今日从兹役
2022 年2 月 15 日 14:56
1
之前 superzhangmch 改编过一个说文解字的检索文档,我已经忘了从哪里下载到的了,现在源文档也早已被我删掉。不过我对这种格式的词典非常满意,现在尝试着做了一个。但我没学过编程,也完全不懂设计网页,只能利用他的框架填上自己的内容,所幸试了一下,用起来还基本能满足需要。
HTML格式的优点:
1,只要纯文本的话,体积很小,方便存储传递。
2,不需要任何特别的辅助软件,只要有显示生僻字的字体、浏览器就可以完全利用。
3,相对于一般mdx词典,这个不仅仅可以查字头,词条内容也可以查。
4,内容便于修订,就用word或别的软件打开,查找替换即可。
5,支持不少正则表达式检索,如果文本内容有固定的程式,那就可以进行复杂的匹配检索。
框架的问题:
1,这个框架原来是为了说文解字做的,针对重文做了一些复杂化的设计,其实可以都删掉,但我不懂不敢删除,导致在调整内容时总是面对里面的冗余代码。需要删掉。
2,除了检索项三个格子以外,其他可检索项目原作者进行了不必要的限定,导致在不符合要求的情况下检索不到内容。需要撤掉这些限定。
3,原来每个格子的顺序编号比较乱,需要调整顺序。
4,原来的框架不支持格子里面换行,对于显示康熙字典之类内容过于丰富的辞书这就很不方便了。
5,希望能固定列宽。现在的这个框架貌似只设置了检索项的列宽,其他总是随着文本内容变动,在使用时界面忽宽忽窄,影响使用体验。
6,定义字体字号、颜色的地方希望能集中一些。
7,页面很多的情况下,点上一页下一页太过耗手了,希望设计一个可以跳转的页码。
关于格式讨论和技术求援,暂时就这些。
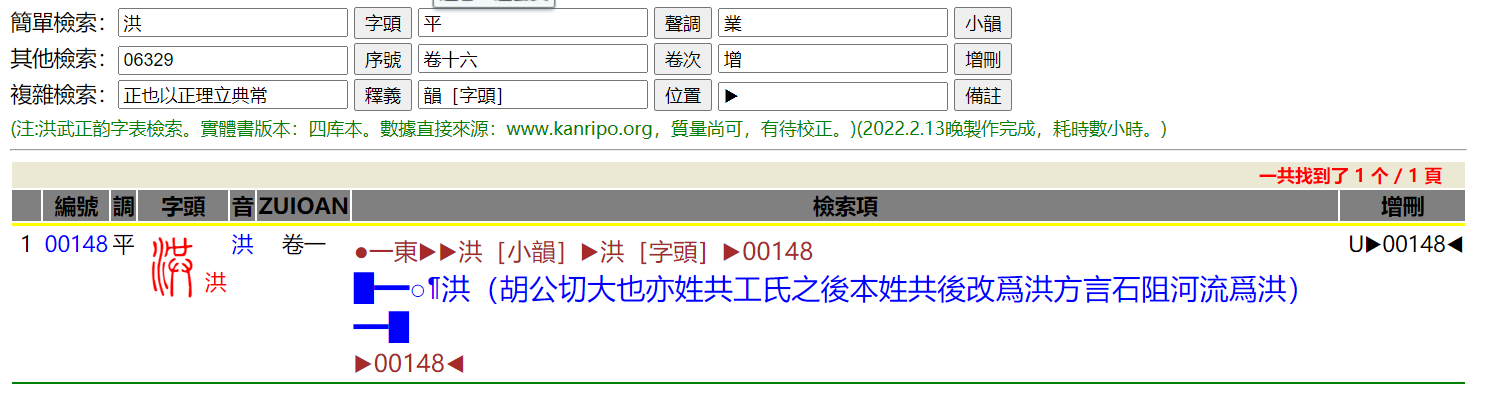
我制作的洪武正韵分别使用了本坛 okayer 抓取的数据,以及日本人修订的迪志的四库数据(kanripo)。由于本人还在学习,加上数据本身存在一些问题,做这个用了不少时间,做的结果也存在各类问题。不过大家可以下载试验一下,这种格式确实值得推广和改进,尤其是在有全文文本、又不需要集成扫描图像时。
洪武正韵.7z (1.0 MB)
我对《洪武正韵》没什么兴趣,但是觉得兄台做的这个格式的词典很有趣,赞一个!
兄台刚来,就做起词典来,而且乐于分享,再赞一个!
今日从兹役
2022 年2 月 15 日 15:11
3
谢谢,确实是什么书其实在其次啊。你就假定是你需要的一本书,看用起来方便不方便。好用的话大家一起完善这个框架,或者针对不同的书再优化一下,更多内容就可以搞起来。
今日从兹役:
日本人修订的迪志的四库数据(kanripo)
kanripo数据库的维护者不是日本人,而是德国人、汉学家Christian Wittern(維習安),他现在是日本京都大学的教授。网站上数年前有制作者和数据来源等的介绍,后来删除了,或许因为严格来说这些数据可能存在侵权问题(古人的书现在当然是公版,但将其文本化、扫描的公司也许拥有某些权利)。
Christian Wittern网上有论文“ Digital Texts in Practice” ( Digital Texts in Practice )自述怎么制作这些电子数据库的,可参考。
这个问题含糊不清。怎样把文字html制作成图片版m-dict?
你是说制作文字与图片对照的m-dict吧?
技术上可行,但太费功夫,没人愿意做。
Kanripo网站就是图文对照的。需要看图的,去检索原网站。
对Kanripo某书需要图文对照m-dict的书友,自己先花功夫把该书文字和图片都下载齐全,分享到这里,再求人做m-dict。
KR1j0068 洪武正韻-明-樂韶鳳https://www.kanripo.org/text/KR1j0068/
图文对照例子(需要点按文中的图片号码)https://www.kanripo.org/text/KR1j0068/001#1a
粗略看了一下,这种格式的文档从程序角度来评价是比较糟糕的。数据层、渲染层和控制层没有分离,基本全糅合在一个文件里,原始数据就是一大团超长string,加了很多用于区分的符号、标签以有利于js控制,而js控制的方法就是靠正则搜索(正则以自己写的过段时间自己都看不懂而知名)。因此,用这种办法做出来的文档没什么通用性和可扩展性,换一个文件,就要重新加全部奇怪的标记,甚至重写js代码和正则表达式,想修改,超长string把我的notepad++都弄崩溃了,读起来文本费眼劳神,还没有现成的工具链(mdx用的html虽然也不咋样,但有很多处理工具),它整体上只是奇技淫巧的个人玩物而已。
做网站的人,数据库用SQL等,渲染用模板,控制用css、JS,数据量不大,底层data就用JSON,还有的数据用xml这些,很少见到人用加了标签的超长string的,这不是毫无道理,因为它们结构简单,逻辑清晰,易于操控,通用性、可移植性强,有完善的处理工具链。像《洪武正韵》这种体量的书,纯文本本身就很好阅读和搜索,如果不满plain文本的单调、无格式,可以用markdown和html,如果还想以某种逻辑查询检索,用python、sqlite(js、JSON等亦可)写个简单的程序比制作这种满目正则表达式的文档也容易得多。
如果不想写程序而逻辑化地查询搜索,可以用excel,它完全能实现这个检索文档的功能,制作起来要简单得多。
今日从兹役
2022 年2 月 16 日 05:15
11
不敢苟同,我感觉你对这些也不太懂,说那么多都是不切实用的。你用来打开这种格式的程序就不对啊,word都要快得多,何况还有编程软件可以用。而且你只有检索字头的需求,mdx就够了,想要全面利用文本,mdx就无能为力,这个格式要好得多。你还提到Excel格式,更是远远比不上这种格式,这个格式用浏览器打开只能浏览,是无法改动的,Excel浏览时就可以改动,稍微不小心就误操作了,缺少稳定性,此其一。加载速度上html也非常快,Excel内容一多就会迟钝,此其二。Excel无法方便的实现复杂检索,此其三。搜索结果有多个时这种格式可以把结果同时显示出来,而视野中不会出现其他无关条目,一目了然,此其四。所谓奇技淫巧,这说法也很奇怪,有其他格式没有的功能还是坏事?
今日从兹役
2022 年2 月 16 日 05:26
12
就是有问题才发帖求助,你回复自己用就好有问题不用求助?你这是什么心理?这个格式在占有数据的角度有明显的优点,求助的一些问题对于会编码的人都可以轻易解决的,我利用这个框架制作这种格式的辞典也是出于公益之心。即便高人看不上这个,人家能顺手开发出更厉害的格式来也不错啊,毕竟这个格式就是有其他格式比不了的好处。
東君2021
2022 年2 月 16 日 06:34
14
Kanripo 网站的古籍,图片无法查看,不知各位是如何解决的?经常显示:No digital facsimile available for this text!WYG 002-1b
看了一下网页的内容,就是png文件。
用chrome、firefox,甚至很小众的opera,都没问题。
你用什么浏览器?某种中国的小小众浏览器?
呵,本论坛有不少会编程的人,你既然颇懂颇自信就等着看他们能不能把代码给你改好捋顺,然后也希望你能用这种文档格式制作出很多优秀作品造福他人。还有,我打开html用notepad++你说我用的程序不对,应该用word,真看不出你对写程序这个行当有什么经验与判断力。
jcz777
2022 年2 月 16 日 09:48
17
不明白,前面都给出部首了,后面还要重复两次。
一个人的看法会受到自己经验的限制,但是个人的经验有限,所以很难说一定对。
我的印象是:Ms Word打开大文件很慢。但是我的Word很旧了,也许最新版速度很快呢?
我的经验是:html不适合做大书,打开时会很慢。但是,也许某种浏览器能够快速打开呢?
鼓励制作分享,别泼冷水。
我推荐用Emeditor看中文文本。
先看一下notepad++的wiki介绍好了:
In 2014 Lifehacker readers voted Notepad++ as the “Most Popular Text Editor”, with 40% of the 16,294 respondents specifying it as their most-loved editor.[17] The Lifehacker team summarized the program as being “fast, flexible, feature-packed, and completely free”.[17]
In 2015 Stack Overflow conducted a worldwide Developer Survey, and Notepad++ was voted as the most used text editor worldwide with 34.7% of the 26,086 respondents claiming to use it daily.[18] Stack Overflow noted that “The more things change, the more likely it is those things are written in JavaScript with NotePad++ on a Windows machine”.[18] The 2016 survey had Notepad++ at 35.6%.[19]
Notepad++ is a free and open-source text and source code editor for use with Microsoft Windows. It supports tabbed editing, which allows working with multiple open files in a single window. The product's name comes from the C postfix increment operator; it is sometimes referred to as npp or NPP.
Notepad++ is distributed as free software. At first, the project was hosted on SourceForge.net, from where it was downloaded over 28 million times and twice won the SourceForge Community Choice Award f...
notepad++是打开2、3m大小的html看源码的当行里手,直接用Word把主楼的html打开,其实只能看到一个渲染出来的查询界面,原始文本看不到,JS代码也看不到,文件72个字符,打开快有什么用?这个文件用浏览器打开也很快,是因为打开的时候浏览器啥也不干,只调用html里的body部分,实际查询的时候触发js函数,然后在超长string( 源码为strr =" "; )里正则搜,幸亏如今浏览器js和正则的执行效率很高,文件不大的话也没什么妨碍。不过如果你把这个string换成90m的《汉语大词典》全文,然后再试试速度如何?我试了,我的VS code和EmEditor都在复制编辑的时候程序冻结了,不能正常使用。
不是别人爱泼冷水,楼主自陈“没学过编程,也完全不懂设计网页”,然后“格式讨论和技术求援”,我很诚恳地说出自己的看法,他的回应是“感觉你对这些也不太懂,说那么多都是不切实用的”,刚愎自用,再来一段洋洋洒洒的理由,也未必站得住脚。既然如此自信满满,又何必来跟人讨论和请求技术支援,自己按照自己的想法直接干就行了。
EmEditor主要是做mdx词典的人追捧,超大文件的处理比较流畅,有筛选功能等,作为文本编辑器,实际上突出的优点不多,第一,它不是开源免费的,第二,界面设计上也过时了,第三,插件不够丰富,也即功能有限。轻量级的文本编辑器,我觉得notepad++不错,喜欢多功能,VS code是这几年的不二之选。
jcz777
2022 年2 月 16 日 13:45
21
notepad++ 在作妖的道路上越走越远。
自从在notepad++在某个版本更新加入一句话后。许多人就对它不喜了,也包括我。