由于看不懂日语,用翻译软件翻译句子又机翻味太重,有些翻译看完完全不知道是在说什么,于是想单独查句子中的单词释义来理解句子的意思,但一看下去全是假名,哪些才是单词呢?就是因为看不懂才要查单词,但看不懂连单词都分不清楚,这就死循环了。
于是在网上到处搜索,找到了Mecab这个分词工具,作者GitHub上提供了EXE安装包,寻思着这下好了,结果安装完打开mecab.exe一用,全是乱码,而百度搜到的许多使用教程都只简单提了一句安装版,根本没有使用方式,剩下全是直接用源码编译,这不是为难我这零基础小白吗?
于是只能再到处找,终于找到了这篇日语博客写了python调用mecab.exe的方法:
Mecab(形態素解析)で遊んでみた! - Qiita
用python总比源码编译简单吧,于是依葫芦画瓢,再东拼西凑,终于搞出来了,效果如下:
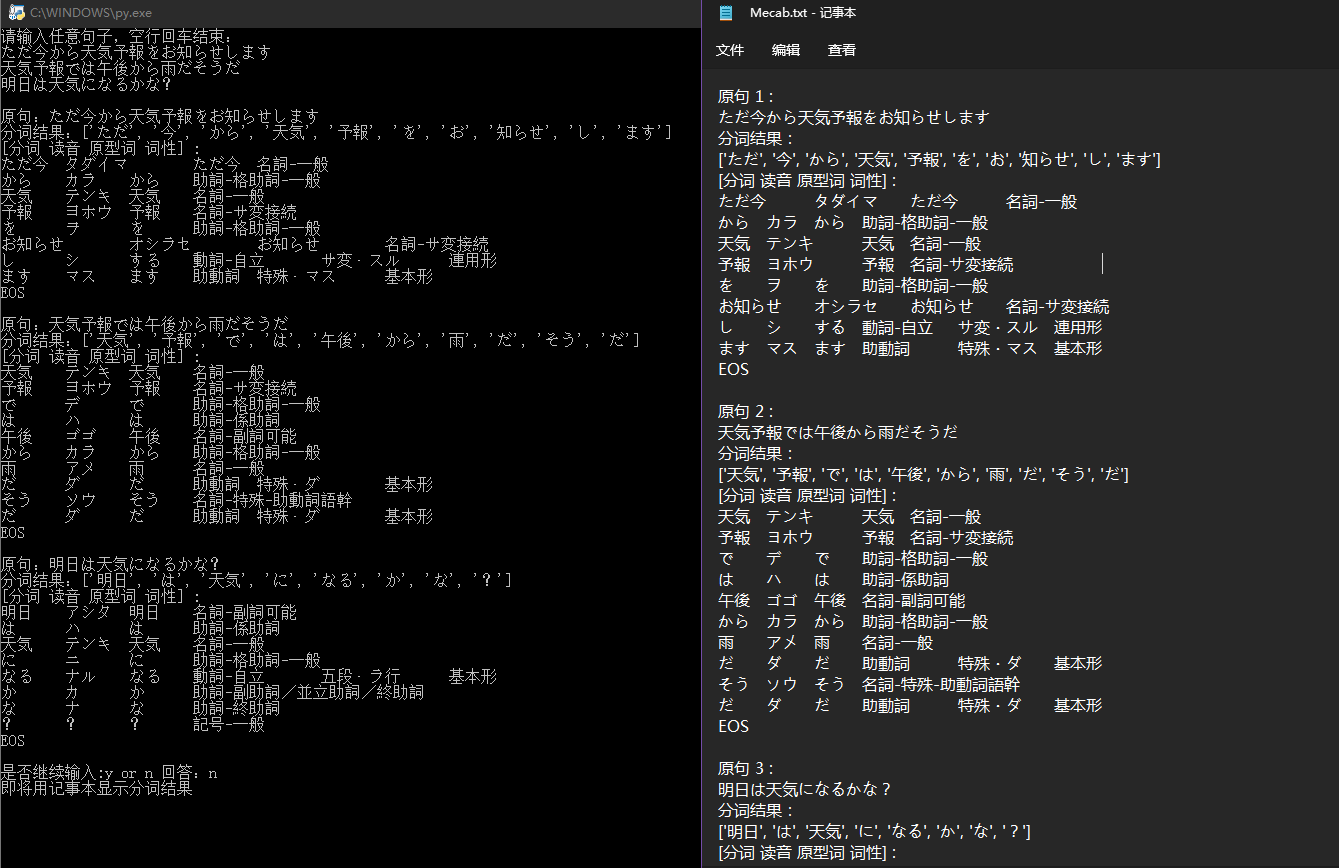
虽然有些词分的也不是太好 ,如“天気予報”就被分成两半了,但有总比没有好。下面的链接是相关工具和我写的.py文件:
https://www.123pan.com/s/kxP9-ilUAH
由于是零基础小白,写的不好勿怪
20220327晚补充:
翻看资料时突然发现我犯了一个大错误,.py程序里并没有真正调用Unidic语料库,用的依旧是老旧的ipadic,虽然也能用,但想要用最新的Unidic语料库还需要改一改。我暂时不知道如何在程序里调用,就先说一说手动修改的方法,免得误导大家。
方法就是把Mecab的etc文件夹下的mecabrc用记事本打开,将dicdir = (rcpath)\..\dic\ipadic改为本地Unidic语料库的实际文件夹,比如我的就是dicdir = (rcpath)..\dic\unidic-cwj-3.1.0。可以在控制台输入mecab.exe -D查看是否调用成功。
调用成功后,我在.py文件里用的-Owakati和-Ochasen输出格式就不起作用了,因为那是ipadic语料库的用法,Unidic的输出格式可以看看语料库目录下的dicrc,里面提供了unidic22、verbose、chamame三种输出格式,用法就是加个-O,比如-Ounidic22代替掉-Owakati,还可以自定义输出格式,代码含义如下表:
Unidic dicrc文件代码含义.xlsx (10.1 KB)
更多可参考Unidic官方资料 :
「UniDic」国語研短単位自動解析用辞書|FAQ (ninjal.ac.jp)
根据这份表格和原本就有的几种输出格式的语法,就可以自定义出多种自己想要的格式,语法格式相当简单。
20220328晚:
.py程序修改好了:
Mecab - Unidic词典.py (6.5 KB)
用记事本打开,将路径修改为正确的语料库路径即可。
因为unidic自带的格式过于杂乱,用的依旧是ipadic的-Owakati和-Ochasen输出格式,需要用记事本打开ipadic的dicrc文件,将格式代码复制到unidic的dicrc文件里,即可实现兼容。
