





更为完备的词库需要安装2471万增强包。
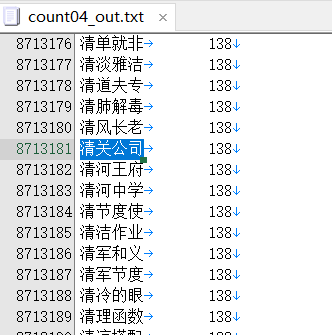
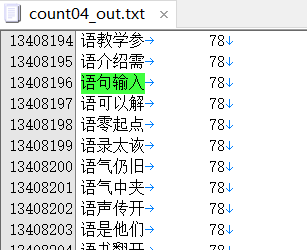
语句输入,清关公司 在四个字的排名比较靠后,一个是1340万,一个是871万。所以没有入选。
一般编译1GB的词库需要22GB的内存。没有办法,如果加入这两个词语,词典文件需要增大2.5倍,我的电脑只有32GB的内存,目前硬件不允许。目前增强版词库索引解压后有1.6GB,这个大小已经超过部分操作系统的大小的。如果内存允许,词库索引增加到64GB,我也是愿意的。
剩下一个不当词语的问题,目前的条件还没法处理,主要是人工成本太高。要是黑马校对给我一个免费的授权,就像当年谷歌输入法购买这款 软件用于词语校对,我还是乐意的。
2471万个词语,逐一校对需要的人力物力业余玩家承受不了。现代汉语词典也就5万多的词语,耗费了多少人力和财力。
追求完美,达到语义学上逻辑的完美,这可以理解。
这么完美的功能背后,是巨量的投入。废词只要影响不太严重,应该是可以忍受的。
可以估算一下,当年搜狗输入法为代表的智能拼音导致五笔用户数大量减少的现象,背后的投入只有王小川或者资深开发人员才知道。
人力校对的成本是很高的,作者愚钝,目前还没找到完美的中文分词算法,结巴分词的效果并不令人满意。
如果有一个高度可信的分词软件,次哭 会识别为 次/哭,这样的词语可以轻松剔除。
次哭只是一个简单的例子,这样的词语有几千万。
感谢您的评测,只能说,目前的选择,是没有办法中的办法。