試試新版。我發現我原來把相關 woff 的 unicode-range 定得太窄了。MDict PC is more forgiving about things like this.
6 个赞
辛苦M大了。非常感谢!不过下载更新了顶楼最新版后发现还是不行,具体表现是:查询“直”字后,一开始可以显示括号内带竖折的“直”字,然后一两秒后显示画面闪动,随即变了一种显示字体,最后括号内的“直”字就变成了底部为“一横”
我認為 html/css/woff 依據標準。DictTango 行為出乎意外,只能向 glacierlee 請教。
我猜測應該是詞典mdd本身有自帶了字體,然後用戶本身在DictTango的全局顯示字體裏添加了WFG的大字體並且是按需加載模式,這種情況下可能會造成衝突。
如果是這種情況,我建議對於大於30mb的字體,不要加到全局顯示字體,而是加到有需要的詞典的專用顯示字體裏,對於已經有自帶字體的詞典就無需添加專用顯示字體。
1 个赞
没有添加 全局显示字体
1 个赞
那应该是另外一种情况,这是QQ群里的一位群友分析的。
------13:47:22
这是因为webkit浏览器会(我才是根据用户系统语言)自动替换字体的表现型。
------13:50:12
这个字是旧字体,主要是台湾地区使用,所以大陆地区用新字体替换了。
------13:51:14
ie核心的就更加忠实,当然你也可以说不如其他浏览器“智能”。
------13:52:09
而且,不光这样,有时候同一个字ie,firefox和chrome会有不同的表现。
------13:57:25
据观察,“智能换字”只限于兼容字。其他字貌似不受影响。
------14:27:32
所以这个问题不是软件问题,是浏览器行为。
------14:29:27
不信你看,在ie核心的mdict上就没问题了。
------14:32:09
“智能换字”的初衷应该是为了让字形适应不同地区用户的用字习惯,可惜没考虑到咱们这种情况,好心办了坏事。
1 个赞
webkit 的替換行為,大概是硬硬地根據 Unicode 組織對兼容字的說法。具體狀況是 Unicode 聲明 舊字體 “直”(U+2F940) 等同 新字體 “直”(U+76F4):
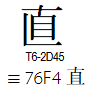
兩個字音義相同,若只在 email 裡讓 “直” 換成 “直”,那無所謂,但字典當作不同字,需要並陳而分辨,甚至有時會分別立目。
Unicode 認定 “等同” 的標準很氾濫,而且它不在乎的差別,經常就是字典關注而強調的區分!
總之,Unicode 認為兩字等同,webkit 不追究這說法的旨意,也不在乎具體的使用環境,就死板地實施了。而且,商業字型庫都支持平面二的兼容字,沒必要這樣替換。
2 个赞
网上看到的,供参考。
2 个赞
不區分平面0與平面2兼容字的狀況,就講得不全面,不管用。
漢語大字典 在特殊年代開始編撰,編輯的原則很大程度不符合字書規範:
1。正簡字體混合。大陸學生看不懂。使用正體的人又厭惡簡體。
2。解釋重復。把說文、玉篇、廣韻、集韻、康熙字典、中華大字典誤黨字義書證,導致重復冗餘。
3。鄙俗字,錯別字,不穩定的鄙俗用法收錄太多。本有正確用法而不用。相當於妓比正宮更重要。
4。相當的近代書證,毫無意義,並無增加字義,只增加冗餘,浪費讀者寶貴時間。
5。政治書證具有時代性不應引入。
6。外國宗教詞彙本不屬於漢語,不應引入。
7。科學術語不正確。編撰時沒有參考科學技術專業詞典。
8。政治術語也不準確。
總之,這本書雖然巨大,但基本上無文學價值。 不值得花費時間搞電子字典。
1 个赞
23個則天文字,應從字典中刪去。這是唐朝已經正式廢除的的文字,且本有正字。
1 个赞
[喬頁]是個錯別字,康熙字典其它地方用[䯪]。這個自符合六書,比[驕傲]字更適合,畢竟人驕傲比馬驕傲好,但是沒人用。康熙字典中有幾十個錯別字,所以Unicode沒有收入。
1 个赞
你真逗~~~~~~
2 个赞
不要理他 。
加了 𣎛|𦠈 字組
5 个赞
M大辛苦了,感谢精益求精!
1 个赞
目前服務器不能上傳新版,先簡單做個記錄。“𧠊”的第三釋義錯誤合併,當歸“㒻”字條。
這些字條,“同 X” 的 X 指字頭,必定是錯字:𥁺、𥪿、𤁩、𧆢、𥦹、聮。
𥦹、聮兩條,紙本本身有問題。
又簡單修了音韻。方案是把列出的《廣韻》【聲調】【韻目】抽出來,然後在 Emeditor 用 delete duplicates。留下來的,原則上當有206行【聲調】【韻目】組(因為廣韻206韻有固定聲調)。超過206行的,不是聲調錯,就是韻目錯。修了幾十條。
2 个赞
图文对照看,可以安心使用
M大是否考虑合并同属于一条引证的内容呢?我发现可以通过两个文本特征,用正则把同属于每条引证后的所有「注疏」文本查找出来。每条引证的注疏部分的文本特征是:一般不会出现书名标签<i>,特殊情况是书名标签出现在注疏的引号内 。根据这两个文本特征,就可以用正则把每条引证的注疏部分都找出来,然后通过更改标签把它们合并在一起。我对< p>标签的文本分别用正则<z>((?!<i>).)*<\z> 和 <z>((?!<\/z>).|\n|\r)*“((?!”).|\n|\r)*<i>((?!<\/z>).|\n|\r)*<\/z> 尝试提取了下,好像是可以实现的。不过我正则和emeditor操作都不太熟悉,但是这是一个思路,你看看这方法可行么?我觉得根据文本特征,用正则来提取合并引证应该是可行的,大多数情况是不需要人为语义分析处理的。
that’s an interesting observation that would probably work. it might take weeks of testing to see if it gets the desired results, after which time, I would have made other edits; if I have to revert to the prior version, I would need to repeat the other edits, which would also first need to be logged. that’s extra work to test it.
more to the point, I think it’s fine to visually separate things that logically go together, just like breaking a long paragraph into two short paragraphs: it makes it easier to read.
1 个赞