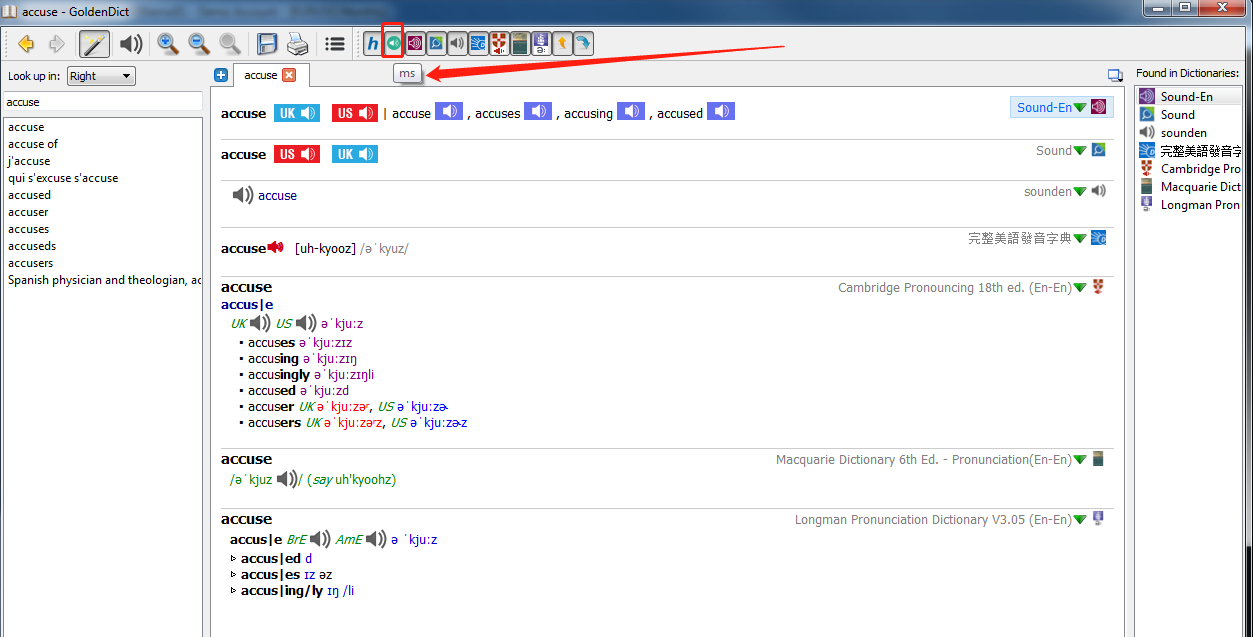
awk
1
缘由:
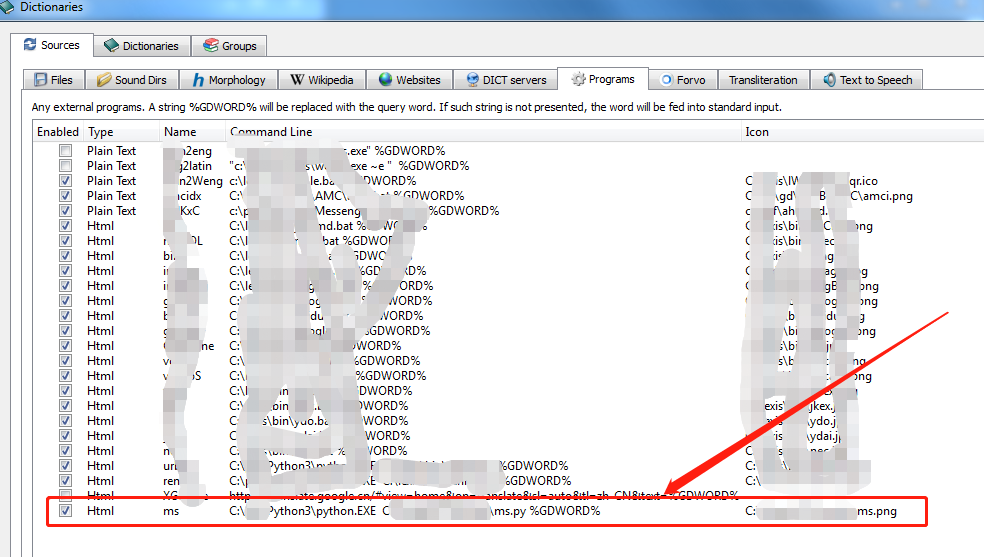
- GoldenDict(GD)能自动读出分组的第一个音频文件并发音. 这个发音往往是单词的原型. 如果你需要GD读出单词的变形(譬如: 复数, 过去分词, 现在分词…)就必须首先找到有这些发音文件的(发音)词典, 并逐一点取而后发音(也许可以使用快捷键加快点击速度)
- 本帖所涉及程序的目的: 在GD输入查询标的后, GD能自动全部逐一读出所有变形音频或相关短语.
今天准备动手做了
不知道有没有朋友有类似需求?
目标: 在GD上查询标的时自动读出指定的音频内容, 可以是以下内容及其组合
- 单词原型
- 单词变形
- 例句
支持格式:
- SPX(这个优先, 主要是因为手里的发音字典比较全面的是SPX格式)
- MP3
- AAC(ACC)/WAV
实现方式:
- GoldenDict + Python(3)
2 个赞
awk
3
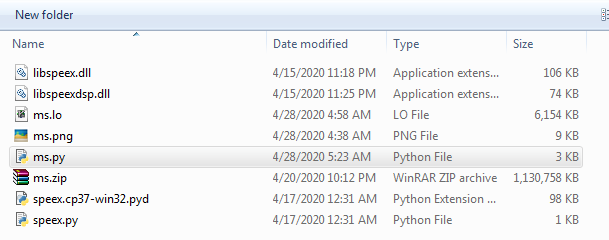
<本楼所载源代码转载请注明出处>
ms.py
#awk@freemdict.com
import sys
from speex import *
import winsound
from zipfile import ZipFile
import time
import os
def decode_spx(vocoded):
if vocoded[0:4] == b'OggS':
spx_header = SpeexHeader.from_packet(vocoded[28:])
mode = spx_header.mode
if mode == 0:
multi = 2
mode = 1
else:
multi = 1
decoder = SpeexDecoder(mode)
wav_header_size = 44
wav_head_1 = b'RIFF'
wav_head_2 = (b'WAVE' + b'fmt ' + int.to_bytes(16, 4, 'little') + int.to_bytes(1, 2, 'little')
+ int.to_bytes(spx_header.nb_channels, 2, 'little') + int.to_bytes(spx_header.rate//spx_header.nb_channels*multi, 4, 'little')
+ int.to_bytes(spx_header.rate*multi, 4, 'little')
+ int.to_bytes(2*spx_header.nb_channels, 2, 'little') + int.to_bytes(16, 2, 'little') + b'data')
i = 0
pcm = b''
while i < len(vocoded):
if vocoded[i:i+4] == b'OggS':
granual_no = int.from_bytes(vocoded[i+6:i+14], 'little')
if granual_no > 0:
# audio data
page_seg = int.from_bytes(vocoded[i+26:i+27], 'little')
start_pos = i + 27 + page_seg
for j in range(41):
packet_size = int.from_bytes(vocoded[i+27+j: i+27+j+1], 'little')
pcm += decoder.decode(vocoded[start_pos:start_pos+ packet_size])
start_pos += packet_size
i += 1
file_size = wav_header_size + len(pcm) - 8
data_size = len(pcm)
wav_data = wav_head_1 + int.to_bytes(file_size, 4, 'little')
wav_data += wav_head_2 + int.to_bytes(data_size, 4, 'little')
wav_data += pcm
return wav_data
def locate_file(voc_str):
index_file = os.path.dirname(sys.argv[0]) + "\\ms.lo"
with open(index_file, "r") as f:
for line in f:
file_list = line.rstrip().split('::')
if file_list[0] == voc_str:
file_list = file_list[1].split('|')
break
voc_zip = os.path.dirname(sys.argv[0]) + "\\ms.zip"
with ZipFile(voc_zip, 'r') as zf:
for name in file_list:
try:
wav_data = decode_spx(zf.read(name))
except:
print("no audio file", name)
continue
winsound.PlaySound(wav_data, winsound.SND_MEMORY)
time.sleep(0.5)
return file_list
def main(argv):
voc_str = argv[0]
locate_file(voc_str)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("usage: ms/whatever.py word")
exit(1)
main(sys.argv[1:])
awk
4
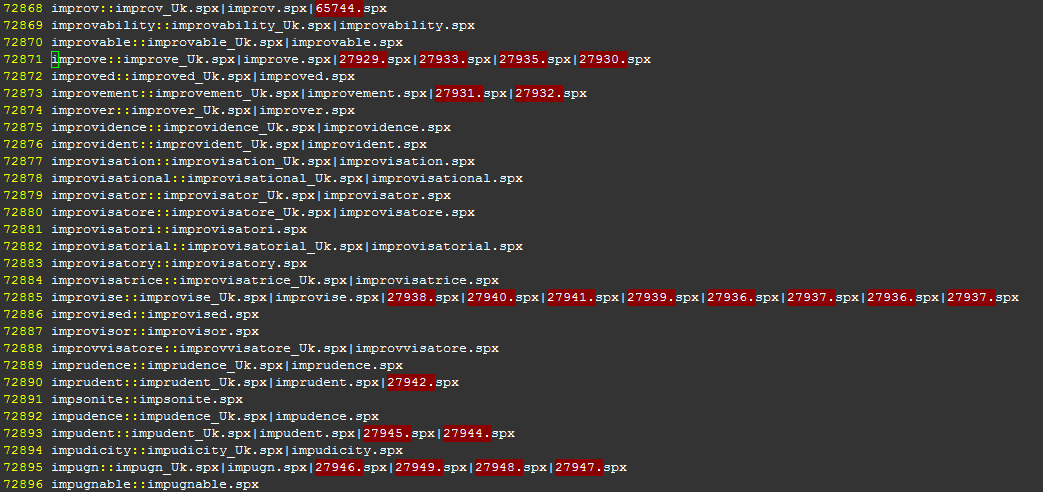
1. ms.lo文件及格式, 本文件指定一次性读出内容, 分隔符号分别是**::和|**
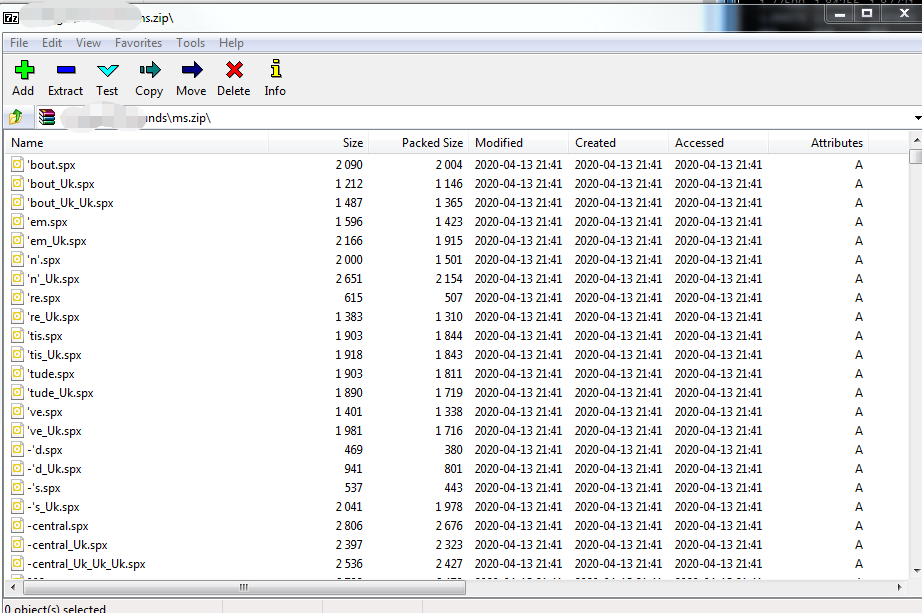
2 ms.zip, 放置音频文件(内置音频文件格式目前只支持SPX, 音频文件无父目录, 与GD资源文件要求相同)
3. 所需要的库