在维基文库的香港《常用字字形表》里,有收录:
任、仼
这两字里,任为正字,仼为异体字。我的疑问是这里的仼是否为误录?目前只看到《常用字字形表》里有这样映射关系,在《香港小學學習字詞表》里只收录了任字,字形和仼也不一致,但网上不同来源的《常用字字形表》都有仼这个字。
在维基文库的香港《常用字字形表》里,有收录:
任、仼
这两字里,任为正字,仼为异体字。我的疑问是这里的仼是否为误录?目前只看到《常用字字形表》里有这样映射关系,在《香港小學學習字詞表》里只收录了任字,字形和仼也不一致,但网上不同来源的《常用字字形表》都有仼这个字。
《汉语大字典》说“仼”同“彺”。
但是Unicode资料说“仼”是“U+4EFB 任”的异体字。
这大概是个俗字,就是说有很多人写错了,很多人将错就错,当它是“任”字。
《汉语大字典》第2版
〖仼〗
仼同“彺”。《改併四聲篇海·人部》引《餘文》:“仼,急行也。”按:《玉篇·彳部》:“彺,急行皃。”“仼”与“彺”音义相同,“仼”当即“彺”的异体。
仼 U+4EFC
Data type Value
kSemanticVariant U+4EFB 任
http://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=4EFC
Unicode的资料需要配合原始来源才用得放心。比如鹃和鹂,从Unicode13.0开始视作Z变体,到15.0移除,而Z变体要求词源相同,这对映射就很莫名其妙。
U+9E42 kZVariant U+9E43
U+9E43 kZVariant U+9E42
这两个字没可能是异体字关系。假如这样显示,应该纯粹是资料输入错误。
由一些不是词典学家的人去编这么复杂的一个资料库,搞出一些错误来实在不足为奇。不过错误似乎不多。
汉字编码最开始的时候是两岸三地分头推进,以香港为例,本地一开始有多个商业公司分头自己造字编码。我也是做这本MDX时才知道
Use the Right Word英文字用法指南
后来要规范要统一,但汉字字形过于复杂,最省事保险的方式是简单合并,这也导致Unicode里头同一字有多个编码的情况并不少见。
不过话说回来,汉字字形稍有差异的,谁敢打包票说就是同一个字呢?
现在就很疑惑任仼的正异体关系,有没有其它的权威字典/词典可以印证。
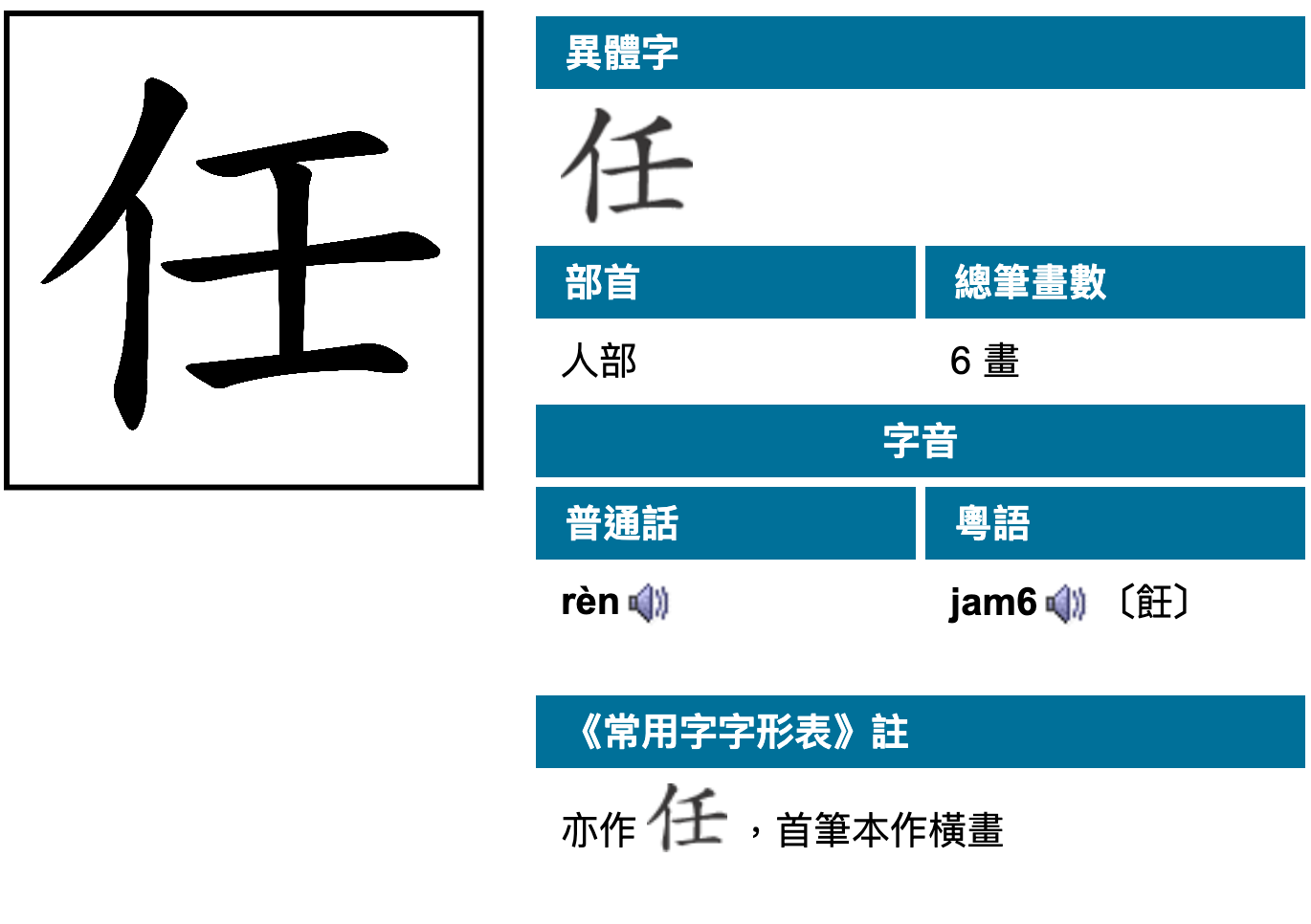
香港《常用字字形表》標準字體表里的任字形如下:

再参考《香港小學學習字詞表》,把任视为正字,Unicode的编码相同,只是首笔作横,有没有可能仼字是在后期文本整理时误录的?
《常用字字形表》標準字體表.pdf (3.9 MB)

這兩個字形都用 U+4EFB 表現。但任何電腦環境只能顯示其中一個,除非用圖片或私有區補充。(與 U+4EFC 無關。應付簡體字型無法顯示 4EFB 之H、T形,勉強借用4EFC 罷了,但字形、音義都不相同。)

G 形,繼承康熙字典字體。
H、T 形,更接近說文字體。參見篆形。
58EC 有一樣的分歧。

多个开源字表/汉字数据库都把仼字收录了,个人觉得危害有点大。
我同意。那做法誤導人。
如果是常用字字体,同时收录“任、仼”,那确实不应该。
尤其是搜索索引方面,会出现查询错误。
历史遗留问题,只能慢慢规范了。