想请教一下各位大佬,在词典txt处理中,不知是否可能将@@@=link 直接更改为跳转单词的释义,
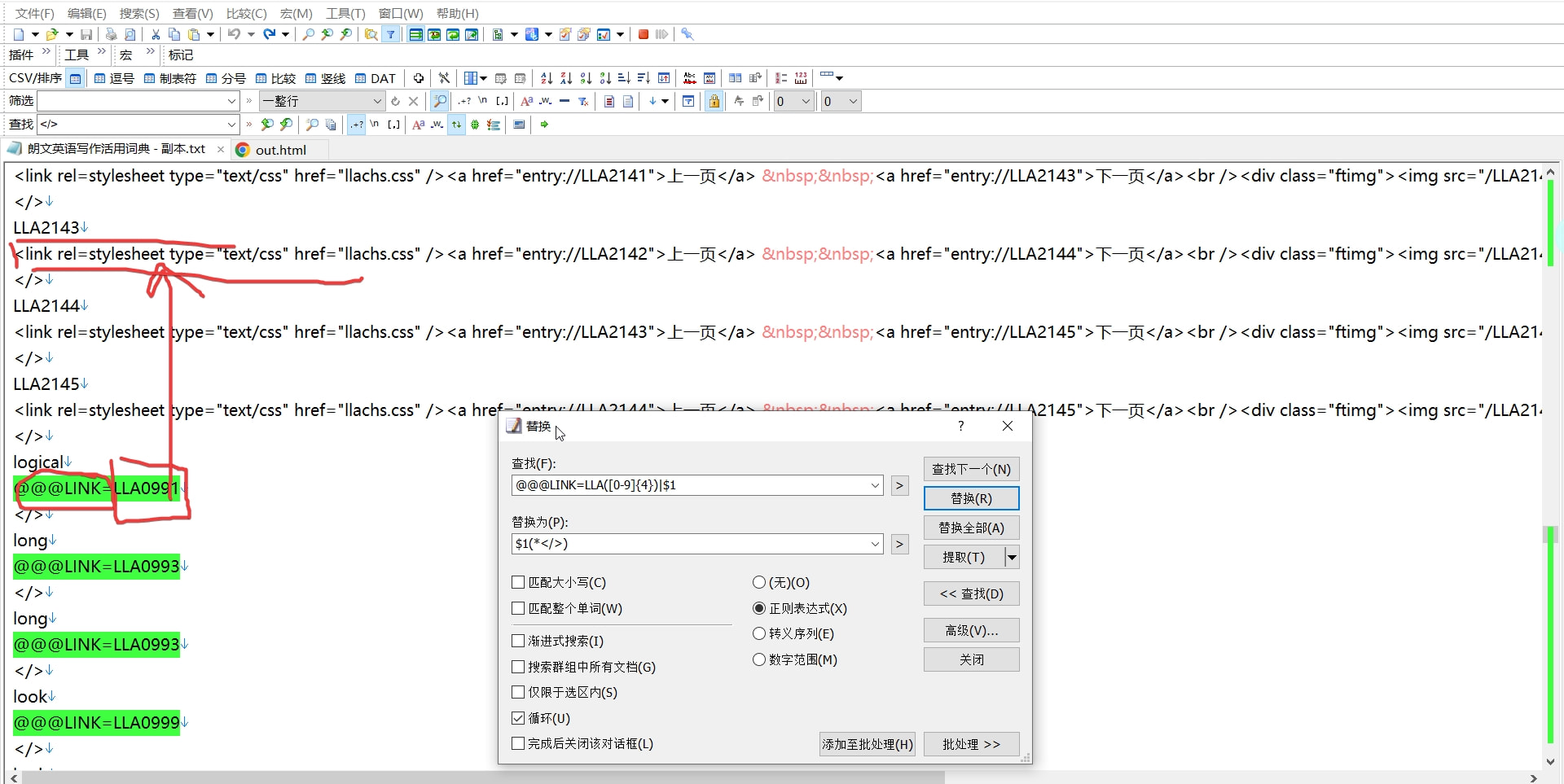
图片如上,希望
将@@@LINK=LLA0991替换为 LLA0991所对应的词条的释义。
希望能找到一个批量处理的方式
各处搜寻良久,也尝试过正则,但似乎替换内容不能用正则表达式来替代,不该如何是好,还请大佬不惜赐教
想请教一下各位大佬,在词典txt处理中,不知是否可能将@@@=link 直接更改为跳转单词的释义,
图片如上,希望
将@@@LINK=LLA0991替换为 LLA0991所对应的词条的释义。
希望能找到一个批量处理的方式
各处搜寻良久,也尝试过正则,但似乎替换内容不能用正则表达式来替代,不该如何是好,还请大佬不惜赐教
用正则肯定不行,用批量替换或者可以,但一般软件的批量替换或许有字数限制,可以试一下。
</>去掉\n去掉,使词头和释义在一行key,词头是对应的value(如mdict[‘LLA0999’]=‘look’)是不是直接在当前文件就跑就行:
遍历@@@ { >>> 提取词头 >>> 搜索词头对应的释义 >>> 把找到的释义插入当前@@@LINK=后}
遍历两边,第一遍获取正确词头和跳转词头(@@@那种类型)放到一个字典里面,第二遍处理跳转词头和释义同一行的数据(LLAXXX<link…)从字典里面找到LLLAXXX对应的正确词头,写入词头,写入释义,写入分隔符。
playboy版可否分享下?
好的,谢谢大佬
谢谢大佬细致的回复,虽然不会phthon,但也启发了我,或许可以用数据库试试,将@@@link清除掉就能连起来了
应该是图片版的,其它的不是找不到就是,,你懂的
将文本做成一词条一行;
将LINK前后互换;
选择好排序;
查找词头相同的上下两行,并让替换时复制原词条(较长的一行吧)
若想保留原文本顺序,可以在每行前加上编号。
这样做的话应该所有mdx都可以用相同的操作,您有没有写过通用的程序代码可以分享一下?
看到您之前从mdx制作过Mac词典,应该有研究过这个
排序这一步,用什么工具好呢?
请问这么做的意义何在?
这应该是一个简便方案 ![]()
一般确实没什么意义~
但有些情况有需要,像我后面说的,制作Mac词典,因为Mac词典常常用于三指取词,考虑变形很重要。从mdx转的Mac词典没有mdx的一些特性,需要手动处理link等情况。如果遇到多重引用更是麻烦。
(我也想问楼主这么做的意义何在)
大概写了个脚本,可惜是 js的,跑了下还行,python好久不用忘差不多了,可以请python大神出手看看
content = "\r\n" + content + "\r\n"; // 当前文本文件的完整内容
var myEntry = ""; // 一个词头
var myContent = ""; // 一条释义
while (content.match(/\r\n@@@LINK=.+\r\n/) != null) {
myEntry = content.match(/\r\n@@@LINK=.+\r\n/)[0];
myEntry = myEntry.replace(/@@@LINK=/g, '');
myEntry = myEntry.replace(/\r\n/g, '');
myContent = content.match(RegExp('\r\n' + myEntry + '\r\n.+\r\n', ''))[0];
myContent = myContent.replace(RegExp('\r\n' + myEntry + '\r\n', ''), '\r\n');
content = content.replace(/\r\n@@@LINK=.+\r\n/, myContent);
}
# -*- coding: utf-8 -*-
# 开发团队:
# 开发人员:Lenovo
# 文件名称:modifier2.0.py
# 开发工具:PyCharm
code = input("请输入编码方式:")
source = open('input.txt', 'r', encoding=code)
source_text = source.read()
source.close()
source_list = source_text.split('</>')
dic_list = []
text_list = []
for item in source_list:
if '@@@' in item:
text_list.append(item)
else:
dic_list.append(item)
text_content = '</>'.join(text_list)
dic = open('dic.txt','w+',encoding=code)
dic.write('</>'.join(dic_list))
dic.seek(0,0)
pydict={}
count = dic.read().count('</>')
dic.seek(0,0)
for i in range(count):
word = dic.readline().rstrip()
number = word
meaning = ''
while 1:
single_line = dic.readline()
if single_line.strip() != '</>':
meaning += single_line
else:
break
pydict[number]=meaning
for number,meaning in pydict.items():
if number in text_content:
text_content = text_content.replace('='+number,meaning)
text_content=text_content.replace('@@@LINK','')
dic.close()
output = open('output.txt','w+',encoding=code)
text_content = text_content.replace('\n\n','\n')
output.write(text_content)
output.close()
写了一个Python程序,但是如果txt太大运行起来贼慢。请教大佬如何重构代码。
我的脚本这么简单,你就不能看看批评一下? ![]()
这步很耗资源吧
或许for item in source_list:这里就制作好pydict比较好,可以用split('\n')代替后面的readline(),因为读写也很花时间。同时对于text_list也制作一个pydict2。然后两层循环,用pydict里的东西替换pydict2的@@@link=xxx内容。最后把pydict,pydict2一起写到输出文件就行了。
python的词典不知道能不能排序,如果能那查找能再快一点。
纯意淫,我python也忘光了 ![]()