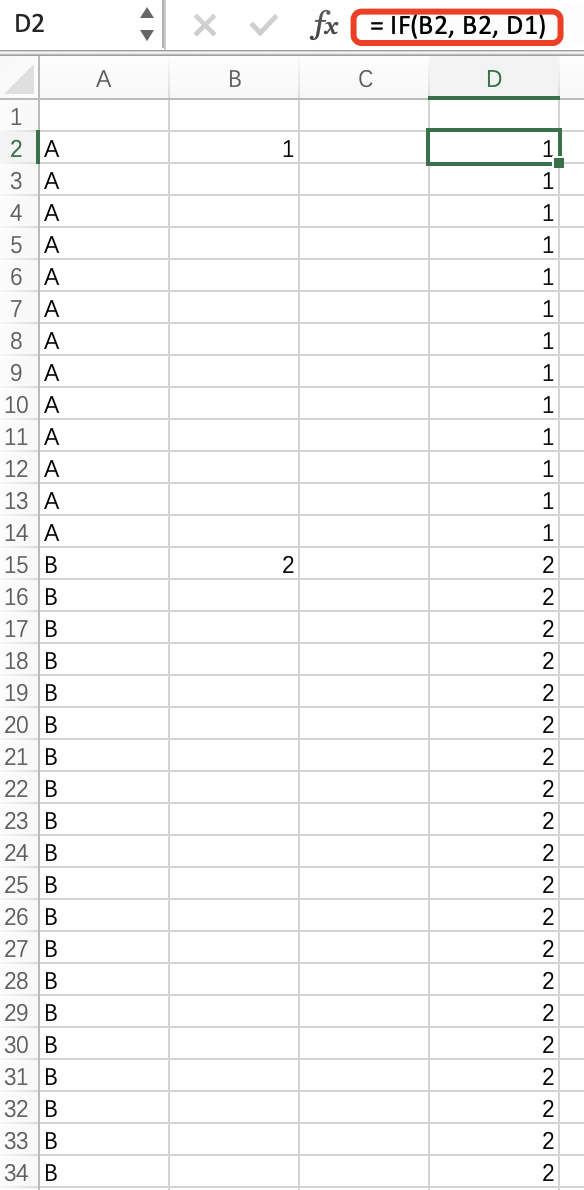
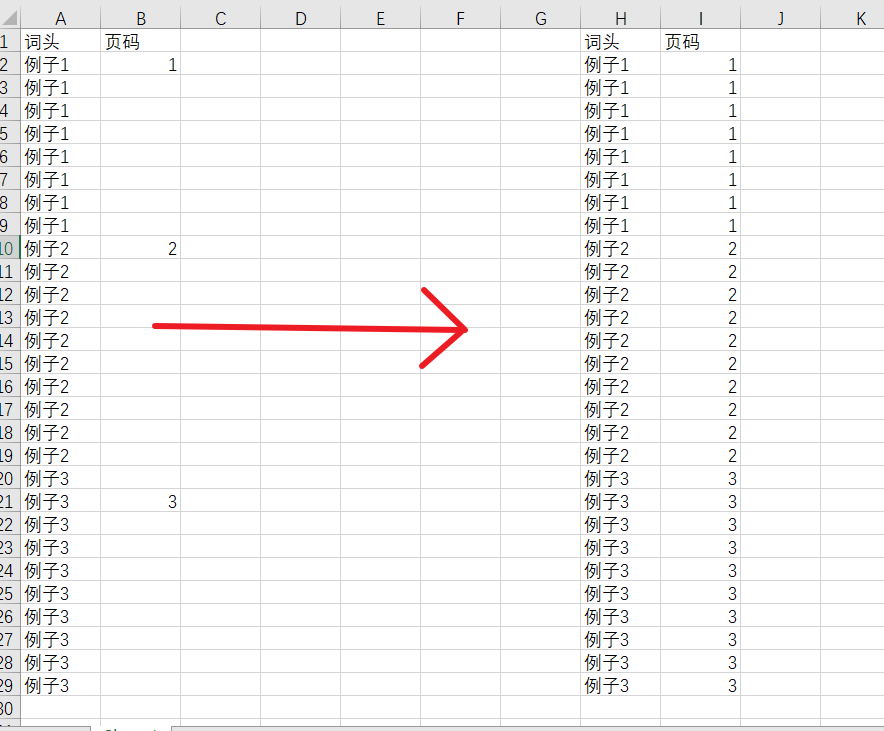
1.在excel里面,如何实现以下的功能?
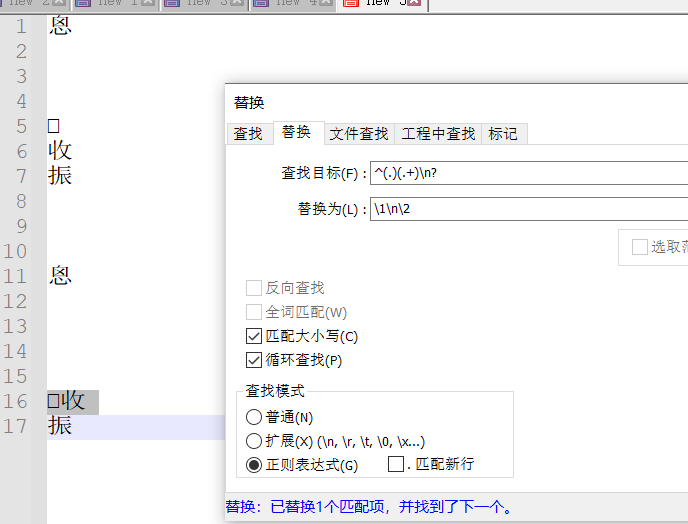
2.在文本里面,我用正则表达式“(.)(.)換成\1\n\2”或“^(.)(.+)\n?替换:\1\n\2\n”都无法把生僻字进行处理
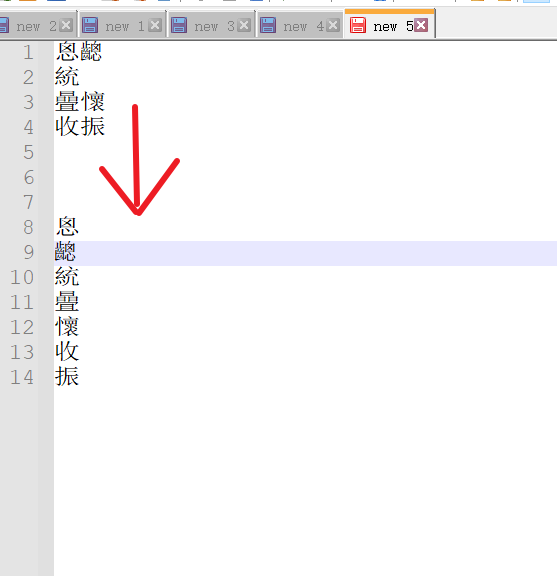
使用这个正则之后,变成了
1.在excel里面,如何实现以下的功能?
2.在文本里面,我用正则表达式“(.)(.)換成\1\n\2”或“^(.)(.+)\n?替换:\1\n\2\n”都无法把生僻字进行处理
使用这个正则之后,变成了
第一题我会(曾经)现在忘差不多了,凭记忆是用excel2016以后的,智能填充,smart 点一下
如果特别特别多,比如一个亿行,可以用pbi
是否要插入换行?可能与是否是生僻字无关。
用的是visual studio code。将(?=) 或一个竖线 | 替换为 \n ,再将\n+替换为\n (敝人技术不精,暂时没想出如何一步到位)
可参考:
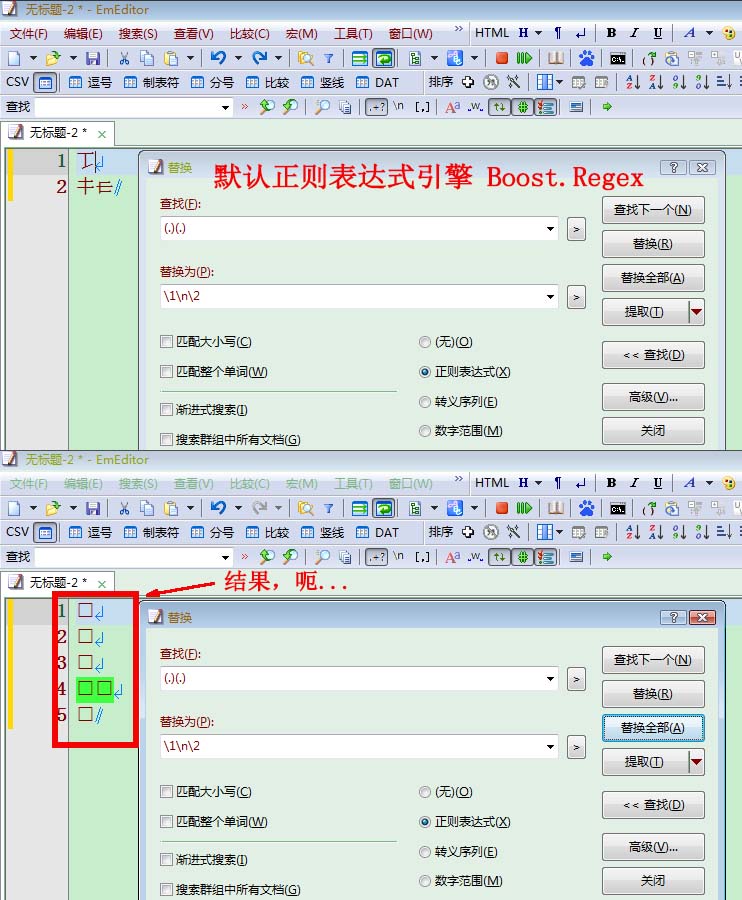
不要尝试在notepad++用“.”去匹配生僻字。大致情况就是:基本汉字能用“.”匹配得到,但是碰到扩展区汉字就是出现被拆分情况。
另外,建议文本编辑器换成emeditor,notepad++实在太弱了。
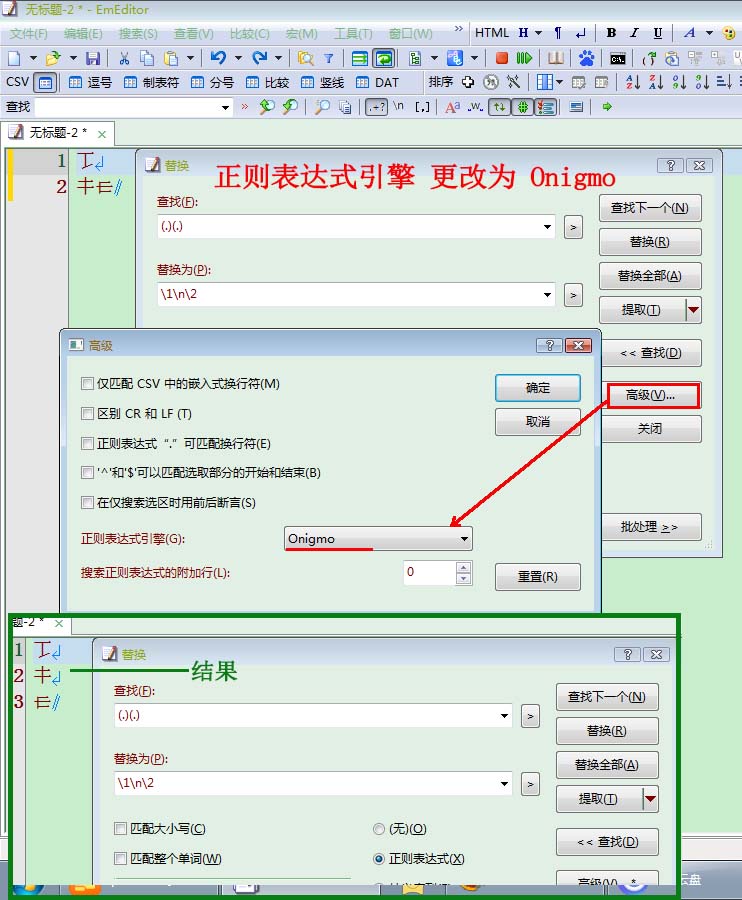
Emeditor汉字匹配
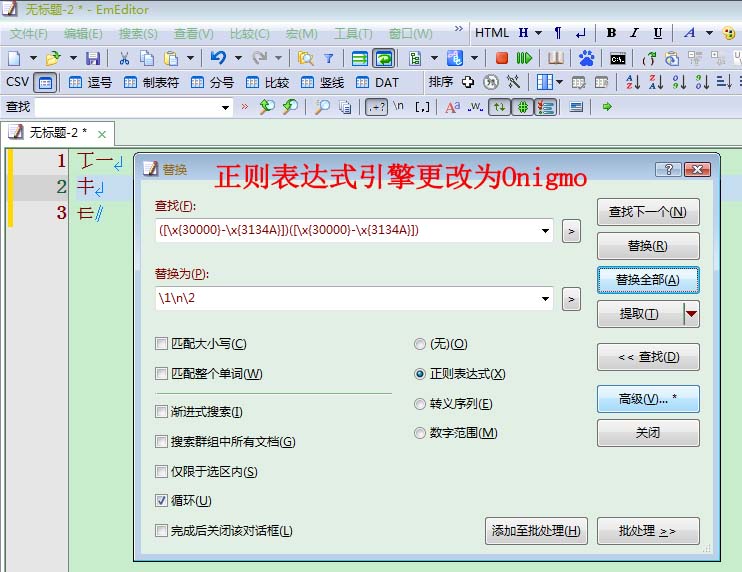
注意:重要一个,正则表达式引擎修改为:Onigmo。
基本汉字 [\x{3007}\x{4e00}-\x{9fff}]
扩展A区 [\x{3400}-\x{4DBF}]
扩展B区 [\x{20000}-\x{2A6DF}]
扩展C区 [\x{2A700}-\x{2B73F}]
扩展D区 [\x{2B740}-\x{2B81F}]
扩展E区 [\x{2B820}-\x{2CEA1}]
扩展F区 [\x{2CEB0}-\x{2EBE0}]
扩展G区 [\x{30000}-\x{3134A}]
兼容 [\x{F900}-\x{FAD9}]
兼容扩展 [\x{2F800}-\x{2FA1D}]
部首扩展 [\x{2E80}-\x{2EF3}]
注音 [\x{3105}-\x{312F}]
笔画 [\x{31C0}-\x{31E3}]
康熙部首 [\x{2F00}-\x{2FD5}]
注音扩展 [\x{31A0}-\x{31BA}]
私用SSP [\x{E000}-\x{F8FF}]
私用PUA-A [\x{F0000}-\x{FFFFF}]
私用PUA-B [\x{100000}-\x{10FFFF}]
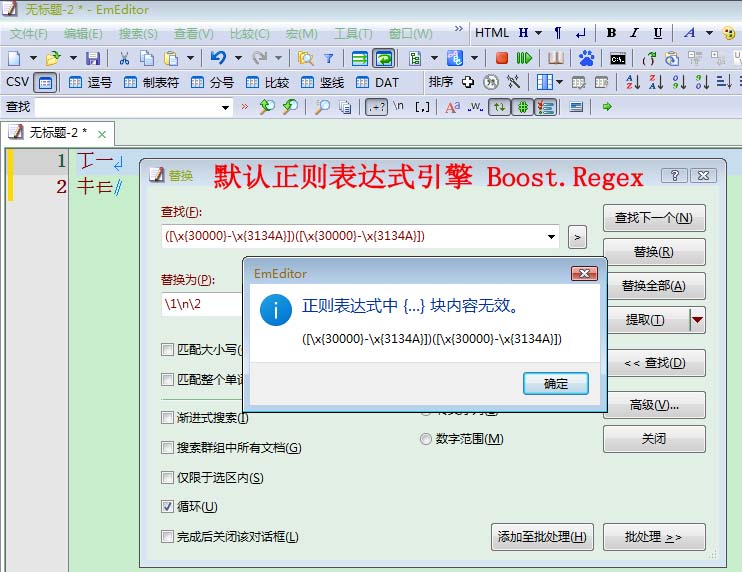
想要匹配全部汉字,把上面的集合凑在一起就行了。
excel很简单,选中-空值,第二行=第一行的数字,完事
Visual Studio Code
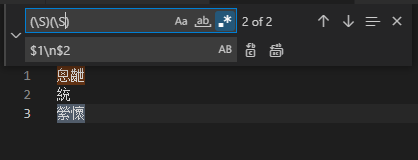
(.)(.)
應該也可以。
搭车请教个问题。
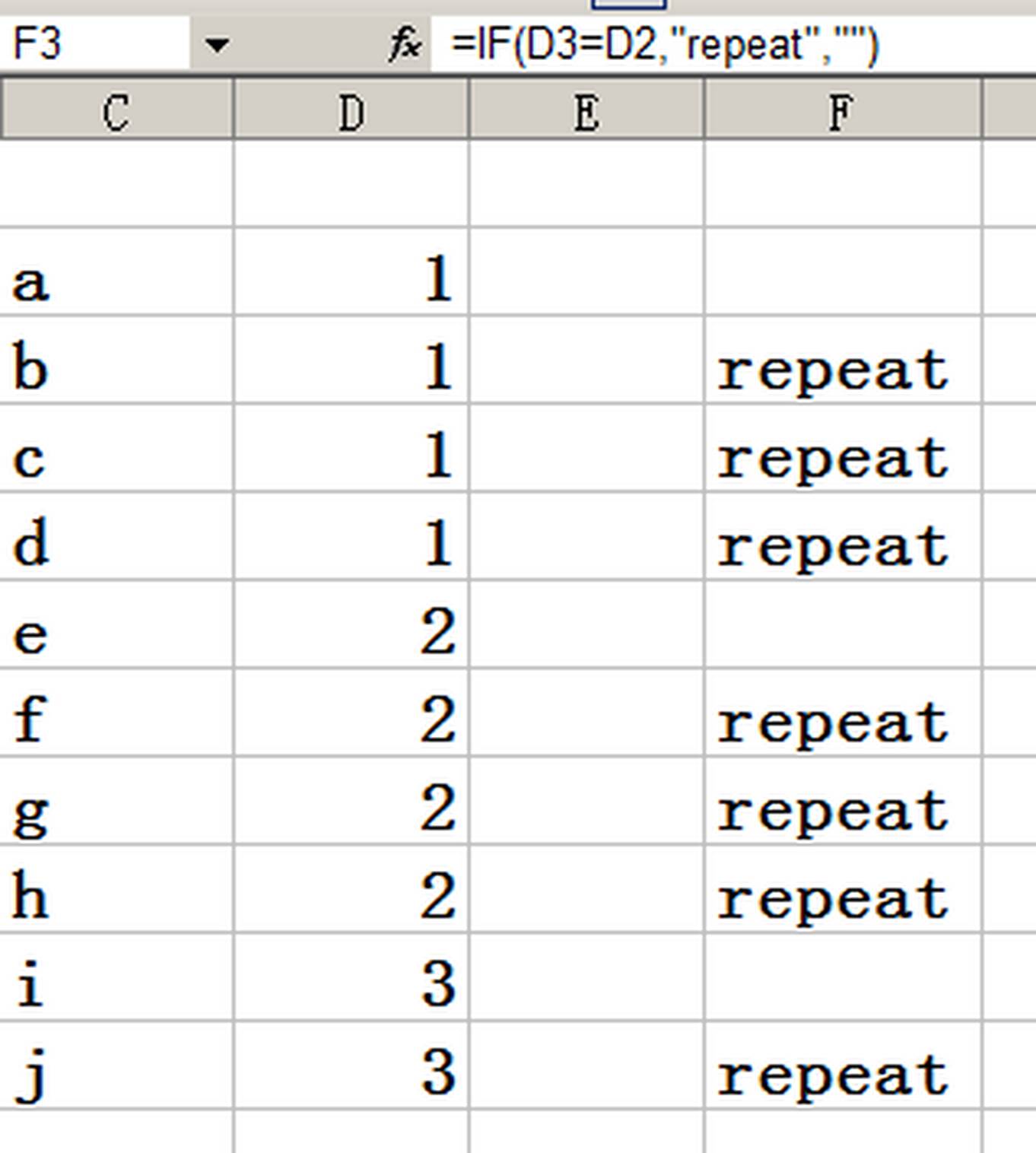
第一个Excel中,反过来怎样操作?也就是怎样把右侧这些重复的数字删去?先谢谢了。
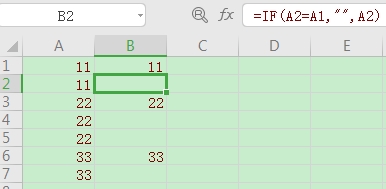
感谢感谢!原来是我最后的“A2”没写对,所以一直出错。
不错不错 ![]() 也是一个办法。
也是一个办法。
不只“也是一个办法”,有时候更关注哪个单元格重复了,这时还是老兄的公式管用。
谢谢大家,十分有用的建议,在此特为感激 ![]()
![]()