为什么你认为编码有误呢?
Tim Teeman, Jude Law and the Great Male ��… (May 19, 2014)
� 这个符号的码位的是 U+FFFD,表示文本替代符,编码转换失败的时候会用这个符号代替。
能共享一下您用的工具吗?多谢了
1 个赞

那是你没有配置好vim,FYI:

" Encoding related --------------------------------------------------------{{{1
set encoding=utf-8 "Vim 内部工作编码
set fileencoding=utf-8 "设置此缓冲区所在文件的字符编码;新文件默认编码
" 打开文件时自动尝试下面顺序的编码
set fileencodings=ucs-bom,utf-8,cp936,gb18030,big5,euc-jp,euc-kr,latin1
source $VIMRUNTIME/delmenu.vim
set langmenu=zh_CN.UTF-8 "指定菜单语言,若需要英文则none
source $VIMRUNTIME/menu.vim
language message en_US.ISO_8859-1 "指定提示信息语言
" language message zh_CN.UTF-8 "指定提示信息语言
set ambiwidth=double "使用US-ASCII字符两倍的宽度显示宽度不明的字符
set nobomb "取消UTF的BOMB文件头
set ffs=unix,dos,mac " 文件换行符,默认使用 unix 换行符
set cm=blowfish2 "设置新的加密算法
多谢您的帮助,能发一下文字版吗,我copy一下,多谢了
还得再麻烦一下,怎么设置呢,没玩过它
劝退 ![]() 没有十天半个月,新人搞不定。
没有十天半个月,新人搞不定。
找你熟悉的编辑器,配置好它们应该都能解决问题。
好吧,多谢了
请教一下,您知道选择哪个编码集打开吗
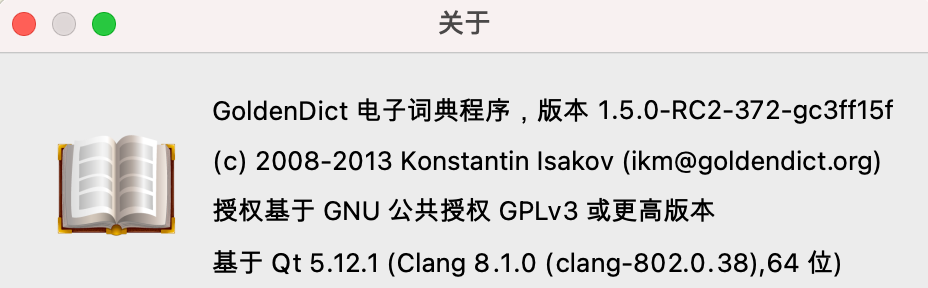

上面截图使用的是Qt 5.12.1的版本,这版本直接去掉了编码错误的地方,我看你用的是GoldenDict的Qt 5.12.3版本,两个小版本的差距不应该如此巨大,可能不是同一个源下载的词典?方便看下md5对比下吗?
MD5 (Dictionary.com Unabridged, 2016.mdx) = bbcd587267a927f566884407d3a1de0e
非常感谢大家的热心帮助,尤其是Vim和last_idol的帮助。我想大概找到方案和可能的原因了。主要原因是文件的编码为UTF8-BOM格式,而明显欧陆和preview在该编码的兼容上有一定的问题,而emeditor原生是不支持该编码的,幸好有sublime-text(本人的水平有限)。另存为UTF-8,再重新打包就好了。祝热心的各位晚安。
不是噢,preview支持utf-8 bom,preview会先使用utf-8 bom解码,失败后再使用utf-8解码。我使用了三个版本的goldendict同样解码失败了。你导出的文本编码和词典内置编码不是一回事。只能说你导出的文本,使用sublime-text帮你转码成功了。
你说的有道理,很有可能原文件不是utf-8 bom的,但肯定不是utf-8,所以关键是转成utf-8再打包,我指对欧陆而言。不过好在问题解决了,用欧陆和preview都能正常显示了。很感谢你哦!
可以这样认为,mdict-utils导出的文本是utf-8编码,mdxexport导出的文本是utf-8 bom编码。其实这两编码是一回事,只有头部的编码有差别,有bom的编码会多出一个U+FEFF码位,对乱码是无帮助的。有帮助的是sublime-text转码的时候,把错误的码位帮你修复了。
你说的有点深奥,我不太懂,我是门外汉,所以我想你说的应该是对的。很感谢哦!
1 个赞
原词典是utf-8的,只是里面掺杂了别的编码的字符,导致解码失败。sublime-text解码的时候应该是尝试了多种解码,处理了乱码问题,词典软件不会这样处理,至少goldendict不会。
有道理,刚想起来,mdxbuilder设置正常应该是utf-8的。认可你的判断