人工编撰词典的成本是非常高的。
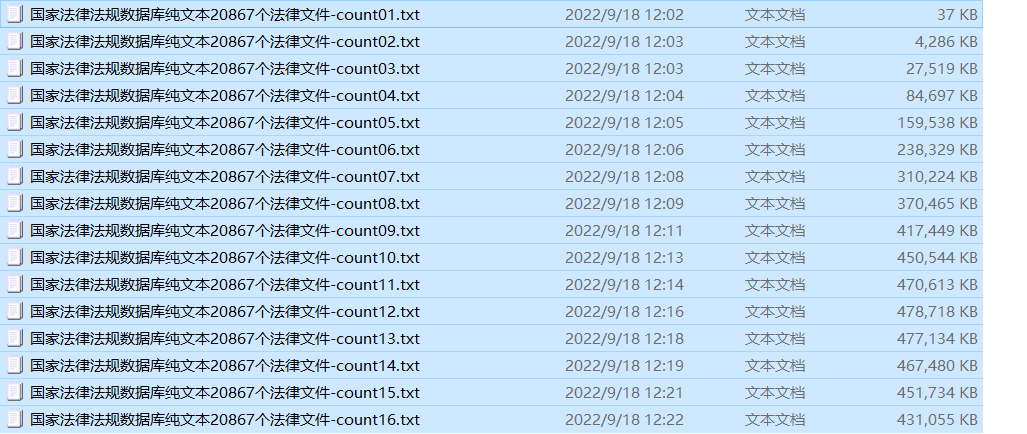
现在的文艺版 搜集的词语有1000万。来自多个网络上的开源词库。
现代汉语词典就有5万多词语,就有砖头那么厚。如果没有足够的人力,想做一个大而全的输入法词库是几乎不可能的。
人工编撰词典的成本是非常高的。
现在的文艺版 搜集的词语有1000万。来自多个网络上的开源词库。
现代汉语词典就有5万多词语,就有砖头那么厚。如果没有足够的人力,想做一个大而全的输入法词库是几乎不可能的。
汉语输入已经很不错了 (尽管目前没有看到前句输入后,后句跳出联想词句) !最起码也让我等对英文输入,有个比较有效地输入运用吧?以后可以完善,不管是谁来做!
谢谢大师!
您说的情况当然是客观的情况,我这里只是向您提供一个思路, 李氏的方案也并非是要人工编纂词典,而是在现有的字词之上,更着力于句子,提高句子的复用率,比如您的数据库中的人民日报数据库,在优化句子的使用过后,在机关写作中就会非常好用,这就像工业的流水线一样,把一些标准的表达固定,并且提高复用率,并且及时学习出现的好的表达方式,这能够提高中文整体的使用水平。
这种句子的检选,一是可以大范围的从使用者扩大,二是可以人机合作,“半人马” 式的捡选,这在人工智能运用傅立叶法模仿人类的今天,是一条可能不错的路。
这个问题您最好问一下搜狗输入法的王小川或者黑马神拼的王励,他们可能是目前该领域最为权威的专家
我觉得这是很好的方向,可以提高一些语言的复用率,不过我还在想,李氏方案中,对中文表达的优化的问题,法国好像对法语本身也有优化的尝试,这个思路如果发展起来,模块化的表达对于中文本身的发展,可能会产生影响,比如第一时间推荐的用词,用句,以及建构在这种用词用句上的习惯。但这种影响中文未来的发展方向的可能,感觉需要一些共同的研究者的研究。
具体来说,输入法在承担这些基础的输入功能之外,还可以依靠词库,还有数据分析,承担一些近义词,或者同义句推荐的功能。
这种功能,我看妙笔一类的软件有发展,但妙笔的句库明显非常的局限于网络小说,而且并没有好的拓展的眼光。
但如果顺着这个思路走下去的话,也许未来不同的职业会有不同的输入法软件,或者模块,模块会根据写作内容自动推荐, 和写作者互动,可以为一些需要写作重复内容的使用者提供个性化的备选服务。
智能创作助手 Effidit(Efficient and Intelligent Editing) 是由腾讯 AI Lab 开发的一个研究性原型系统,探索用 AI 技术提升写作者的写作效率和创作体验(在线体验推荐使用 Chrome 或 Microsoft Edge 浏览器)
https://effidit.qq.com/
这里是 52万的英文单词码表,有需要自己鼓捣吧
麻烦给个安装说明!
谢谢!
1.把压缩包的yaml文件解压并覆盖到 C:\Program Files (x86)\Rime\weasel-5.0.0.0\data文件夹
2.清空用户文件夹的输入方案配置
dos下执行
del /F /S /Q "%SYSTEMDRIVE%%HOMEPATH%\AppData\Roaming\Rime\*.*"
3. C:\Program Files (x86)\Rime\weasel-5.0.0.0\data\default.yaml
schema_list:
- schema: hongyan_pinyin_simp
- schema: hongyan_pinyin_simp_5bi
- schema: hongyan_pinyin_simp_abc
- schema: hongyan_pinyin_simp_ms
- schema: hongyan_pinyin_simp_flypy
- schema: hongyan_pinyin_simp_pyjj
- schema: hongyan_pinyin_simp_zrm
- schema: hongyan_pinyin_simp_tengxun
再添加一个
- schema: hongyan_english
保存文件
4. C:\Program Files (x86)\Rime\weasel-5.0.0.0\data\default.custom.yaml
patch:
schema_list:
- {schema: hongyan_pinyin_simp_wenyi}
改为
patch:
schema_list:
- {schema: hongyan_english}
保存文件
5.重新部署
太感谢了!
怪我没有说清楚,我用的是手机安卓系统。
那就是rime文件夹下作相应的修改
麻烦给个安卓系统安装说明。
安卓系统手机没法执行dos,就是没有清理原来设置,更改了patch后,切实可以打出英文联想词典,但是只是在原来的汉语输入状态下,可以使用,原来的英文设置状态下,只能一个字母一个字母的输入(跟原来输入相比没有变化)。
最关键的是,如何输入汉语(原来的汉语输入现在变成了英文联想)?
大师只能如此?
收到,感谢,很高兴看到这样的项目。
把英文码表提供出来是让你自己鼓捣
把 sometime
拆分成
sometime s 1
sometime so 2
sometime som 3
sometime some 4
sometime somet 5
sometime someti 6
sometime sometim 7
sometime sometime 8
就可以了
不过这样会让词库的大小膨胀几十倍
看上去想一想就能实现的功能,其实背后实现并不是那么容易的
Vim大神你好!现在想再次试一试“easy_en”。手机安卓系统可以吗?刚才查看#172,只看到Windows的。
原来的汉语输入,虽然显示汉语,但是已经变成“英文联想输入”。这个咋办?