刚看了一下Unicode15,CJK extH四千多字就认得一个

unicode15新增4,193汉字:扩展H区4,192个,C区一个2B739。
CJK Unified Ideographs Extension H(U31350-323AF).pdf (2.4 MB)
下个月出正式版,可能会有变动。先看看吧。
今天尝试从上面PDF制作ttf字体文件。
先从PDF文件提取单字,保存成PNG,然后往fontcreator导入。
除了能显示外,与好看无关。
4000多字,导入fontcreator真是麻烦事。
一开始,用按键精灵,慢且老出错。
这是个笨方法,被B站某视频严重误导。
批量导入图片到fontcreator最佳方法就是:拖放大法。
选择要导入的图片,拖到fontcreator,然后等着它处理完。
feiwu
2
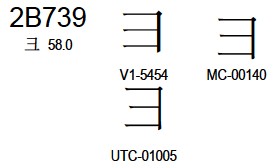
2b739这个和彐有什么区别?v和utc源没区别,只是多了mc,完全可以横向扩展啊。
大概是腿短和腿长吧~
彐,xuě,曾作“雪”的简化字,后停用。《汉语大字典》都没收录。
这个新增2B739,看上去和彐挺像的,就不知道啥意思。
据unihan readings
U+2B739 kVietnamese kẹ kệ。这么看来大概是读ke音吧。音不同,估计义也不同了。
瞧了一下,認出些說文的字頭。
有的是兼容字字形升級到標準字。像甾。
又有挺多類推簡體。
不知道大字典得替換多少私有區字。等WFG出替換表。
一大堆字典索引會被淘汰了呵呵。麻煩。
當時處理索引,如果添上準確私有區字或兼容字就好辦。如果只勉強添上字形接近但不準確的字,這群字頭就很難追究來更新。(這也是用兼容字平面2的好處;長期來看還是最佳。尤其是升級的兼容字,Unicode 總是會發替換表,可以一概更新。)
2B739 的 UTC-01005,看來是從 5F50 分出來的:這字形也標 UTC-01005。

正字通 分辨:
終於有這個字了,pretty cool。我已經更改了呵呵。出現在辭源二十幾次:
