本版已停止维护,请改用 Accelon22版
纯 HTML+CSS+ES6 软件,解开软件包打开 index.html 即可运行。
软件包 5MB (先试Github)
2022-05-27 第一个公开版
2022-05-28 补上反对本本主义 英译,修正重复显示平行文本题目问题。
本版已停止维护,请改用 Accelon22版
纯 HTML+CSS+ES6 软件,解开软件包打开 index.html 即可运行。
软件包 5MB (先试Github)
2022-05-27 第一个公开版
2022-05-28 补上反对本本主义 英译,修正重复显示平行文本题目问题。
自己做的吗,很不错
叶大?是Accelon的作者本人吗?热烈欢迎!!!
好强大,太厉害了。
咦?熟人?
闭门造车太久,我今天才知道有这个论坛。
不是,小弟也在做全文检索这块,有关注过Accelon,仰慕很久了,看过叶大总结的早期古籍检索的发展历程和心得,还有一些易符科技的片段资料,对各位前辈在中文检索领域的拓荒十分敬佩。另外小弟还看过叶大在Forth社群研讨会上的视频,虽然没什么相关内容。。
这个论坛氛围开放,有很多语言类爱好者,中文词典的作者也有不少,软件作者也有几位在,欢迎叶大常驻!
这些资料我爹娘都没看过,还不算熟人? ![]()
台湾年青一代没有挑战西方标准的心气,
以社会主义情怀在搞古籍的也都慢慢凋零了,
数字古籍的未来只能靠新中国,我很乐意与诸位志士交流分享。
有方法提取中文和对应的英文(组成中文英文pair方便制作其他格式词库)吗,看源码里好像所有中文堆在一起,不知道每句中文是怎么匹配对应的英文的 ![]() 感觉好神奇
感觉好神奇
虽然中英文的数据库分开建置,但两者的行号是一致的,所以容易逐句对应。
请看 源文件 ,a1.zh.off 原文, a1.en.off 第一册英译,总行数一致,一句一行。
句子层级对齐之後,逐词对应 当可自动化(先用既有的中英词库过一遍,词库没收的人名地名也很容易用统计方法找出来 ),有算力的朋友可以喂给机器学习软件试试。
超过350字的段落我都切分了,理想是80~100字以上都切分,让对读更清爽,但工作量太大,有沒有党员愿意认领这个工作?
太有心了,谢谢你的分享。
不知道有没有方法可以把数据导出为 一句中文后面紧跟着一句英文的格式 ![]()
类似下面这种:
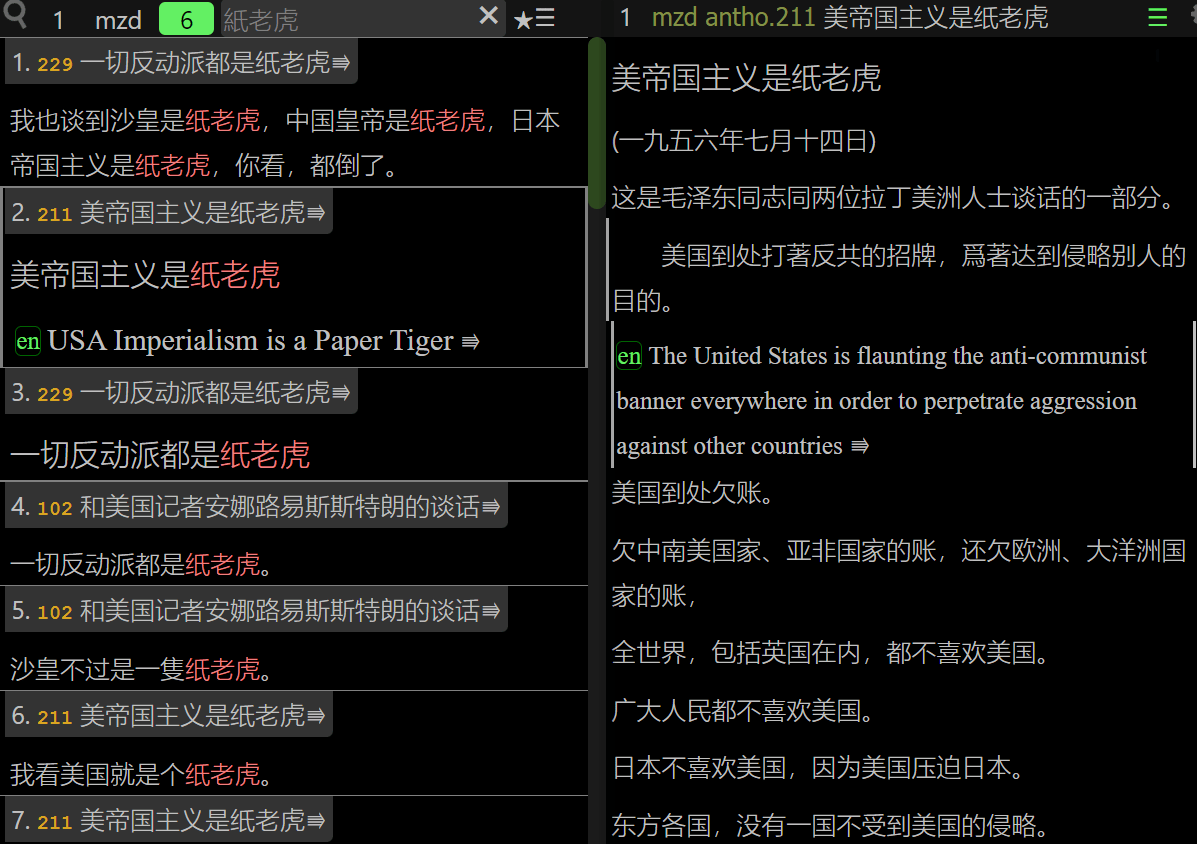
誰是我們的敵人?誰是我們的朋友?這個問題是革命的首要問題。
Who are our enemies? Who are our friends? This is a question of the first importance for the revolution.
中國過去一切革命鬥爭成效甚少,其基本原因就是因為不能團結真正的朋友,以攻擊真正的敵人。
The basic reason why all previous revolutionary struggles in China achieved so little was their failure to unite with real friends in order to attack real enemies.
就是说,从原始中英文分离的数据中导出一种中英文合并的格式,方便制作其他词库格式,比如MDX之类的
可用 API 的方式 dump 出数据,範例如下:
accelon大神,您的accelon软件以前用过。真是惊艳,速度快,太完美了。除了相关资料少。就不知道为何不继续开发了。检索功能太好用了。
如果时间允许,恳请大神继续开发完善。因为网页版还是感觉差点意思。一句话,功德无量,祝大神好人一生平安。
Accelon3 是用Delphi 写的,当年跨台平的支持不理想。Accelon3 2005 之後就没有加新功能了,会活那麽久坦白說我非常意外(原因可能是我对微软的花式框架很抗拒,坚持只用最基本的API)。
另外我误判网页程序很快就可以完全取代桌机版,所以从2010开始就全面转向 Nodejs。
但经过那麽多年看来,不依赖网路的本地版还是有其价值,网路再怎麽方便,还是不如将数据放在本地安心和快迅。Nodejs 运行速度已经很接近 Delphi ,但内存的开销是好几十倍,而且由於本地文件读取的种种限制,无法像Delphi那样充分搾取系统的能力。
内存开销大、响应慢等网页版的问题,会随着时间慢慢解决。我想专注於「不随着硬件发展而能够自然解决」的问题。
对骨灰级码农而言,关心的重点已经不是程序的速度,而是停止施肥浇水,它能够存活多久。
(纯)网页版最大的好处是有极强的向后兼容性,30年前写的html+js+css 到现在还打得开,因此依附在其上的数据也可以苟活下来,只要活下來,就有希望。
欢迎多多技术交流。
技术之外的,可以 agree to disagree. 在网络上辩论劳而无功,不如其乐融融,“四海之内皆兄弟也”。
哈哈,果然是骨灰级码农。微软的聪明人太多,新上台的项目主管往往都要另起炉灶make a difference,导致开发者苦不堪言。
超英赶美、日韩服小,只是时间问题,但伟大的复兴之后呢?如何让数以亿计识字又有本事的人,找到安身立命的所在?
这样的格式,可以用使用北大的paraconc,这个程序就是需要这样子的本地文本作为语料库的资料。
执行node mzd-datadump.js的时候,提示下面的错误:
node:internal/errors:465
ErrorCaptureStackTrace(err);
^
Error [ERR_MODULE_NOT_FOUND]: Cannot find package 'pitaka' imported from /Users/xxx/Downloads/毛泽东选集 mzd-2022-05-28/mzd-datadump.js
at new NodeError (node:internal/errors:372:5)
at packageResolve (node:internal/modules/esm/resolve:954:9)
at moduleResolve (node:internal/modules/esm/resolve:1003:20)
at defaultResolve (node:internal/modules/esm/resolve:1218:11)
at ESMLoader.resolve (node:internal/modules/esm/loader:580:30)
at ESMLoader.getModuleJob (node:internal/modules/esm/loader:294:18)
at ModuleWrap.<anonymous> (node:internal/modules/esm/module_job:80:40)
at link (node:internal/modules/esm/module_job:78:36) {
code: 'ERR_MODULE_NOT_FOUND'
}
要先 npm i pitaka
好的。又通过 npm i provident-pali 安装了provident-pali,然后运行node mzd-datadump.js 又提示下面的错误:
import {samecount} from 'provident-pali'
^^^^^^^^^
SyntaxError: The requested module 'provident-pali' does not provide an export named 'samecount'
at ModuleJob._instantiate (node:internal/modules/esm/module_job:128:21)
at async ModuleJob.run (node:internal/modules/esm/module_job:194:5)
at async Promise.all (index 0)
at async ESMLoader.import (node:internal/modules/esm/loader:385:24)
at async loadESM (node:internal/process/esm_loader:88:5)
at async handleMainPromise (node:internal/modules/run_main:61:12)