(最新内容依次在最下面)
2022-08-13补充:
这里分享的不是mdx词典,而是pdf,txt等文件。这个字典或许叫做《部件组字速查手册》(Quick reference manual for chinese characters, classified by components not only by radicals)更贴切。这个手册最大的用途是,打印出来查阅、或作为pdf直接查询;它的主要服务对象或许是学习汉语的人员,学生等。关于部件检索,有很多专业的词典,但这个手册有其便利之处。
原帖: 2022-08-12
分享一个小字典,勉强算上是字典吧,分享源文件和成品pdf字典,pdf字典也就50多页而已。
人狠话不多,就直接上图和分享了。




适用人群:学习汉字、教授汉语人员。适合打印出来,马上、厕中、教桌上,随手翻看,或许有用。
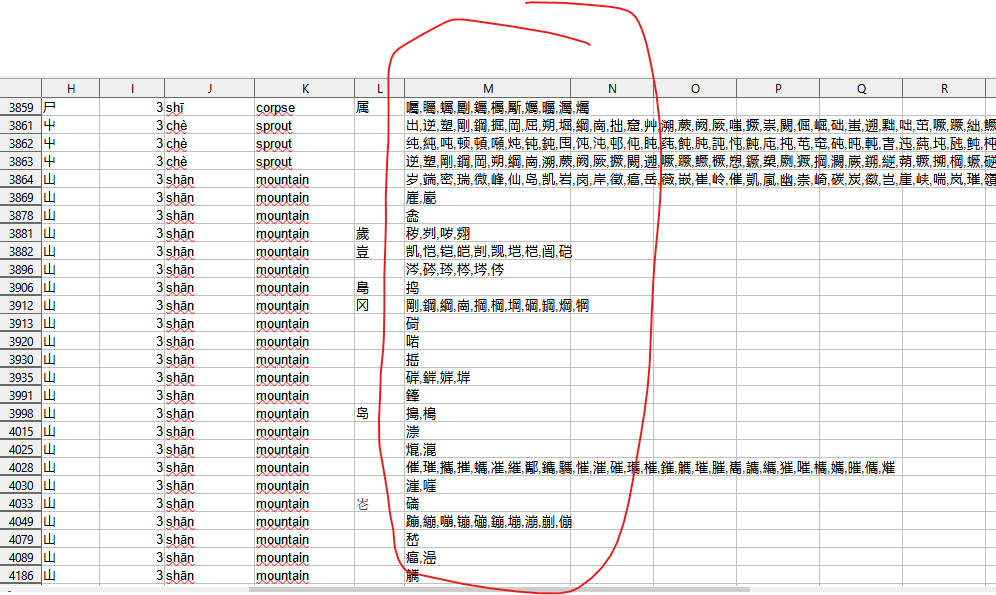
字典简介:以部件为单元,把含有同一个部件的汉字(常用汉字,大约6000多个)都列出来;传统上,比如大部分字典,一般是以部首(而不是部件)单位,把汉字列出来,这做有一定的局限性,比如,如果想找含有“甫”这个部件的汉字,在传统的字典好像不容易找出来。
花絮:提供过程中的源文件(xlsx,txt,doc等)下载。
局限:暂没有给汉字加释义。
额外馈赠:源文件xls和其他文件中,展示了一种思路,那就是如何用笨方法做自己的词典,具体来说就是,就是如何给自己的汉语词典加一个部首检字表。从这个角度出发,我们可以整理那些秀色可餐的词典,可以打印出来的,比如这个《学生字典》很有价值,又饱含情怀:WFG: 《學生字典》
(这里提及了这个学生字典》:https://forum.freemdict.com/t/topic/12434/2)

呼吁:谁能把《学生字典》整理成可打印、带有检字表的pdf版本啊?打印出来,不时翻阅,岂不美哉?期待有达人出手。
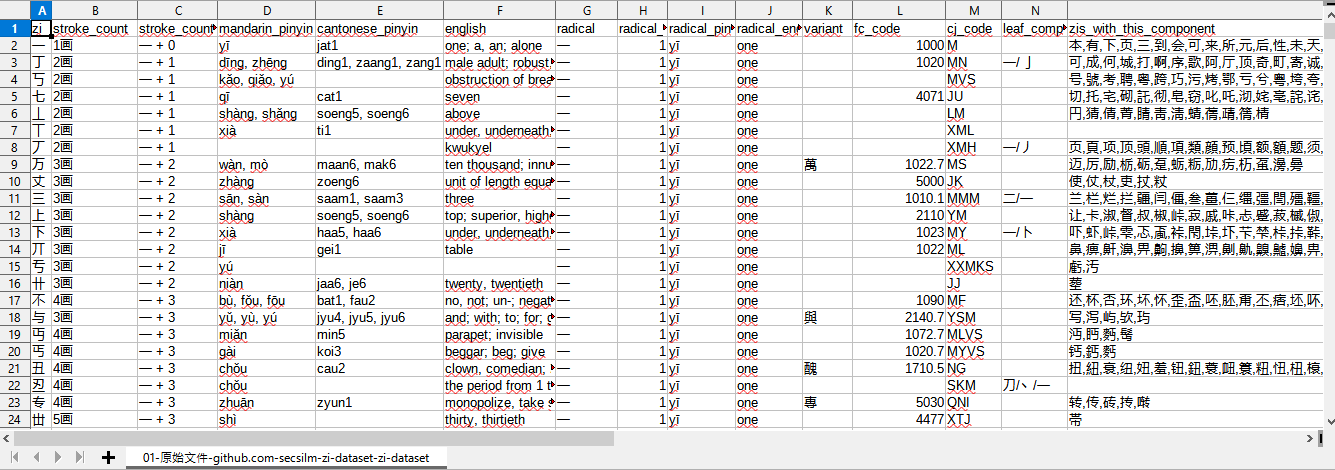
主要原始文件来源,并致谢:GitHub - secsilm/zi-dataset: 汉字数据集,包括汉字的相关信息,例如笔画数、部首、拼音、英文释义/同义词等。
2022-08-12,下载(这里的下载老旧了,下面有更多更新后的下载,请用最新的下载):
部件组字字典数据包.7z (2,9 MB)
压缩包内容:
| 01-原始文件-github.com-secsilm-zi-dataset-zi-dataset | csv | 2.1 M |
|---|---|---|
| 02-部件综合信息 | xlsx | 361.7 K |
| 03-生成word前的文本 | txt | 145.5 K |
| 04-word部件组字字典 | docx | 124.4 K |
| 05-输出-部件组字字典 | 3.1 M |
2022-08-13更新:
-
对于最终成果的odt和pdf,做了格式和形式上的修改。部件新增了拼音。
-
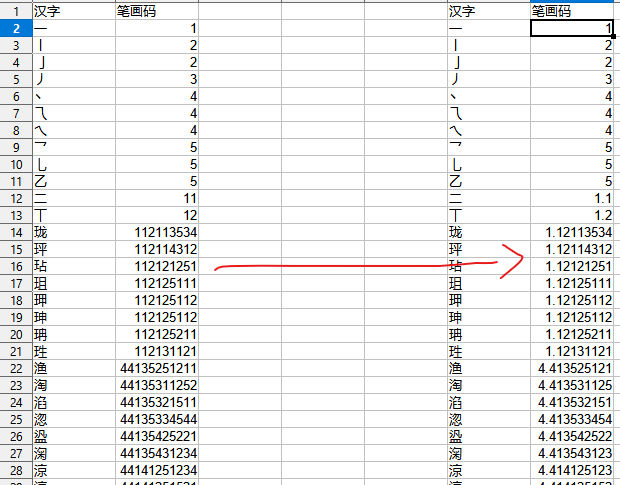
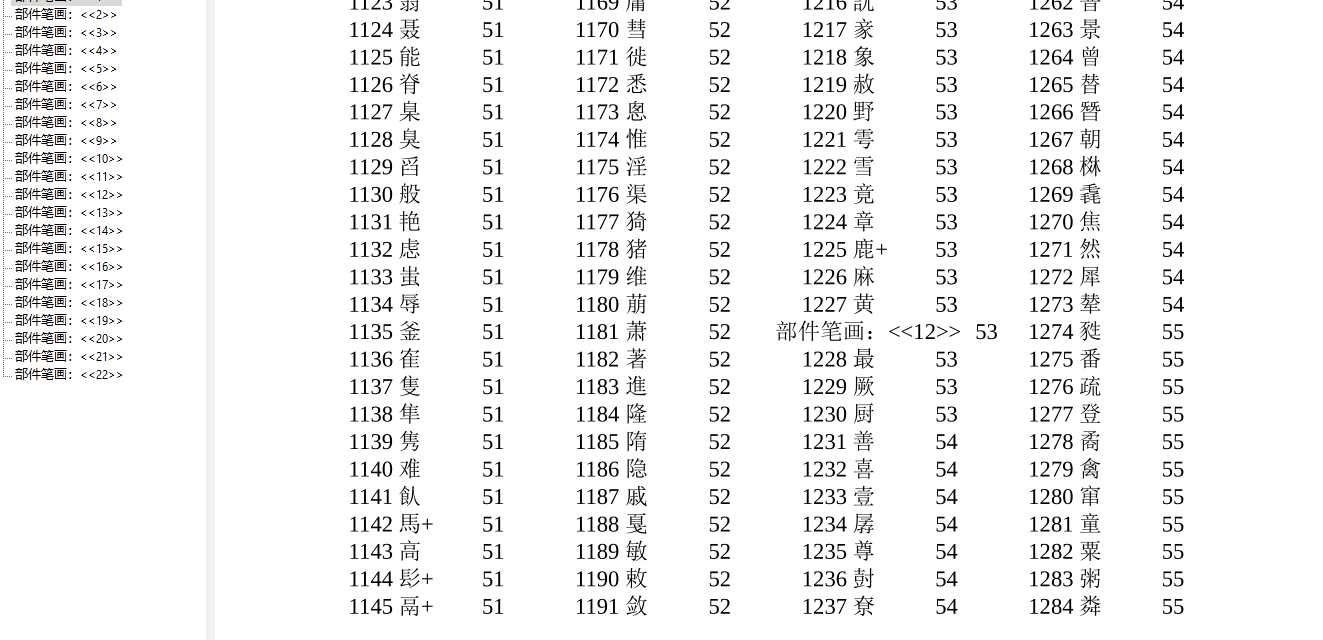
重要修改:在检字表部分,对于同一笔画下的部件,以前是随机排序的,现在按照笔画顺序(把横竖撇点折分别视为12345,好像很多中文字典也是这么排序的)进行重新排序,这样更方便查找。例如:9画的部件,有147个左右,如果没有按照笔画顺序排序,寻找一个部件是困难的。示意说明:
-
这个字典或许叫做《部件组字速查手册》(Quick reference manual for chinese characters, classified by components not only by radicals)更贴切。
-
这个手册有一些不完善的地方,如果有更好的数据源,或鄙人水平更高,或许可以做得更好,目前就这么用着吧。
-
关于更好地分享的倡议:为了更好的分享、造福社区,如果谁有什么成果,建议把源文件 、文本、过程文件、流程描述等也一并提供,方便他人再次利用。既然分享了,我们就分享地彻底些吧!
-
2022-08-13 下载1,各文件分散下载:
01-原始文件-github.com-secsilm-zi-dataset-zi-dataset.csv.7z (553,8 KB)
02-常用汉字表.txt (16,7 KB)
03-单手输入法笔顺码.xlsx (650,7 KB)
03-部件综合信息.xlsx (470,8 KB)
05-部件组字速查手册-生成word前txt文件.txt (159,6 KB)
06-成果-部件组字速查手册.pdf (3,2 MB)
06-成果-部件组字速查手册.odt.7z (113,6 KB) -
2022-08-13 下载2,所有文件打包下载(和上面文件内容一样,打包更方便):
部件组字速查手册.7z (3,4 MB)


2022-08-28更新
1,提供:
汉字偏旁部件组字速查手册-一二三级字表HSK版.pdf
汉字偏旁部件组字速查手册-一二三级字表.pdf
汉字偏旁部件组字速查手册-一二级字表.pdf
截图:
打包下载:
汉字偏旁部件组字速查手册-2022-0828.7z (15,5 MB)