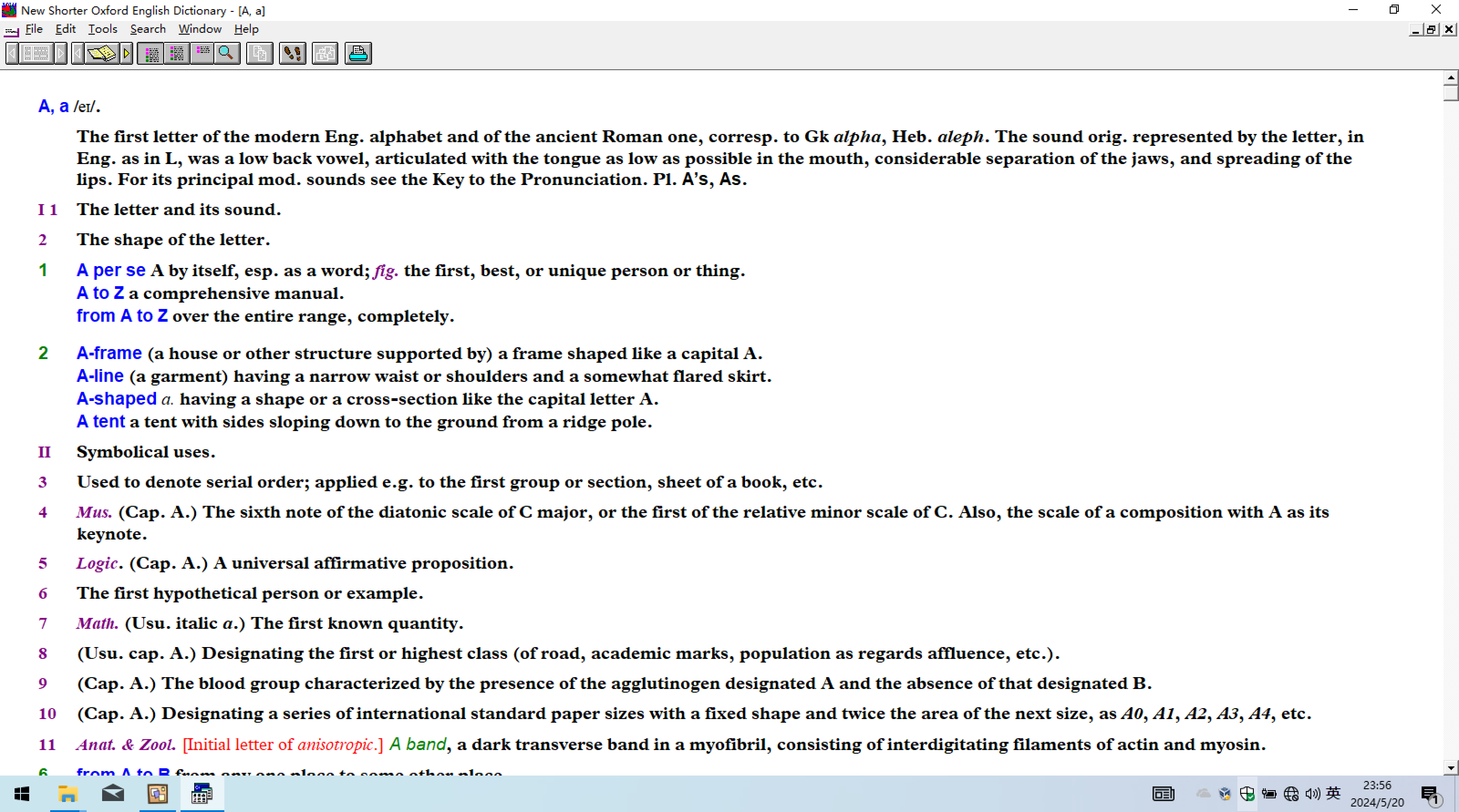
- 第4版以后才有电子数据
- exe_1.0 版 在 libgen
- Oxford Talking dictionary 里面还有一份数据
- 第5版,即 exe_2.0版,在 libgen
- 第6版
- 官网更新包
- wordweb + bundle(有发音)
有兴趣的朋友可以做做融合版,把历年修改的数据做个对比。
有兴趣的朋友可以做做融合版,把历年修改的数据做个对比。
说到英语词典,我是外行。作为常识去了解,搜了一下,贴个简介。
OED太大了,没多少人能善用吧。SOED会比较多人使用。
Shorter Oxford English Dictionary
Wikipedia
The Shorter Oxford English Dictionary (SOED) is an English language dictionary published by the Oxford University Press. The SOED is a two-volume abridgement of the twenty-volume Oxford English Dictionary (OED).
一本词典一个宇宙:英语词典最全推荐
搜狐,2017-10-20
(Oxford University Press)
《简编牛津英语大词典》(SOED)是《牛津英语大词典》(OED)的精简本,是一本经典的历时词典,释义从词源开始,追根溯源,由古及今,权威解读每个英语单词的前世今生。它用OED十分之一的篇幅,收录了三分之一的内容,将1700年之后的英语单词尽收囊中。Simon Winchester曾评价说,“OED是珠穆朗玛峰,SOED就是马特洪峰”。是山峰自然会高大,两大册,拿在手里有点沉哦!
OED, COD, SOED各有千秋,全赖主编的功力,大师殒没后,词典编纂方式趋同反倒没什么特色了。牛津找人编撰SOED的时候,OED只出版到S,所以SOED和OED还是有很多不同的,当然也借鉴了后者不少。那个SOED+Oxford Talking 的高清图片替换的版本值得收藏。
世界变了,词典编撰行业没落了,牛津也不例外。
牛津官网提供升级包,SOED可以升级到第6版,但前提是你得有词典安装程序:
只能在32位系统里安装。我印象中光盘制作水准上乘,有两种查词模式可选,分别对应SOED和COD的结果,想看看COD8的,也算是曲线用上了。
对应SOED v3.0,我只在隔壁看到有人展示过。
本坛仓库里有v2.0的镜像,凑合着用吧。
求教:哪个版本的SOED里有这个词?检查了pdf没发现有
多谢二位![]() !
!
恭喜你成功安装!很多年前我也鼓捣过,一波回忆杀 ![]()
@HelloDict 来这聊 SOED
主要没有源数据,只有 mdx,加工过程中添加了错误、比如循环引用,还比如正则误伤(我估计没用 html tree 节点进行选择)。
这样那样的问题,导致精品想美化、修正,还夹在着各种问题。所以最好从源头数据和 mdx 是如何处理的都公开,而不是只公开最后结果的 mdx,难以回退。
词典我不懂,mdx是最终的成品?这个mdx是SOED官方做的吗?这个mdx成品也是有错误的吗?
比如 SOED 官方的 PC 数据,破解程度只有文字,然后文字可能是私有的格式,然后要修改数据,删原先的标签、判定语义内容加HTML标签区分为释义、子释义、例句、斜体等,改成 HTML ,再打包成 mdx.
比如 SOED6 的源数据 官方 PC 版就有问题,官方自己都加错了标签。
然后确定 headword 相互的跳转。(多个 headword 指向 最后的内容时,形成有向图,但循环指向导致有的词典会崩溃(不断的加载更多的内容)SOED5 的处理)
如果有了源数据,可以从头开始分析最准确的结构,css的标记会边界分明不互相影响。
你之前在另外一个帖子提到有拼接错误,这个拼接错误应该好处理。
最后的 mdx 可以回退到 txt 的,可以参考这篇帖子,很简单, 新手指南:怎样编辑mdx? 文本编辑器可以看看这个帖子 强大的文本编辑器 Emurasoft EmEditor Professional v20.5.6(2021.2.25更新) 文本编辑器可以看看23楼推荐的更新版,我跟着教程做了下,下载3个应用程序,用其中的一个程序把 mdx 变为 txt ,mdx编辑这个很好搞的。
对的,mdx 能 回退到 txt。
txt 提取 </> 之后的第二行到下一个 </> 可以提取出 纯 HTML 数据。但是这个 HTML 一般经过多个作者的正则修改增改标签,方便定制css,而非纯原始数据的 HTML ,这个过程中数据更美观了,错误也难以回退了。
我现在在试试直接从官网获得数据怎么样
SOED4_exe_v1.0
{\rtf1\ansi
\deftab0 \notabind
\pgwsxn23730 \marglsxn0 \margrsxn0
{\fonttbl
{\f222 \fnil Times New Roman;}
{\f0 \fnil Arial OUP;}
{\f1 \fnil Plantin OUP;}
{\f2 \fnil Times New Roman Phonetics;}}
{\colortbl
\red0 \green0 \blue0;}
\f222 \cf0 \b0 \i0 \ul0 \up0 \dn0 \nosupersub \scaps0 \ql \fi0 \li0 \ri0 \sb0 \sa0 \v0 \fs24 \par
\f0 \b \nosupersub \fi-627 \li1254 \ri1254 \sb100 \tx1260 \fs28 A, a
\f1 \b0 \nosupersub /\f2 \nosupersub eI\f1 \nosupersub /\b \nosupersub .\par
\f222 \nosupersub \sb150 \tx1260 \nosupersub \tab \f1 \nosupersub The first letter of
\nosupersub the modern Eng. alph\nosupersub abet and of the anci
\nosupersub ent Roman one, corre\nosupersub sp. to Gk \i \nosupersub alpha
\i0 \nosupersub \nosupersub , Heb. \i \nosupersub aleph\i0 \nosupersub
\nosupersub . The sound orig. re\nosupersub presented by the let
\nosupersub ter, in \nosupersub Eng. as in L\nosupersub , was a low back v
\nosupersub owel, articulated wi\nosupersub th the tongue as low
\nosupersub as possible in the \nosupersub mouth, considerable
\nosupersub separation of the ja\nosupersub ws, and spreading of
\nosupersub the \nosupersub lips. For its p\nosupersub rincipal mod. sounds
\nosupersub see the Key to the \nosupersub Pronunciation. Pl.
\f0 \nosupersub A抯\f1 \nosupersub \nosupersub , \f0 \nosupersub As
\f1 \nosupersub \nosupersub . \par
\f222 \nosupersub I \nosupersub 1
\nosupersub \tab \f1 \nosupersub The letter and its s\nosupersub ound
\nosupersub .\f0 \nosupersub \v \nosupersub \f1 \nosupersub \f222 \i \nosupersub
\nosupersub \f1 \i0 \nosupersub \f0 \nosupersub \sb10 \tx1260
\f1 \nosupersub \f0 \nosupersub \f1 \nosupersub \par
\f222 \nosupersub \sb150 \v0 \tx1260 2
\nosupersub \tab \f1 \nosupersub The shape of the let\nosupersub ter.
\f0 \nosupersub \v \nosupersub \f1 \nosupersub \nosupersub \f0 \nosupersub \sb10 \tx1260
\f1 \nosupersub \f0 \nosupersub \f222 \b0 \i \nosupersub \f1 \b \i0 \nosupersub
\f0 \nosupersub \f1 \nosupersub \nosupersub \par
\f0 \nosupersub \sb150 \v0 \tx1260 1
\nosupersub \tab \nosupersub A per se \f1 \nosupersub A by itself, esp. as
\nosupersub a word; \f222 \i \nosupersub fig.\nosupersub \f1 \i0 \nosupersub the first, best, or
\nosupersub unique person or thi\nosupersub ng.\par
\f0 \nosupersub \sb10 \tx1260 \tab
\nosupersub A to Z \f1 \nosupersub a comprehensive manu\nosupersub al.\par
\f0 \nosupersub \tab \nosupersub from A to Z \f1 \nosupersub over the entire rang
\nosupersub e, complete\nosupersub ly.\par
\f0 \nosupersub \sb250 \tx1260 2
\nosupersub \tab \nosupersub A-frame \f1 \nosupersub (a house or other st
\nosupersub ructure supported by\nosupersub ) a frame shaped lik
\nosupersub e a capital A.\par
\f0 \nosupersub \sb10 \tx1260 \tab
\nosupersub A-line \f1 \nosupersub (a garment) having a\nosupersub narrow waist or sho
\nosupersub ulders and a somewha\nosupersub t flared skirt.\par
\f0 \nosupersub \tab \nosupersub A-shaped \f222 \b0 \i \nosupersub a.
\f1 \b \i0 \nosupersub having a shape or a \nosupersub cross-section like t
\nosupersub he capital \nosupersub letter A.\par
\f0 \nosupersub \tab
\nosupersub A tent \f1 \nosupersub a tent with sides sl\nosupersub oping down to the gr
\nosupersub ound from a ridge po\nosupersub le.\par
\f222 \nosupersub \sb150 \tx1260 II
\nosupersub \tab \f1 \nosupersub Symbolical uses.\par
\f222 \nosupersub 3
\nosupersub \tab \f1 \nosupersub Used to denote seria\nosupersub l order; applied e.g
\nosupersub . to the first group\nosupersub or section, sheet o
\nosupersub f a book, etc.\par
\f222 \nosupersub 4 \nosupersub \tab
\i \nosupersub Mus.\nosupersub \f1 \i0 \nosupersub (Cap. A.) The si
\nosupersub xth note of the diat\nosupersub onic scale of C majo
\nosupersub r, or the first of t\nosupersub he relative minor sc
\nosupersub ale of C. Also, the \nosupersub scale of a compositi
\nosupersub on with A as its \nosupersub key\nosupersub note.\par
\f222 \nosupersub 5 \nosupersub \tab \i \nosupersub Logic\f1 \i0 \nosupersub . (Cap. A.) A univer
\nosupersub sal affirmative prop\nosupersub osition.\par
\f222 \nosupersub 6
\nosupersub \tab \f1 \nosupersub The first hypothetic\nosupersub al person or ex
\nosupersub ample.\f0 \nosupersub \v \nosupersub \f1 \nosupersub \par
\f222 \nosupersub \v0 7 \nosupersub \tab \i \nosupersub Math.
\nosupersub \f1 \i0 \nosupersub (Usu. italic \i \nosupersub a
\i0 \nosupersub \nosupersub .) The first known q\nosupersub uantity.\par
\f222 \nosupersub 8 \nosupersub \tab \f1 \nosupersub (Usu. cap. A.) Desig
\nosupersub nating the first or \nosupersub highest class (of ro
\nosupersub ad, academic marks, \nosupersub population as regard
\nosupersub s aff\nosupersub luence, etc.).\f0 \nosupersub \v
\nosupersub \f222 \i \nosupersub \nosupersub \f1 \i0 \nosupersub
\f0 \nosupersub \sb10 \tx1260 \f1 \nosupersub \f222 \i \nosupersub
\nosupersub \f1 \i0 \nosupersub \f0 \nosupersub \f1 \nosupersub
\nosupersub \f0 \nosupersub \f222 \i \nosupersub \nosupersub
\f1 \i0 \nosupersub \par
\f222 \nosupersub \sb150 \v0 \tx1260 9
\nosupersub \tab \f1 \nosupersub (Cap. A.) The blood \nosupersub group characterized
\nosupersub by the presence of t\nosupersub he agglutinogen desi
\nosupersub gnated A a\nosupersub nd the absence of th\nosupersub at designated B.
\f0 \nosupersub \v \nosupersub \f1 \nosupersub \f0 \nosupersub \sb10 \tx1260
\f222 \b0 \i \nosupersub \f1 \b \i0 \nosupersub \nosupersub \par
\f222 \nosupersub \sb150 \v0 \tx1260 10 \nosupersub \tab \f1 \nosupersub (Cap. A.) Designatin
\nosupersub g a series of intern\nosupersub ational standard pap
\nosupersub er sizes with a fixe\nosupersub d shape and twice th
\nosupersub e area of the next s\nosupersub ize, as \i \nosupersub A0
\i0 \nosupersub \nosupersub , \i \nosupersub A1\i0 \nosupersub
\nosupersub , \i \nosupersub A2\i0 \nosupersub \nosupersub ,
\i \nosupersub A3\i0 \nosupersub \nosupersub , \i \nosupersub A4
\i0 \nosupersub \nosupersub , etc.\par
\f222 \nosupersub 11
\nosupersub \tab \i \nosupersub Anat. & Zool.\nosupersub \f1 \b0 \i0 \nosupersub [Initial letter of
\i \nosupersub anisotropic\i0 \nosupersub \nosupersub .] \b \nosupersub
\f0 \b0 \i \nosupersub A band\f1 \b \i0 \nosupersub \nosupersub , a dark transverse
\nosupersub band in a myofibril,\nosupersub consisting of inter
\nosupersub digitating filaments\nosupersub of actin and myosin
\nosupersub .\par
\f0 \nosupersub 6 \nosupersub \tab \nosupersub from A to B
\f1 \nosupersub from any one place t\nosupersub o some other place.\par
\f0 \nosupersub \sb250 \tx1260 8 \nosupersub \tab \nosupersub A No. 1
\f222 \i \nosupersub US colloq.\nosupersub \f1 \i0 \nosupersub excellent, first-rat
\nosupersub e.\par
\f0 \nosupersub \sb10 \tx1260 \tab \nosupersub A 1
\f1 \nosupersub in Lloyd抯 Register \nosupersub of Shipping, used of
\nosupersub ships in first-clas\nosupersub s condition as to hu
\nosupersub ll (A) and stores (1\nosupersub ); \f222 \i \nosupersub colloq.
\nosupersub \f1 \i0 \nosupersub excellent, first-rat\nosupersub e.\par
\f0 \nosupersub \tab \nosupersub A-side \f1 \nosupersub (the music of) the m
\nosupersub ore important side o\nosupersub f a gramo\nosupersub phone record.\par
\f0 \nosupersub \tab \nosupersub A Special \f222 \i \nosupersub Hist.
\nosupersub \f1 \i0 \nosupersub a member of a full-t\nosupersub ime special police f
\nosupersub orce in Northern Ire\nosupersub land.\par
\f0 \nosupersub \sb250 \tx1260 9
\nosupersub \tab \nosupersub AB \f1 \nosupersub the blood group char
\nosupersub acterized by the pre\nosupersub sence of both A and
\nosupersub B agglutinogens.\par
\f0 \nosupersub \sb10 \tx1260 \tab
\nosupersub ABO \f222 \b0 \i \nosupersub a. \f1 \b \i0 \nosupersub designating or perta
\nosupersub ining to the system\nosupersub in which blood is d
\nosupersub ivided into four typ\nosupersub es (A, AB, B, and O)
\nosupersub on the basis of the\nosupersub presence or absence
\nosupersub of \nosupersub certain inherite\nosupersub d antigens.\par
\f222 \nosupersub \sb150 \tx1260 III \nosupersub 12 \nosupersub
\f1 \nosupersub Abbrevs.: (A small s\nosupersub election only is giv
\nosupersub en here. Those all i\nosupersub n caps. or small cap
\nosupersub s. also occur with a\nosupersub full\nosupersub stop after each let
\nosupersub ter; some of those a\nosupersub ll in caps. also
\nosupersub occ\nosupersub ur (i) with initial \nosupersub cap. only, (ii) in s
\nosupersub mall caps.)\par
\f0 \nosupersub \sb10 \tx1260 \tab
\nosupersub A. \f1 \nosupersub = Academician; Acade\nosupersub my; Associate.\par
\f0 \nosupersub \tab \nosupersub A \f1 \nosupersub = (\f222 \i \nosupersub Hist.
\f1 \i0 \nosupersub ) adult (as a film c\nosupersub lassification); adva
\nosupersub nced (in \f0 \b0 \i \nosupersub A level\f1 \b \i0 \nosupersub
\nosupersub , \f0 \b0 \i \nosupersub A/S level\f1 \b \i0 \nosupersub
\nosupersub , of the General Cer\nosupersub tificate of Educatio
\nosupersub n examination); all \nosupersub (in \f0 \b0 \i \nosupersub A-OK
\f1 \b \i0 \nosupersub \nosupersub , \f0 \b0 \i \nosupersub A-okay
\f1 \b \i0 \nosupersub \nosupersub \nosupersub (colloq.) in perfect
\nosupersub order or condition)\nosupersub ; ampere; atom(ic) (
\nosupersub in \f0 \b0 \i \nosupersub A-bomb\f1 \b \i0 \nosupersub
\nosupersub \nosupersub etc.).\par
\f0 \nosupersub \tab \nosupersub a.
\f1 \nosupersub = accepted (on bills\nosupersub of exchange); activ
\nosupersub e (of verbs); adject\nosupersub ive; \b0 \nosupersub [L]
\b \nosupersub \i \nosupersub ante\i0 \nosupersub \nosupersub before (with dates;
\nosupersub also \i \nosupersub a\i0 \nosupersub \nosupersub ).\par
\f0 \nosupersub \tab \nosupersub a\nosupersub \f1 \nosupersub = (as
\f222 \b0 \i \nosupersub pref.\f1 \b \i0 \nosupersub ) atto-.\par
\f0 \nosupersub \tab \nosupersub ?\f1 \nosupersub (\f222 \i \nosupersub Physics
\f1 \i0 \nosupersub ) = angstrom.\par
\f0 \nosupersub \tab \nosupersub AA
\f1 \nosupersub = Alcoholics Anonymo\nosupersub us; anti-aircraft; A
\nosupersub utomobile Associatio\nosupersub n.\par
\f0 \nosupersub \tab
\nosupersub AAA \f1 \nosupersub = Amateur Athletic A\nosupersub ssociation; American
\nosupersub or Australian Autom\nosupersub obil\nosupersub e Association; (
\f222 \i \nosupersub US\f1 \i0 \nosupersub ) anti-aircraft arti
\nosupersub llery.\par
\f0 \nosupersub \tab \nosupersub A. & M.
\f1 \nosupersub = (Hymns) Ancient an\nosupersub d Modern.\par
\f0 \nosupersub \tab \nosupersub A. & R. \f1 \nosupersub = artists and record
\nosupersub ing (or repertoire).\par
\f0 \nosupersub \tab \nosupersub AAU
\f1 \nosupersub (\f222 \i \nosupersub US\f1 \i0 \nosupersub ) = Amateur Athletic
\nosupersub Union.\par
\f0 \nosupersub \tab \nosupersub AB
\f1 \nosupersub = able (seaman); \b0 \nosupersub [L] \b \nosupersub
\i \nosupersub Artium Baccalaureus\i0 \nosupersub \nosupersub Bachelor of Arts (
\f222 \i \nosupersub US\f1 \i0 \nosupersub , cf. \f0 \b0 \i \nosupersub BA
\f1 \b \i0 \nosupersub \nosupersub ).\par
\f0 \nosupersub \tab
\nosupersub ABC \f1 \nosupersub = American Broadcast\nosupersub ing Corporation; Aus
\nosupersub tralian Broadcasting\nosupersub Corporation (former
\nosupersub ly Commission).\par
\f0 \nosupersub \tab \nosupersub ABH
\f1 \nosupersub = actual bodily harm\nosupersub .\par
\f0 \nosupersub \tab
\nosupersub ABM \f1 \nosupersub = anti-ballistic mis\nosupersub sile.\par
\f0 \nosupersub \tab \nosupersub ABS \f1 \nosupersub = anti-lock braking
\nosupersub sys\nosupersub tem (for motor vehic\nosupersub les).\par
\f0 \nosupersub \tab \nosupersub abt. \f1 \nosupersub = about.\par
\f0 \nosupersub \tab \nosupersub ABTA \f1 \b0 \nosupersub /\f2 \nosupersub "abt@
\f1 \nosupersub / \b \nosupersub = Association of Bri\nosupersub tish Travel Agents.\par
\f0 \nosupersub \tab \nosupersub AC \f1 \nosupersub = air-conditioned (e
\nosupersub sp. in India); aircr\nosupersub aftman; alternating
\nosupersub current.\par
\f0 \nosupersub \tab \nosupersub A/C
\f1 \nosupersub = account current.\par
\f0 \nosupersub \scaps \tab
\nosupersub ac \f1 \nosupersub \scaps0 \fs28 = \b0 \nosupersub [L]
\b \nosupersub \i \nosupersub ante Christum\i0 \nosupersub \nosupersub before Chri
\nosupersub st.\par
\f0 \nosupersub \tab \nosupersub a.c. \f1 \nosupersub = alternating curren
\nosupersub t.\par
\f0 \nosupersub \tab \nosupersub Ac \f1 \nosupersub (
\f222 \i \nosupersub Chem.\f1 \i0 \nosupersub ) = actinium.\par
\f0 \nosupersub \tab \nosupersub ACAS \f1 \b0 \nosupersub /\f2 \nosupersub "eIkas
\f1 \nosupersub / \b \nosupersub = Advisory, Concilia\nosupersub tion, and Arbitratio
\nosupersub n Service.\par
\f0 \nosupersub \tab \nosupersub AC/DC
\f1 \nosupersub = alternating curren\nosupersub t/direct current,
\f222 \i \nosupersub fig.\nosupersub \f1 \i0 \nosupersub (\f222 \i \nosupersub slang
\f1 \i0 \nosupersub ) bisexual.\par
\f0 \nosupersub \tab \nosupersub ACT
\f1 \nosupersub = Australi\nosupersub an Capital Territory\nosupersub .\par
\f0 \nosupersub \tab \nosupersub ACTH \f1 \nosupersub = adrenocorticotroph
\nosupersub ic hormone.\par
\f0 \nosupersub \tab \nosupersub ACV
\f1 \nosupersub = air-cushion vehicl\nosupersub e.\par
\f0 \nosupersub \tab
\nosupersub ACW \f1 \nosupersub = Aircraftwoman.\par
\f0 \nosupersub \scaps \tab
\nosupersub ad \f1 \nosupersub \scaps0 \fs28 = \b0 \nosupersub [L]
\b \nosupersub \i \nosupersub anno domini\i0 \nosupersub \nosupersub in the year of our
\nosupersub Lord, of the Christi\nosupersub an era.\par
\f0 \nosupersub \tab
\nosupersub ADC \f1 \nosupersub = aide-de-camp; anal\nosupersub ogue-digital convert
\nosupersub er.\par
\f0 \nosupersub \tab \nosupersub ADH \f1 \nosupersub = antidiuretic hormo
\nosupersub ne.\par
\f0 \nosupersub \tab \nosupersub ADP \f1 \nosupersub = (
\f222 \i \nosupersub Biochem.\f1 \i0 \nosupersub ) adenosine diphosph
\nosupersub ate; automatic data \nosupersub processing.\par
\f0 \nosupersub \tab \nosupersub AEEU \f1 \nosupersub = Amalgamated Engine
\nosupersub ering and Electrical\nosupersub Union.\par
\f0 \nosupersub \tab
\nosupersub AEF \f1 \nosupersub = American Expeditio\nosupersub nary Forces (esp. in
\nosupersub Europe during the w\nosupersub ar of 1914?\nosupersub 8).\par
\f0 \nosupersub \tab \nosupersub AEU \f1 \nosupersub (\f222 \i \nosupersub Hist.
\f1 \i0 \nosupersub ) = Amalgamated Engi\nosupersub neering Union.\par
\f0 \nosupersub \tab \nosupersub AF \f1 \nosupersub = audio frequency.\par
\f0 \nosupersub \tab \nosupersub AFC \f1 \nosupersub = Air Force Cross; A
\nosupersub ssociation Football \nosupersub Club.\par
\f0 \nosupersub \tab
\nosupersub AFM \f1 \nosupersub = Air Force Medal.\par
\f0 \nosupersub \tab
\nosupersub AG \f1 \nosupersub = Adjutant-General; \nosupersub Attorney-General.\par
\f0 \nosupersub \tab \nosupersub Ag \f1 \nosupersub (\f222 \i \nosupersub Chem.
\f1 \i0 \nosupersub ) = \b0 \nosupersub [L]\nosupersub \b \nosupersub
\i \nosupersub argentum\i0 \nosupersub \nosupersub silver.\par
\f0 \nosupersub \tab \nosupersub AGM \f1 \nosupersub = annual general mee
\nosupersub ting.\par
\f0 \nosupersub \tab \nosupersub AGR \f1 \nosupersub = advanced gas-coole
\nosupersub d (nuclear) reactor.\par
\f0 \nosupersub \tab \nosupersub AH
\f1 \nosupersub = \b0 \nosupersub [L] \b \nosupersub \i \nosupersub anno Hegirae
\i0 \nosupersub \nosupersub in the year of the \nosupersub Hegira (the Muslim e
\nosupersub ra).\par
\f0 \nosupersub \tab \nosupersub AI \f1 \nosupersub = artificial insemin
\nosupersub ation; artificial in\nosupersub telligence.\par
\f0 \nosupersub \tab \nosupersub AID \f1 \nosupersub = a\nosupersub rtificial inseminati
\nosupersub on by donor.\par
\f0 \nosupersub \tab \nosupersub AIH
\f1 \nosupersub = artificial insemin\nosupersub ation by husband.\par
\f0 \nosupersub \tab \nosupersub AIR \f1 \nosupersub = All-India Radio.\par
\f0 \nosupersub \tab \nosupersub AK \f1 \nosupersub = Alaska.\par
\f0 \nosupersub \tab \nosupersub a.k.a. \f1 \nosupersub = also known as.\par
\f0 \nosupersub \tab \nosupersub AL \f1 \nosupersub = Alabama; Anglo-Lat
\nosupersub in; autograph letter\nosupersub .\par
\f0 \nosupersub \tab
\nosupersub Al \f1 \nosupersub (\f222 \i \nosupersub Chem.\f1 \i0 \nosupersub ) = aluminium.\par
\f0 \nosupersub \tab \nosupersub Ala. \f1 \nosupersub =\nosupersub Alabama.\par
\f0 \nosupersub \tab \nosupersub Alas. \f1 \nosupersub = Alaska.\par
\f0 \nosupersub \tab \nosupersub ALP \f1 \nosupersub = Australian Labour
\nosupersub Party.\par
\f0 \nosupersub \tab \nosupersub ALS
\f1 \nosupersub = autograph letter s\nosupersub igned.\par
\f0 \nosupersub \tab
\nosupersub Alta. \f1 \nosupersub = Alberta.\par
\f0 \nosupersub \tab
\nosupersub ALU \f1 \nosupersub (\f222 \i \nosupersub Computing
\f1 \i0 \nosupersub ) = arithmetic and l\nosupersub ogic unit.\par
\f0 \nosupersub \tab \nosupersub AM \f1 \nosupersub = amplitude modulati
\nosupersub on; \b0 \nosupersub [L] \b \nosupersub \i \nosupersub Artium Magister
\i0 \nosupersub \nosupersub Master of Arts (\f222 \i \nosupersub US
\f1 \i0 \nosupersub , cf. \f0 \b0 \i \nosupersub MA\f1 \b \i0 \nosupersub
\nosupersub ).\par
\f0 \nosupersub \scaps \tab \nosupersub am
\f1 \nosupersub \scaps0 \fs28 = \b0 \nosupersub [L] \b \nosupersub
\i \nosupersub anno mundi\i0 \nosupersub \nosupersub in the year of the
\nosupersub world.\par
\f0 \nosupersub \tab \nosupersub Am \f1 \nosupersub (
\f222 \i \nosupersub Chem.\f1 \i0 \nosupersub ) = americium.\par
\f0 \nosupersub \tab \nosupersub a.m. \f1 \nosupersub = \i \nosupersub ante meridiem
\i0 \nosupersub \nosupersub .\par
\f0 \nosupersub \tab \nosupersub AMA
\f1 \nosupersub = American Medical A\nosupersub ssociation.\par
\f0 \nosupersub \tab \nosupersub AMDG \f1 \nosupersub = \b0 \nosupersub [L]
\b \nosupersub \i \nosupersub ad maiorem Dei glori\nosupersub am
\i0 \nosupersub \nosupersub to the greater glor\nosupersub y o
\nosupersub f God.\par
\f0 \nosupersub \tab \nosupersub AMGOT
\f1 \nosupersub = Allied Military Go\nosupersub vernment of Occupied
\nosupersub Territory, an organ\nosupersub ization first set up
\nosupersub in Sicily during th\nosupersub e war of 1939?5.\par
\f0 \nosupersub \tab \nosupersub AMP \f1 \nosupersub = adenosine monophos
\nosupersub phate.\par
\f0 \nosupersub \tab \nosupersub a.m.u.
\f1 \nosupersub = atomic mass unit.\par
\f0 \nosupersub \tab
\nosupersub AN \f1 \nosupersub = Anglo-Norman.\par
\f0 \nosupersub \tab
\nosupersub ANC \f1 \nosupersub = African National\nosupersub Congress.\par
\f0 \nosupersub \tab \nosupersub ANZUS \f1 \nosupersub = Australia, New Zea
\nosupersub land, and United Sta\nosupersub tes (treaty).\par
\f0 \nosupersub \tab \nosupersub AOB \f1 \nosupersub = any other business
\nosupersub (at the end of agen\nosupersub da for a meeting).\par
\f0 \nosupersub \tab \nosupersub AOC \f1 \nosupersub = \b0 \nosupersub [Fr.]
\b \nosupersub \i \nosupersub appellation d抩rigin\nosupersub e contr鬺閑
\i0 \nosupersub \nosupersub .\par
\f0 \nosupersub \tab \nosupersub APB
\f1 \nosupersub (\f222 \i \nosupersub US\f1 \i0 \nosupersub ) = all-points bulle
\nosupersub tin.\par
\f0 \nosupersub \tab \nosupersub AP\nosupersub I
\f1 \nosupersub = American Petroleum\nosupersub Institute (used
\f222 \i \nosupersub spec.\nosupersub \f1 \i0 \nosupersub w. ref. to a scale f
\nosupersub or expressing the re\nosupersub lative density of oi
\nosupersub l, with higher value\nosupersub s corresponding to l
\nosupersub ower \nosupersub densities).\par
\f0 \nosupersub \tab
\nosupersub APL \f1 \nosupersub = Associative Progra\nosupersub mming Language (a sp
\nosupersub ecific programming l\nosupersub anguag\nosupersub e).\par
\f0 \nosupersub \tab \nosupersub Apoc. \f1 \nosupersub = Apocalypse (New Te
\nosupersub stament); Apocrypha.\par
\f0 \nosupersub \tab \nosupersub Apocr.
\f1 \nosupersub = Apocrypha.\par
\f0 \nosupersub \tab \nosupersub APR
\f1 \nosupersub = annual percentage \nosupersub rate (of interest on
\nosupersub money lent).\par
\f0 \nosupersub \tab \nosupersub Apr.
\f1 \nosupersub = April.\par
\f0 \nosupersub \tab \nosupersub APT
\f1 \nosupersub = Advanced Passenger\nosupersub Train.\par
\f0 \nosupersub \tab \nosupersub AR \f1 \nosupersub = Arkansas; Autonomo
\nosupersub us Republic.\par
\f0 \nosupersub \tab \nosupersub Ar
\f1 \nosupersub (\f222 \i \nosupersub Chem.\f1 \i0 \nosupersub ) = argon.\par
\f0 \nosupersub \tab \nosupersub ARA \f1 \nosupersub = Associate of the R
\nosupersub oyal Academy.\par
\f0 \nosupersub \tab \nosupersub ARC
\f1 \nosupersub = Agricultural Resea\nosupersub rch Council; (
\f222 \i \nosupersub Med.\f1 \i0 \nosupersub ) Aids-related compl
\nosupersub ex.\par
\f0 \nosupersub \tab \nosupersub Ariz. \f1 \nosupersub = Arizona.\par
\f0 \nosupersub \tab \nosupersub Ark. \f1 \nosupersub = Arkansas.\par
\f0 \nosupersub \tab \nosupersub ARP \f1 \nosupersub = air-raid precautio
\nosupersub ns.\par
\f0 \nosupersub \tab \nosupersub AS \f1 \nosupersub = Anglo-Saxon.\par
\f0 \nosupersub \tab \nosupersub As \f1 \nosupersub (\f222 \i \nosupersub Chem.
\f1 \i0 \nosupersub ) = arsenic.\par
\f0 \nosupersub \tab \nosupersub A/S
\f1 \nosupersub = advanced supplemen\nosupersub tary (in \f0 \b0 \i \nosupersub A/S level
\f1 \b \i0 \nosupersub \nosupersub , of the General Cer\nosupersub tificate of Educatio
\nosupersub n examination).\par
\f0 \nosupersub \tab \nosupersub ASA
\f1 \nosupersub = Amateur Swimming A\nosupersub ssociation; American
\nosupersub Standards Associati\nosupersub on.\par
\f0 \nosupersub \tab
\nosupersub a.s.a.p. \f1 \nosupersub = as soon as possibl\nosupersub e.\par
\f0 \nosupersub \tab \nosupersub ASB \f1 \nosupersub = Alte\nosupersub rnative Service Book
\nosupersub (of the Church of E\nosupersub ngland).\par
\f0 \nosupersub \tab
\nosupersub ASC \f1 \nosupersub = Army Service Corps\nosupersub .\par
\f0 \nosupersub \tab \nosupersub ASCII \f1 \b0 \nosupersub /\f2 \nosupersub "aski
\f1 \nosupersub / \b \nosupersub = American Standard \nosupersub Code for Information
\nosupersub Interchange.\par
\f0 \nosupersub \tab \nosupersub ASEAN
\f1 \b0 \nosupersub /\f2 \nosupersub "asIan\f1 \nosupersub /
\b \nosupersub = Association of Sou\nosupersub th East Asian Nation
\nosupersub s.\par
\f0 \nosupersub \tab \nosupersub ASH \f1 \nosupersub = Action on Smoking
\nosupersub and\nosupersub Health.\par
\f0 \nosupersub \tab
\nosupersub ASL \f1 \nosupersub = American Sign Lang\nosupersub uage.\par
\f0 \nosupersub \tab \nosupersub ASLIB \f1 \nosupersub = Association of Spe
\nosupersub cial Libraries and I\nosupersub nformation Bureaux.\par
\f0 \nosupersub \tab \nosupersub ASM \f1 \nosupersub = air-to-surface mis
\nosupersub sile; assistant stag\nosupersub e-manager.\par
\f0 \nosupersub \tab
\nosupersub ASSR \f1 \nosupersub (\f222 \i \nosupersub Hist.\f1 \i0 \nosupersub ) = Autonomous Sovie
\nosupersub t Socialist Republic\nosupersub .\par
\f0 \nosupersub \tab
\nosupersub Asst. \f1 \nosupersub = Assistant.\par
\f0 \nosupersub \tab
\nosupersub AST \f1 \nosupersub = Atlantic Standard \nosupersub Time.\par
\f0 \nosupersub \tab \nosupersub At \f1 \nosupersub (\f222 \i \nosupersub Chem.
\f1 \i0 \nosupersub ) = astatine.\par
\f0 \nosupersub \tab \nosupersub ATC
\f1 \nosupersub = air traffic contro\nosupersub l; Air Training Corp
\nosupersub s.\par
\f0 \nosupersub \tab \nosupersub ATM \f1 \nosupersub = automated or autom
\nosupersub atic teller machine.\par
\f0 \nosupersub \tab \nosupersub atm
\f1 \nosupersub = atmosphere.\par
\f0 \nosupersub \tab \nosupersub ATP
\f1 \nosupersub (\f222 \i \nosupersub Biochem.\f1 \i0 \nosupersub ) = adenosin
\nosupersub e triphosphate.\par
\f0 \nosupersub \tab \nosupersub ATS
\f1 \b0 \nosupersub /\i \nosupersub colloq.\i0 \nosupersub \nosupersub
\f2 \nosupersub ats\f1 \nosupersub / \b \nosupersub = Auxiliary Territor
\nosupersub ial Service (for wom\nosupersub en in Britain, 1938?
\nosupersub 48); members of this\nosupersub .\par
\f0 \nosupersub \tab
\nosupersub attn. \f1 \nosupersub = attention, for the\nosupersub attention of.\par
\f0 \nosupersub \tab \nosupersub Atty. \f1 \nosupersub = Attorney.\par
\f0 \nosupersub \tab \nosupersub AU \f1 \nosupersub = angstrom unit; ast
\nosupersub ronomical unit.\par
\f0 \nosupersub \tab \nosupersub Au
\f1 \nosupersub (\f222 \i \nosupersub Chem.\f1 \i0 \nosupersub ) =
\b0 \nosupersub [L] \b \nosupersub \i \nosupersub aurum\i0 \nosupersub
\nosupersub gold.\par
\f0 \nosupersub \scaps \tab \nosupersub auc
\f1 \nosupersub \scaps0 \fs28 = \b0 \nosupersub [L] \b \nosupersub
\i \nosupersub ab urbe condita\i0 \nosupersub \nosupersub from the foundation
\nosupersub of the city (of Rom\nosupersub e, in 753 \nosupersub \scaps bc
\nosupersub \scaps0 \fs28 \nosupersub ); \b0 \nosupersub [L]
\b \nosupersub \i \nosupersub anno urbis conditae\i0 \nosupersub
\nosupersub in the year of the \nosupersub founding of the city
\nosupersub .\par
\f0 \nosupersub \tab \nosupersub Aug. \f1 \nosupersub = August.\par
\f0 \nosupersub \tab \nosupersub AUT \f1 \nosupersub = Association of Uni
\nosupersub versity T\nosupersub eachers.\par
\f0 \nosupersub \tab
\nosupersub AV \f1 \nosupersub = audiovisual; Autho\nosupersub rized Version (of th
\nosupersub e Bible).\par
\f0 \nosupersub \tab \nosupersub AVC
\f1 \nosupersub = additional volunta\nosupersub ry contributions (to
\nosupersub a pension scheme).\par
\f0 \nosupersub \tab \nosupersub Ave.
\f1 \nosupersub = Avenue.\par
\f0 \nosupersub \tab \nosupersub AWACS
\f1 \b0 \nosupersub /\f2 \nosupersub "eIwaks\f1 \nosupersub /
\b \nosupersub (\f222 \i \nosupersub Mil.\f1 \i0 \nosupersub ) = airborne warning
\nosupersub and control system,\nosupersub an airborne long
\nosupersub -range radar system \nosupersub for detecting other
\nosupersub aircraft and control\nosupersub ling weapons \nosupersub directe
\nosupersub d against them.\par
\f0 \nosupersub \tab \nosupersub AWOL
\f1 \b0 \nosupersub /\i \nosupersub colloq.\i0 \nosupersub \nosupersub
\f2 \nosupersub "eIwQl\f1 \nosupersub / \b \nosupersub = absent without (of
\nosupersub ficial) leave.\par
\f0 \nosupersub \tab \nosupersub AZ
\f1 \nosupersub = Arizona.\par
\f0 \nosupersub \tab \nosupersub AZT
\f1 \nosupersub (\f222 \i \nosupersub Pharm.\f1 \i0 \nosupersub ) = azidothymidine.
\par}
SOED4_exe_v1.0