你根本就没明白我意思。
是需要用词频将伪“词组”打压平衡,但不是个体用户词频。
在早期,通过赋予真正的、经过历史确认的(主要体现在收录到词典中)词组比较高的权重,比如10万,乘以在相关资料中出现的次数(常用的可能几万几十万,比较偏的可能只有几个),那么就会大量的真正词组超过那个出现了166万次的“大自”。
而且可以通过不同材料组赋予不同权重,进一步降低不常用词组的词频得分,比如口语篇10万,古代文学10,那么一个现代词组比如“打字”它的词频得分就会大大超过“达子”。

这是我刚安装的搜狗拼音输入法,里面没有那个机器分词出现166万的“大自”,反而是出现了个“沓子”。用词典搜了下:
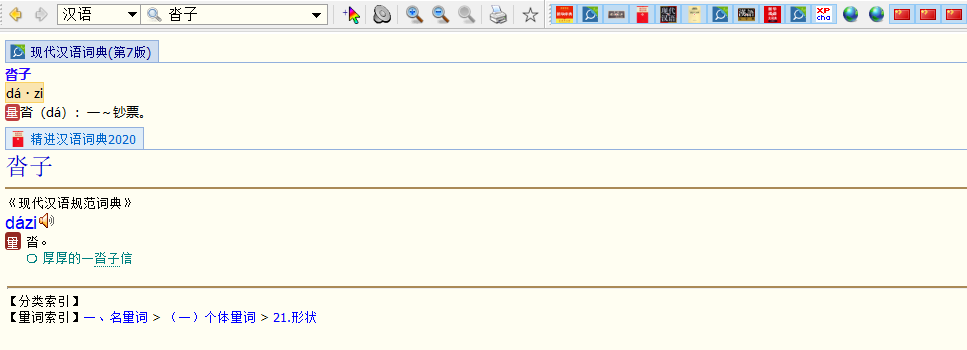
出现在三个词典中。
人家搜狗不仅可以利用现成的资料库,还可以统计用户输入的资料库,这个量是很大的。它这样学习出来的效果,肯定要比纯机器分词、机器学习强。论机器深度学习,个体永远比不上大公司,他们的资料库太大了,是个体的万倍以上。百度有爬取全网的中文,搜狗有全国多数用户的输入数据,搞网盘的百度、阿里有大量的照片视频,做网购的淘宝京东PDD有大量的购买事例……有这么多数据在,才有机器学习的准确性。
现阶段,最好的追赶方式,是利用前人的智慧,这么多专家学者给挑选出的词典资源不去利用,太亏了。
而且,我见过一位大神打包rime输入法时,还特意把词频过低的给删除了。
词频FW=词权重WW1×(语料组权重TW1×在该语料组出现的次数N1+TW2N2+……)
词权重WW=词典权重DW1100000+DW2*10000+……
简繁权重:
对简体用户,简体资料与繁体资料权重比0.6:0.4
对繁体用户,简体资料与繁体资料权重比0.4:0.6