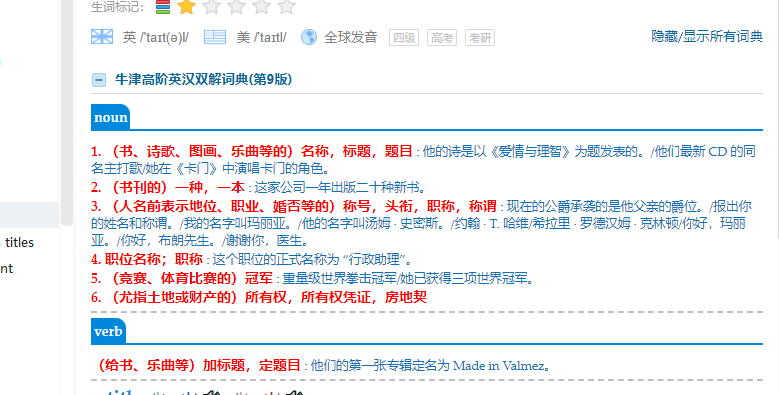
我的目的就是希望 ,我能够快速预览每个单词的释义,而不是看了一好几分钟,有多少意思都不知道 主要目前没有怎么背诵,希望各位网友指出,一起指出BUG,获取剔除建议,我会及时修改.
基于牛津 9版本 20191119那个版本
链接: https://pan.baidu.com/s/1ytndHRPTtSGs7XJq3X4c5w?pwd=ucir 提取码: ucir 复制这段内容后打开百度网盘手机App,操作更方便哦
–来自百度网盘超级会员v6的分享
链接附上
请问用的是这个版本的吗,如果之前用过这个版本,你需要进入
把这个
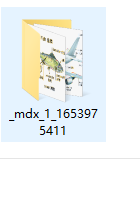
给删除,如果你用的词典比较多貌似会生成很多,只能自己甄别了
欧陆词典 他默认不会比对读取安装的词典的css 和js和temp中的不同,所以需要你手动修改 ,
22.10.08 修复多个单词,多个词性的问题
感谢分享,制作辛苦。不过不结合英译和例句,似乎不能确定中文意思就能记住和会使用了呢 
第二张图的 details 的定义有大 bug 吧。
tail 才是尾巴呀。。。
detail 跟尾巴没半毛钱关系的啊。。。
是的,特别是高阶词典,很多不常用的义项也很多,确实只是拿来背单词的话多少有些不便
如果真的要学习单词,这些都要背的,包括词性啥的.
其实不是英语层面的问题,是中文层面,我压根就不知道它讲的词东西,如果用一个句子,就很清楚.比如说坚硬,那什么坚硬呢.核桃坚硬.然后你就有印象了.
下载试了,和你后来发的图显示一样。没有发现怎么呼出只显示你最开始那个截图里绿色全中文的界面。
请问用的是这个版本的吗,如果之前用过这个版本,你需要进入
把这个
给删除,如果你用的词典比较多貌似会生成很多,只能自己甄别了
欧陆词典 他默认不会比对读取安装的词典的css 和js和temp中的不同,所以需要你手动修改 ,
每个词典的html dom树和标签名称都是I不一样的.我只是做了一个版本的.
我把东西发上来,其实也是希望,论坛朋友帮我一起把问题解决了,因为整本牛津的查词非常随性,他也不是数据库类型的数据,有规律,但是我一个人想的肯定不周全!
leebye
13
我知道了,是因为我用的是GoldenDict,不是PC版的欧路词典测试的
leebye
14
我下载了一个欧路的PC版,就和你显示的一样了。不过有必要把例句的中文释义也整合在前面么?
可以把例句去除,做个配置 ,原因还是我只想看牛津的,因为考研最多的生僻释义就是牛津,不可能再多.而如果使用有道 或者一些英汉词典,要么有网络的,要么有
leebye
16
不过感觉如果是为了记单词的生僻意思,只看中文,不看英译和例句,还是不容易理解的,多半还要往下翻
mdict6
17
这个方法,对那些中英双语单词,完全一一对应的,会非常好用。
但是对那些高频词,就是a1 那种级别的词,会非常的难用。
最后的结果是用心刷完后,简单词的词义还是没记住,需要再次返工。
不一定对啊,我的一点心得。FYI 我应该回复楼主的
mdict6
18
但是我是支持楼主搞这么一本mdx 的,因为对英语学习苦手,帮助还是挺大的。算是导航了。
看一楼的照片,是提取中文后、放置于词典内容的前面。是吧。很好的一个快速导航的想法
leebye
19
很多朋友都是用别的词典做头部词典,大概率就是因为大部头词典查的时候不能最快的获取中文含义。这样提取的确方便为了查词的用法,不过也像您说的那样。对于take、have这种含义巨多的高频词,反而会有些混乱。而且的确没必要把例句的中文含义也提取出来,反而会让人看不懂了。
mdict6
20
例句的含义就可以考证那些 take. have 的释义了
做个折叠呗
反正是短期用的,万一出乎意料的很好用呢,是吧