太牛了
高山仰止
https://hong-yan.lanzouw.com/iGAeE0bufyqh
由鸿雁2700万词库和腾讯tencent-ailab-embedding-zh-d200-v0.2.0取交集而成
更新日期:2022-09-15 by sansi
扩大与鸿雁2700万词库取交集的的词库,包括高质量的标准词库和权威的中文词向量库。词库列表如下
百度百科+维基百科+完整词头
漢語大詞典2021-10-20-词语-订补
李白诗句全集
世界各个国家国名全称、简称549
世界各国和地区名称264
唐诗宋词论语道德经诗经短句
现代汉语词典 第五版epub词语
现代汉语词典第7版词语
中华人民共和国行政区划省级、地级、县级3363
tencent-ailab-embedding 1019万
facebook fastText 中文向量 15万
北京师范大学开源中文词向量 87万
更新日期:2022-09-17 by hongyan
词语输入方案已经更新到0.2的版本,欢迎下载试用
另外已经把“鸿雁拼音+腾讯词库测试版·全拼” 集成到鸿雁输入法5.0安装包中
只要切换一下输入方案就可以了
能否给个最终词库文本文件?
这个是鸿雁拼音2471万码表的文本文件
现在安装包 鸿雁拼音+腾讯词库 码表文本文件在输入法的程序文件夹内。
另外,单纯的词频文件在前面某一楼层也有分享
赞!作为RIME的长期用户,有个小小的愿望:将词库分类拆分为几个小词库,用户按需使用。
原因:
- 当初为了满足个性化需求,对RIME做了很多调教,不想因为与鸿雁输入法的兼容性问题而放弃或重新折腾一次,只想能够使用上鸿雁最精华的词库。PS 我的RIME方案:RIME + 英文(智能补全、纠错) + 小鹤双拼(主力) + 仓颉(辅助) + 明月全拼(小朋友使用)。特点:可以混输(无需切换),可以反查(用双拼查仓颉,或用仓颉查双拼,音码形码按需选择),可以模糊音(同时提供正确的全拼,这是口音党纠正拼音的必备神器),可以自定义词库(可以使用搜狗词库,但省却了广告干扰)、可以多电脑同步(但省却了无良商家对隐私的刺探)。
- 无论词库如何完善,都会有个性化词库的需求,比如亲朋好友的通讯录、工作常用术语、个性化日常高频词汇等,因此会经常性地重新部署词库,而现有的鸿雁大词库会比较麻烦。
楼主英勇!您截图中的词汇看起来不错。另外,下面几种词库或者词汇,还请考虑:
- 请考虑添加常用学科、技术词汇。不知道目前的常用学科、技术词汇是否已经足够,这有待验证。这里一个词库值得考虑:
http://thuocl.thunlp.org/ - 常用的文史哲、法律、合同、医学等词汇。
- 小学语文有古诗:《山村咏怀》, 宋·邵康节; 一去二三里, 烟村四五家。 亭台六七座, 八九十枝花。您目前的词库(v0.2 )包含了第一句,不含其他句。不知道是否值得收录其他句。这只是一个例子,推而广之,有更多的类似词条。 但总的来说,强烈建议考虑收录:小学生常用古诗、古词、短的名句、歇后语、惯用语。
- 拼音nu-nv,lu-lv等 问题:
比如女性-奴性,路路-屡屡这两个词,网络上流传其他词库,以及RIME官方词库,貌似对这几个词的注音为:女性-nv xing,奴性-nu xing,路路-lu lu,屡屡-lv lv。您目前的词库(v0.2 )注音为:女性/奴性-nu xing,路路/屡屡-lu lu。这样的话,很多词混在一起(女性,奴性 二词在同一个音下;法律和发露 二词在同一个音下),使用者可能不适应,v这个键也不得利用。请楼主考虑。 - 目前词库使用感觉:
-
噪音词汇和短句大大减少。
-
词频问题依然存在:天蝎(填写)教继续肆虐,重马(重码)压得人喘不过气来。历史太长(lishi一词下,有几百个选项),读不过来。 但好在楼主开放了词频自动调整选项,能缓解这种情况。另外,注音准确性问题。



-
欲输入非常规词汇时,比如“追求极致”,“完全胜任”,可以简拼打出来,出词率非常高,需要手工选词的场合减少,效率提高,输入感觉甚是流畅。
-
目测起来,这个词库实用性、流畅性、给人愉悦舒适感,超过绝大部分yaml格式词库,可以说正在追赶搜狗输入法;
-
鸿雁输入法/词库日新月异,不断改良,到现在已经很好,完全可以胜任日常生活和工作的输入需要;而且,有种种优点。
-
因此强烈推荐各位群友测试并使用!
将词库分类拆分为几个小词库,用户按需使用
举双手双脚支持
就是工作量有点大
大神太辛苦了
发现这个已经非常满足我的需求了,感谢!
只是有个建议:
- 单字和词汇分开。这样方便多种输入法对词库的不同组合。
- 按词频排序。目前不知道是什么排序。
此外,试用了一下,发现缺这几个常用词:“路虽远,行则将至“、”行稳致远”
新版越来越好,好想试试!! 不懂就问,目前最新版还是不支持win 11吗?这个是不是需要等小狼毫支持了,才会支持呢?如果把鸿雁输入法程序设置为以win 10兼容模式启动,可行吗
这个与linux 是采用宏内核还是微内核争论差不多。
使用单个词库,显然效率更高。
使用分类词库,属于高阶的应用。发烧友使用比较多。
不过rime输入法,复制改造一个输入方案非常方便。
如果为了编译的方便,可以拆分成两个词库
系统词库和用户自定义词库。
图形化的词库管理软件rimetool 可以方便做到这一点。
这个可能是windows 的api在win11改动了导致的
天蝎 重马 确实存在于腾讯1000万词库里面。
nu-nv,lu-lv的拼音标注问题
因为lue输入略已经是已经构成了事实标准。
在搜狗五笔输入法中开启拼音输入,lue可以出字略,lve出字只保留了lü没有略。
为了省事,码表中把v 和u视为等价,u和v并不等价
yushi 可以打出 于是
yvshi 却没有词语候选项
这是为了照顾 ü u不分 的用户
百度百科+维基百科+完整词头 这个数据库包含了不少科技领域的词语。
目前看来重点需要改进的是
专业领域的词库
医学
法律
设置为以 win 10 兼容模式运行这个输入法行吗
好的,谢谢分享!!我研究下试试
我在Windows 10下使用RIME + 这个hongyan词库,“重新部署”总是失败,直至舍弃weight在0-199之间的所有词汇才重新部署成功。
请教:RIME重新部署对词库要求的极限是什么? PS:我的电脑内存是32G,但在重新部署时,我看“任务管理器/性能”中的内存占用基本没什么变化,仅仅是CPU有略微上升,但也只有30%左右。
PS:我将hongyan词库分组如下,其中base是单字,phrase是词组;prhrase又再根据weight排序进行分组:99以下、199以下、499以下、999以下、1000、1999以下、3999以下、9999以下、五位数、六位数。

我的词库组合如下:
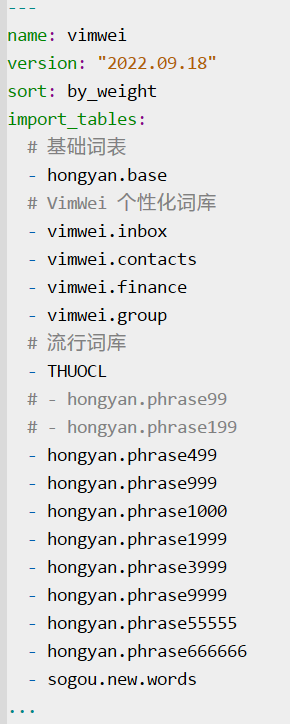
以下是舍弃0-199的hongyan词组后,"重新部署"输出的文件大小:

windows平台小狼毫输入法对于单个词库的数据量上限是300万左右,不到400万。
如果你选择一个输入法方案,同时这个输入方案制定一个码表,这个码表又引用其他的词库码表。
如果引用的数据量加起来超过 300多万,那么同样无法生成索引。
本来鸿雁词库数据量就接近极限,在加上其他的词库,当然编译失败了。
虽然你在配置文件是引用这个词库,但是所有的引用的词库都会合并到当前的码表下的。
可采取的解决方案是,你采用多个输入方案。
比如你自己的个人码表做一个输入法方案。数据量不超过300多万。
输入法方案选择的时候同时鸿雁全拼和 你的输入方案都勾选就可以了。
编译词库索引需要32GB的内存。 指的是在linux平台编译需要的内存,这里的词库容量是2471万,实际上最大的内存占用约为22GB。
在windows平台,鸿雁输入法轻量版的数据量已经逼近极限了。轻量版,就是在计算windows平台单个码表可以生成词库 数量的上限得来的称号。
以下是从上述词库中提取的weight最高的词汇(weight在6位数以上),已按weight倒序排列。
hongyan.phrase666666.dict.zip (500.9 KB)
看了一下,其中机械分词的痕迹比较明显。对于此类最高频的词汇,是否有优化的空间?

本来分词的时候就是采取暴力穷举的机械分词算法,这个速度远远超过其他的分词软件。
结巴分词速度大概在11MB/s
机械分词可以超过17MB/s
这个词库是鸿雁的2471万的机械分词的高频词与主要是腾讯分词tencent-ailab-embedding 1019万词语的交集。
另外还包括
facebook fastText 中文向量 15万
北京师范大学开源中文词向量 87万
错误的词语来源来源于这些词库列表,这些已经是开源的使用深度学习技术分词数据中最好的了。
只能说目前的深度学习技术还没到达非常完备的境界。
9月17日更新版5.0安装成功后,选择拼音、双拼正常;但选择“鸿雁拼音+腾讯词库测试版·全拼”后就一直是维护中,多次卸载安装都是如此。
发现“hongyan_pinyin_simp_tengxun.table.bin”这个文件内容是空白。
估计预编译方式可行 ![]()