是出现了个“沓子”。用词典搜了下:
人家搜狗不仅可以利用现成的资料库,还可以统计用户输入的资料库,这个量是很大的。它这样学习出来的效果,肯定要比纯机器分词、机器学习强。论机器深度学习,个体永远比不上大公司,他们的资料库太大了,是个体的万倍以上。百度有爬取全网的中文,搜狗有全国多数用户的输入数据,搞网盘的百度、阿里有大量的照片视频,做网购的淘宝京东PDD有大量的购买事例……有这么多数据在,才有机器学习的准确性。
现阶段,最好的追赶方式,是利用前人的智慧,这么多专家学者给挑选出的词典资源不去利用,太亏了。
而且,我见过一位大神打包rime输入法时,还特意把词频过低的给删除了。
词频FW=词权重WW1×(语料组权重TW1×在该语料组出现的次数N1+TW2N2+……)
词权重WW=词典权重DW1100000+DW2*10000+……
简繁权重:
对简体用户,简体资料与繁体资料权重比0.6:0.4
对繁体用户,简体资料与繁体资料权重比0.4:0.6
楼主辛苦了,但如果只是机械统计连续的字,把什么“大自”“达自”之类都算成高频词,那实在称不上“高质量词汇”
这篇文章可参考:
http://www.matrix67.com/blog/archives/5044
楼主的情况就相当于文中说的把“下子”“后遗”这种高频片段都当成词了,文中给了一些解决方法,可参考
又实测一下,确实问题太多。我个人认为搜狗、百度输入法都不太好用,主要感觉是词库不稳定。我曾将辞海、辞源的所有词汇加入百度输入法中,一开始都能输出,非常方便,但时间一长就找不到了,也是奇怪。希望有新的输入法能解决类似问题。说实话,我一直认为拼音加加那个输入法好用,我曾使用了很多年,很多非常实用的功能搜狗、百度都没有,可惜在win10下用不了了。当然,楼主无偿贡献自己的作品,这种精神很好,希望不断改进吧。总之,渴望有新的能代替拼音加加的输入法出现,不是像某些新输入法那样在联网状态下工作。
可能每个人打字的内容、需求不同吧。我很少输入现代汉语和一般口语,主要输入的内容是古文、书面语等。
现在有个简单的办法,就是抄袭搜狗候选的排序。
按照词频统计
打字
大字
按照动词 名词的属性分别排第一位的,搜狗也是这个排序。
这样一抄,就侵犯版权了。当年谷歌输入法被搜狗输入法追着咬了一地鸡毛,就是被抓住抄袭的小辫子。
yaoming
“要命” 排第二
“要明” 排第一
你输入 “要命” 次数多于 “要明” 了
真是要命 就会排第一
文中提到的两个分词存在交集,按照组合概率组合选择最优的分词。
我也曾考虑过 这种方法不过这位北大学子只是处理简单的模型,真实情况更复杂。
高兴地吃饭
如果 高兴地 概率是 0.0001
吃饭 的 概率 是 0.00015
按照理论,高兴地吃饭 的概率应该高于 0.0001*0.00015才对。
真实的情况是,有时候 真实概率 还低于 理论预测的组合概率
真实的比例几万倍到几万分之一之间 震荡
贝叶斯法则失效了。这有点太魔幻。
我只能用梯度下降算法勉强搞出机器学习分词。
这个勉强还能用。
沓子
在文艺强化版 也有这个词语
排名第21
你做输入法应该比我清楚呀,不是要你抄袭排序。
而是词频,要做出词频词库来,真正符合需求的,对照搜狗也只是核对词频的效果。
就像做出的输入法候选项出现“大自”,这就不正常,需要添加权重规则,来生成符合需求、语义分析的词频。
您的想法意思是
在存在权威词库的情况下可以通过权重调整候选词的排序。
我曾经考虑过这点,最大的问题就是这个权威词库的边界是模糊的。
现代汉语词典,百度百科标题是权威的,但仅仅质覆盖名词,动词副词、俗语覆盖率不高。
我个人认为最高效的分词库,就是 分词质量高,数量足够大只有搜索引擎的查询词语记录有。
百度指数只有和商业推广相关的词语。
google trends 有高质量的词语,ip封禁的非常厉害,需要大量C子网切换。
暴力穷举要猴年马月。
如果像跨境电商购买大量代理ip,几百美刀起。
伤不起,google trends 这个让我垂涎三尺的数据库还是放弃了
“处五年以上有期徒刑”
“异曲同工之妙”
梯度下降算法能够发现这样的组合1000万。
代价就是有一些多余的词语也被筛选出来。
梯度下降的参数不好控制,太小,漏掉大量词语
太大,多余的词语增多。
如果选择一个合适的参数,有用的词语和多余的词语在合适的比例,综合来看,是不是高质量的词语数据库
这个世界不是非黑即白,边界没有那么清晰,边界也有可能是模糊的,或者灰色的。
牺牲空间获得时间,牺牲部分质量获得整体上的质量。
最优的选择有时候看起来不是最完美的选择。

鸿雁拼音完整版 是可以顺利打出 真是要命
只能说开源的中文分词数据库里面是不存在 “真是要命”,更为准确的说法是大部分开源的中文分词数据没有这个组合。
如果您要获得更为完整的体验,建议您使用鸿雁拼音增强版。
不过您要忍受机械分词带来其他的冗余的词语对您的干扰。
鱼与熊掌不可兼得。在低成本的制作下,既快又好是比较难以实现的。
另外,深度学习的梯度下降算法并没有发现“真是要命”这个词语,机械分词的统计词频发现了这个词语。
我个人习惯用增强版。
如果您使用文艺版,建议您拆分成 真是/要命
用户词典的开启会补充不足之处