坛子里高手众多,希望不吝赐教,谢谢!
想找个例子速成一下,谢谢各位的建议
1 个赞
这个贴子谁愿意帮我爬一遍 WordReference 的#33或#44有现成的例子
爬的速度挺快的8线程,能不能速成就看你的了
3 个赞
非常感谢,如果看明白了争取弄个详注版上来,方便有需求的随时修改。如果没看明白就没法子了
1 个赞
把 @Sunny1 老兄推荐的这位前辈的一个爬虫程序仔细研究了一下,加了点注解把变量名按自己的习惯改复杂了
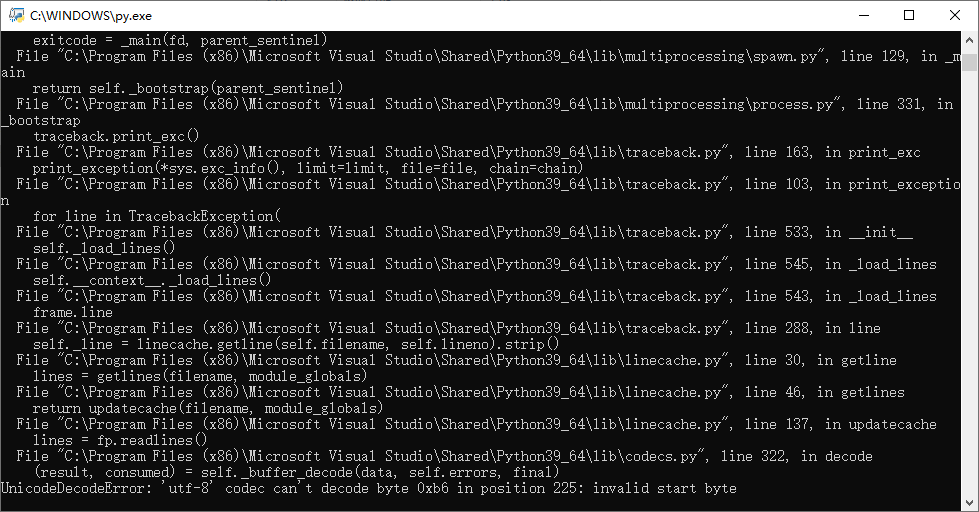
在我的VS中怎么跑都没问题,但是在Win下直接点击运行出现下面的屏幕,后来不知怎么又闪退,应该是中文注解引起的,请专家有空的话帮忙看下什么原因,谢谢!
wg04-16 (lurker)(#44)(annotated).py (4.8 KB)
又试了下原帖中的代码,结果一样的,VS中运行可以,直接在 Win下运行不行,从窗口提示看是跑到保存文件的步骤时闪退的。
上面的注解文件中已经是加上了这行的。
1 个赞
再重述一遍问题:
- 原帖中的原始代码(wg04.py)和本帖中注解过的版本的效果没有差别
下面两种方式(2 和 3)不知道有什么区别:
- 在 Windows File Explorer 中,用“打开方式”打开 wg04.py,运行1屏后就闪退

此种方式运行一个极简测试程序则是可行的


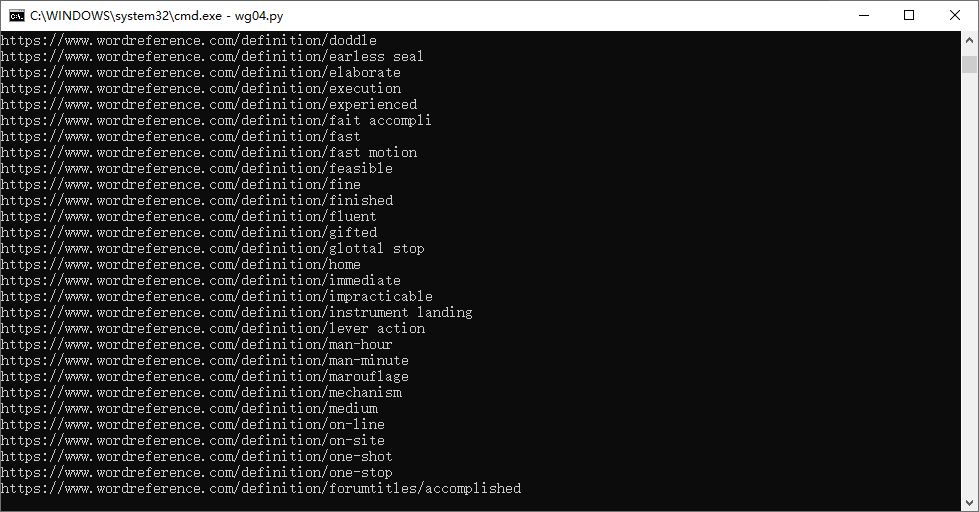
- 在 Windows File Explorer 中,直接点击 wg04.py 可正常运行
环境变量中已经添加过

两处小错误:
dc = dc.replace('\n', '')
# 应改成 dc = dc.replace('\n', ' ')
hr = urldefrag(urljoin(base, ah['href'])).url
# 应改成 hr = urldefrag(urljoin(url, ah['href'])).url
一般如果合并两段 <div>...</div>,是不是插一个空格似乎也无妨,不过插个空格是保险一点
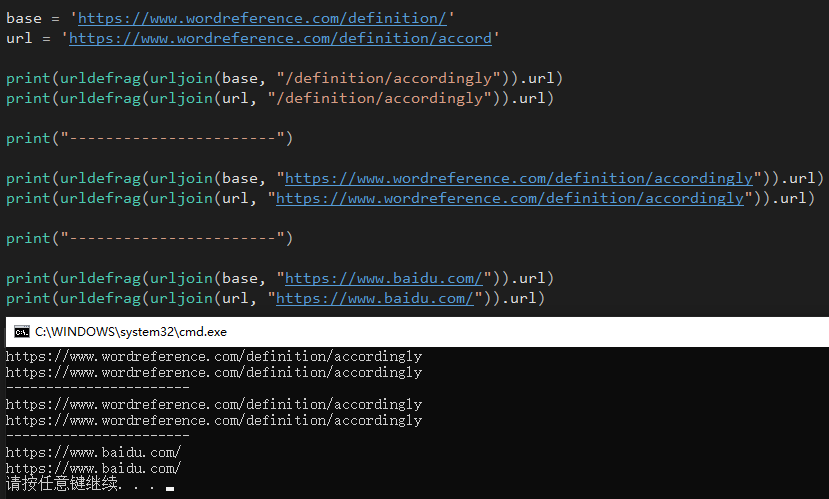
在 Word Reference 网站应该找不出反例,但 urljoin() 的第一个参数最好是当前地址,这样处理相对地址时才不会出错。下面是一个极端反例:
base = 'https://www.wordreference.com/definition/'
url = 'https://www.wordreference.com/definition/abc/123'
result1 = urljoin(url, 'def')
# result1 = 'https://www.wordreference.com/definition/abc/def'
result2 = urljoin(base, 'def')
# result2 = 'https://www.wordreference.com/definition/def'
1 个赞
刚才看了下文档,这几个函数设计得有点费解,还是自己用字符串操作处理一下得了 ![]()
b 大的遗泽这么香,不用吗?!
1 个赞
这个代码是python2的,就算用python2运行有些地方也要改
1 个赞