以前對繁體字無限類推簡化,比較典型的應該是包含“言、馬、鳥”等幾個偏旁部首的漢字。
2013年通規表發佈后,表外漢字不再類推簡化。平常用自然沒問題,有些情況下就麻煩了,比如古漢語類詞典。
古漢第二版在2014年出版,所以"謥"不能再簡化,“𫍣”是通規三級字,必須簡化。這樣才符合規範。
“䡶𫐐盖“是一樣的情況,這些字在第一版中都是類推簡化字。
所以通規表外的字,偏旁就不簡化,是這個道理嗎?(我以為新的類推限制是某些部件不能同時簡化。)anyway, 詞頭疑點可以用通規表來定。
大字典第二版也是通規表之前出版的,收了一大堆類推簡化字,反而沒收一群通規表裡的簡體。其實大字典標是類推簡化字,有一部分原來是歷來俗體,也就是說,會出現在古代文獻,可惜大字典沒有詳細歸類。字海也沒特別分辨。只不過文獻通過數據化過程也被規範化了,那些俗體就消失了,這不是壞事但會缺個歷史感。


簡化即使限制於通規表的字,在電腦上還是引起不少問題。有 200 通用字並不在Unicode原版字集,很多字型不完全支持。況且有 110 所謂通用字(字級三)是 2015 年才加入 Unicode (!),字型支持度,和軟件繁簡轉換功能就更不用說了。字型要支持擴展 E 區才行。
例如:諲、闉、騑、鶱、齼 等字,簡體對應都是“通用”字,MDict PC 繁簡轉換功能不處理,GH2圖像版沒有繁簡跳轉,我一定要打簡體字才查得出來。我輸入法切成簡體字是可以的,但查字不僅是使用者輸入的,通常是從其他字典或資料庫拷貝過來的。
我對這個工程沒什麼特別主意,只是隨便聊聊。
Dict Tango呢,沒有PC版,所以不管它多好我也不會常用。
没有 PC 版确实是个遗憾。
谢谢大师制作分享。
这说明如果有个类wiki网页的版本供讨论、勘误、记录,就省事很多。可惜各种条件限制很难实现
文字版數據,字頭標繁體,但詞頭不標。這是嚴重問題,例如:

應當這樣分辨:

不同繁體詞集中於一個簡體寫法:历数﹑系縻﹑台端﹑后帝﹑后门﹑向明﹑向服﹑沄沄﹑郁伊﹑郁郁。冬冬﹑冲冲﹑回翔﹑卷卷﹑涂巷﹑蒙昧﹑蒙蒙。
上面案子較明顯,我修了,但到處都是這個缺陷,無法人工修理。相關詞單,可以作,但解決不了上述毛病。
這的確是個大問題。簡化字之殤!原紙書也沒標出,是個巨大的遺憾。這部分一音多義詞APP全部沒有,全靠人工與紙書校對的。
2022.9.7
2022.5.2
古代汉语词典2 (2014).zip (7 MB)
- 加了另一種詞單叫“關聯詞”。例如“槎枿”不歸於“枿”的“相關詞”因為“枿”沒有字條,但“枿”是“蘖”的異體字,所以“槎枿”列於“蘖”的關聯詞。
“關聯詞”不用“~”符號,因為它並不是字頭本身。。
這類 出現在詞頭 但自己沒有字條的異體字,有36:
㚟、蠵、阸、迆、蹏、緥、臝、袵、虵、虯、枿、矇、葅、穅、稾、眥、肬、疎、觝、汙、獘、櫫、慤、怳、廩、么、㟼、崯、嵒、砦、㜸、阬、啕、恡、捲、懃 - 加了“關聯詞”,例如“槎枿”不歸於“枿”的“相關詞”因為“枿”沒有字條,但“枿”是“蘖”的異體字,所以“槎枿”列於“蘖”的“關聯詞”。關聯詞不用“~”符號,因為字不是主字頭本身。
- 文本應當完善了,增补了:襂﹑冲1[沖]﹑今﹑菀﹑𬊤﹑𬊤赫﹑台2[臺]﹑䡶𫐐盖﹑䱍䲛﹑培𪣻﹑𫘝𫘨﹑𫘦𬳿﹑𬳵騃﹑晧晧﹑晧旰。
- 4.12版有27私有區字,出現364次;改成標準字,又增補了“𡬶”的異體,現在私有區字有6個,出現10次。其字碼也換了,能跟《部件檢索》通用。私有區字原來用黑體,換成宋體,內嵌在MDD。
- 字條裡的音項換行;只有字項(字體不同)才用橫線分段。注意:字條合併的字體項,次序經常有誤,我順手修了幾十個,但電子版本來就沒整理。(簡繁字,理應字排在下,本字排在上。)
- 作了相關詞單,分成“詞頭”組(字頭在首位)和“相關詞”組(字頭在尾位或中間)。“詞頭”按照紙本順序排次(即拼音順序),列於核對的字項(不能詳細得歸於核對的音項)。電子版不特別分字項,所以必須人工分組和歸項。電子版改變的詞頭都歸新項,例如紙本“寮佐”,電子版改成“僚佐”,今歸“僚”字。
- “相關詞”的排法:短詞先於長詞,尾位先於中位,第二字位先於第三,然後按照紙本詞頭頁碼來排次。“相關詞”皆列在字條最下面,因為難以判斷該歸何項。
- 詞典的字頭標繁體,但詞頭不標,通常也不分字項(字1,字2)。例如“曆數”、“歷數”都合併於“历数”詞條,雖然是不同詞。我修了較明顯的案子,例如:历数﹑系縻﹑台端﹑后帝﹑后门﹑向明﹑向服﹑沄沄﹑郁伊﹑郁郁。冬冬﹑冲冲﹑回翔﹑卷卷﹑涂巷﹑蒙昧﹑蒙蒙。
- 為了方便追究字體、字義,詞頭每字都加了鏈接。
- 釋文中,去掉了2,000多鏈接,因為目的地就是本條。又去掉了500個鏈接,因為詞典沒收該字、該詞。
- 刪了重出內容:㹶、批、滋、示、纽、金、襂、皓旰、皓皓、恍惚、疮痍、葱茏、蟾蜍。

編輯記錄:
- 爻:“—”是阳爻→“⚊”是阳爻
- 忄拜→𫺨
- 璊→𫞩
- 蝀→𬟽
- 諲→𬤇
- 鐍→𫔎
- 顗→𫖮
- 膢→𦝼
- 貙→䝙
- 貙膢→䝙𦝼
- 纁→𫄸
- 玄纁→玄𫄸
- 玓瓅→玓𬍛
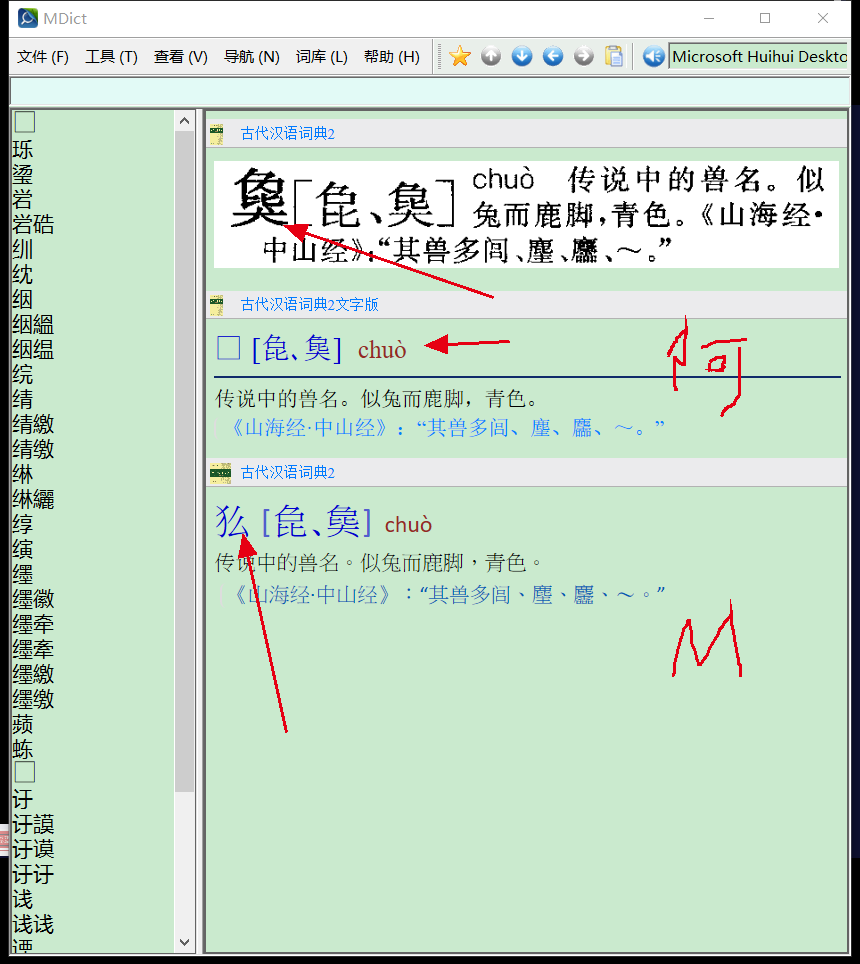
- 謥詷→謥𫍣
- 嗀→嗀
- PUA→⺋
- PUA→⺌
- PUA→⺗
- PUA→龵
- PUA→𤴔
- PUA→𥫗
- PUA→⺶
- PUA→⺷
- PUA→𧾷
- PUA→龺
- PUA→𫲕
- PUA→𬳩
- PUA→𤜂
- PUA→𥜽
- PUA→𬡵
- PUA→𮩴
- PUA→懶
- PUA→壳
- PUA→椔
- PUA→FSung-PUA
- PUA→FSung-PUA
- PUA→FSung-PUA
- PUA→FSung-PUA。
- PUA→T-source搢
- 冗[PUA、宂]→[T-source宂、G-source宂]
- 壳[壳]→G-source壳[T-source壳]
- 犦[犦]→𤜌
- 灊[灊]→[灊]
- 寻[𡬶、𡬶]→[𡬶、FSung-PUA]
“心”的相關詞:

M大辛苦了!
css中引用的字体从哪里下载?没那些字体的话有些异体字显示不出来
辛苦了,感謝完善,功德無量!
缺少的詞條重抓了一下,“今”原圖片版𣺘了,還有的,如 沖、台2[臺]、燀,【𬊤赫】APP也沒有。手動補上的。已與圖片校對,你可再看一下。
补词条4-19.txt (5.8 KB)
這個字,顯示有問題。。。私有字,不知有無類似的顯示問題,可再檢查一下
暂时用下面的文件覆盖进M大的文件夹,都不要改名,等待M大的更新
古代汉语词典2.1.mdd (228.3 KB)
GH2.css (2.0 KB)
字型方面,自己選用一個,例如中華、開心宋。
CSS指定是全宋體(就是部件檢索的字型),只不過因為它全,我不用想太多,方便編輯。能夠顯示所有的字就夠了,為了這個詞典不用太講究我覺得。
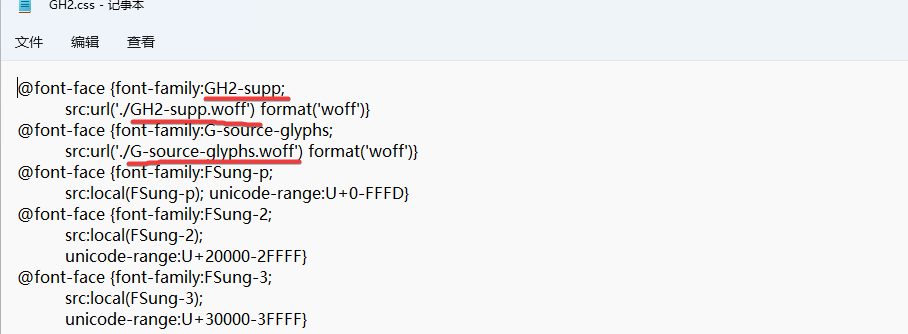
在mdd里面。
哦,看mdd那么小,还以为里面包含的不是字体文件
更新了mdx(5PM)。文本應當完善了。謝謝佛大。
字條合併了內容,字項次序經常有誤,原則上可以用正則查出來,但整理要很費工,不值得。就做到這裡,能用。——我本來只要加個 相關詞單,後來發現要先作這個那個才能好好處理,比我想象的複雜哈哈。