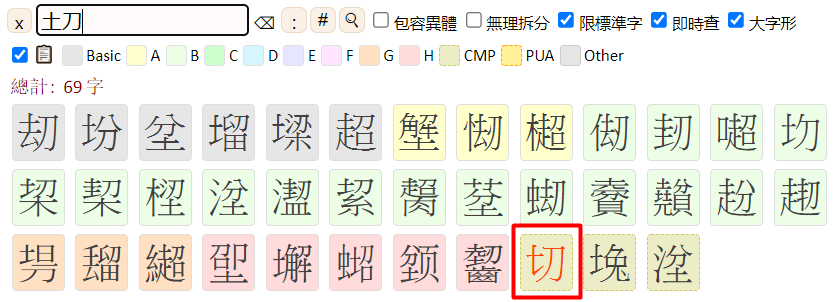
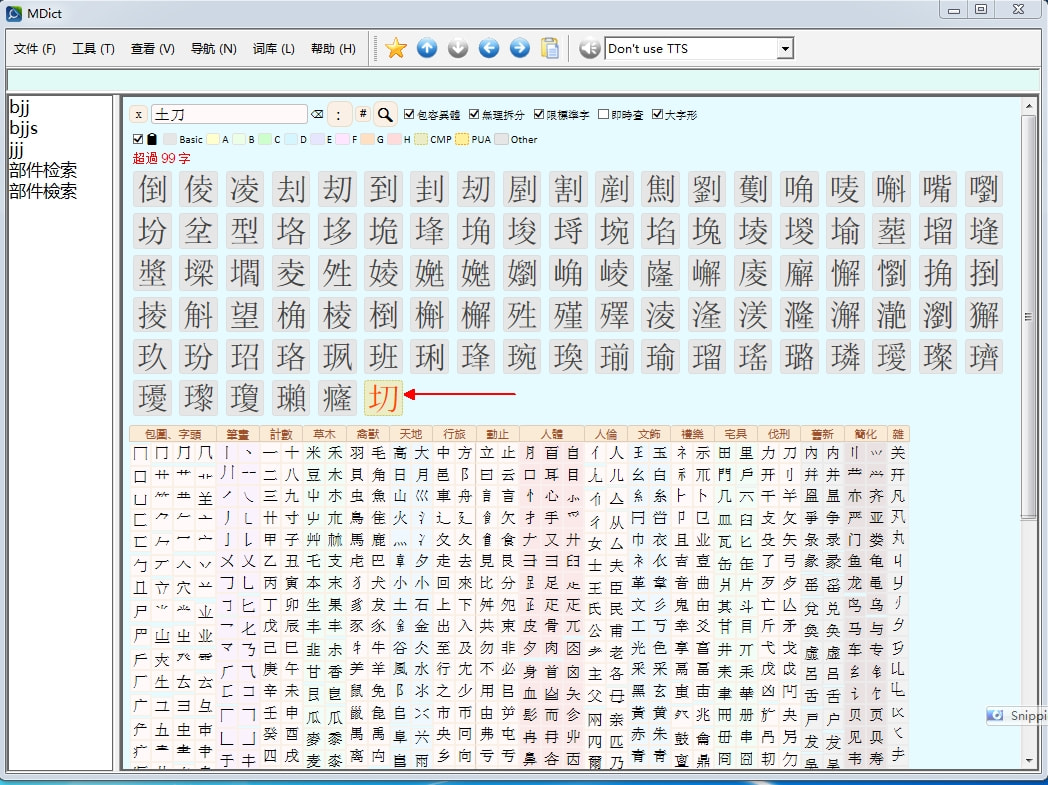
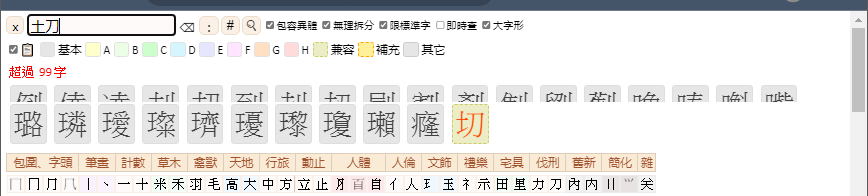
您好!为啥我手机dicttango里的部件检索,点搜索栏,却弹不出键盘?
你需要在阅读模式下打开这个词典,键盘才会生效
1 个赞
谢谢!问题解决了!
1 个赞
一直没等到坛友的2022.9.19全宋体拆分,忍不住鼓捣了一下fontcreator,自己动手拆分了。顺利升级到11.4的部件检索。独乐乐不如众乐乐,拆分后的字体和匹配的css在这里——
密码:free
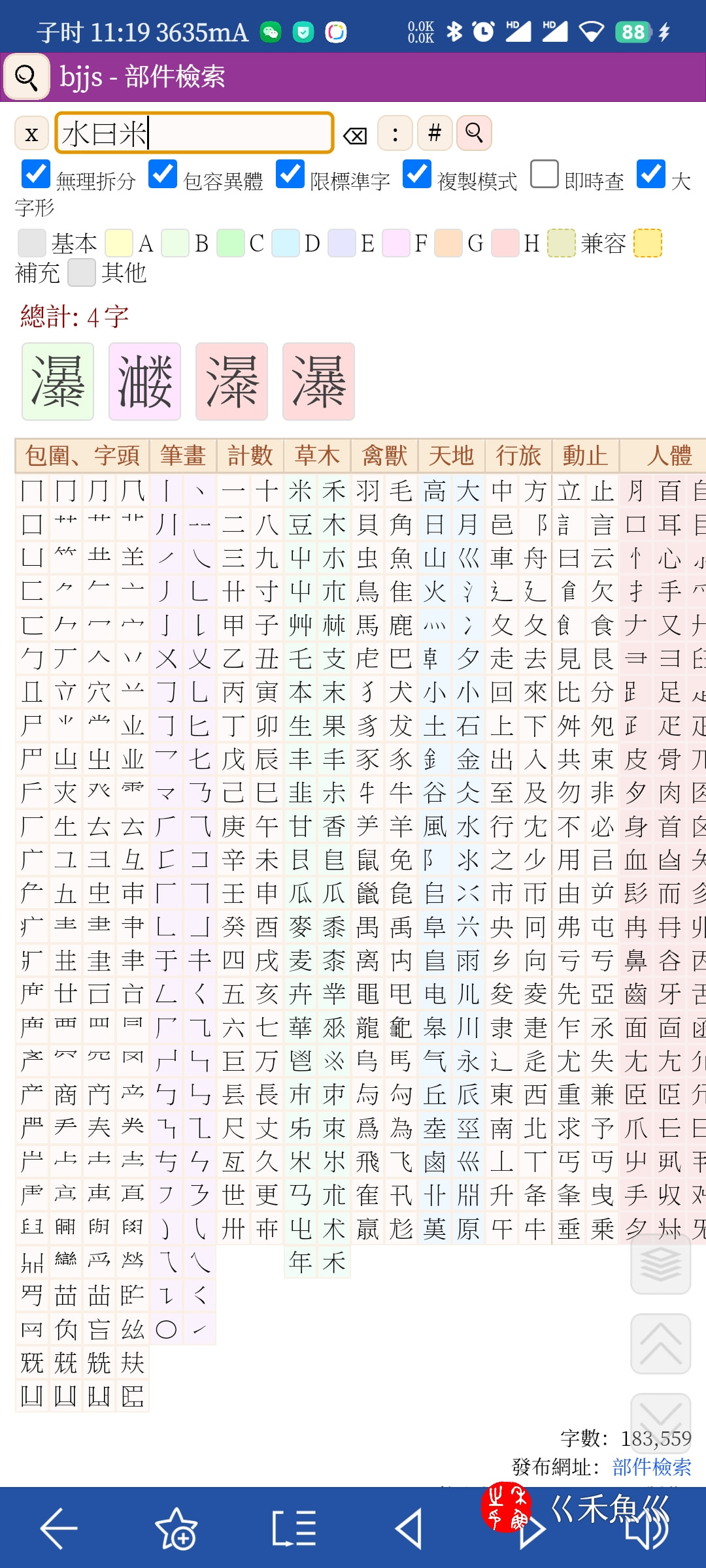
2 个赞
很好很好造福大众啊,fc也不知道如何拆分字体的

我的经验:
1,打开字体文件,并按照字码点排序。
2,随意找一个靠中间的字,先删除后面所有的,输出ttf或woff,关闭字体文件。
3,重复第1步,删除同一个字及前面所有的(保留第1个字符),再输出。
也可以按照字体文件左侧分类列表删除。
…
楼主,想问下复制模式是干什么用的?自己使用过程中没有发现它有啥作用,我复制都是鼠标划的
Copy mode means the character is copied to your clipboard when you double-click on it in the search results.
1 个赞
好的,知道了
不用複製模式,就會外接 叶典 查字。叶典,當字典或異體字字典,未必可靠,最有用的信息是這三個 fields:提交来源、中华字海、参考资料。叶典 對新擴展區,例如 G、H,信息比其他地方完整。
舉個例子:U+20C6B,部件檢索 T 形:

叶典 G 形:
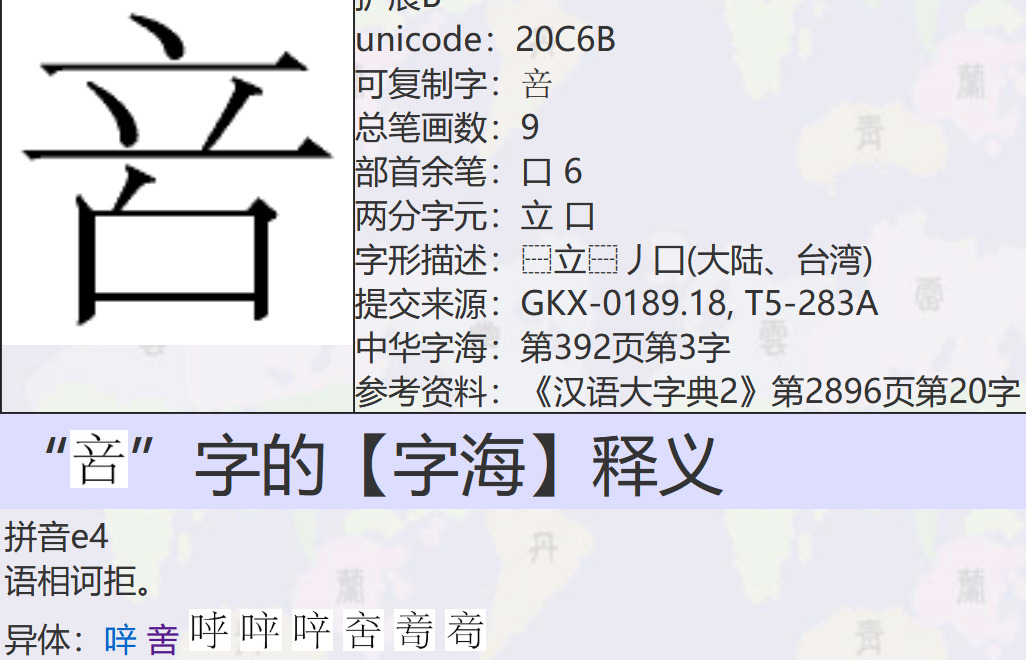
可以參考那三個 fields。
另外,注意 20C6B 的 T、G 形不同 – 這個字碼有問題,分別指不同字!
G 形來自《集韻》,《說文》作“𥩭”,注:“語相訶歫也”。《大字典》跟從《集韻》字目作 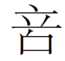
但 20C6B 的 T 形 是 “言” 的古文:
參考《教育部異體字字典》,“𠱫” 20C6B 同時是 “𥩭” 和 “言” 的異體,模棱兩可。
《說文》“𥩭”字條,《大字典》定字目爲 “𠱫” 20C6B,不妥。
說文mdx原來按照大字典定字頭,所以紊亂。該條列的字目反而是“言”的古文。
![]()
一个有意思的是我刚查了这个字,叶典:“该字编码已变,或没有编码=FD037的汉字!”
1 个赞
全宋體/部件檢索 的補充區(私有區、英文簡稱 PUA=Private Use Area),只是全宋體內部的東西,在其他環境無效。PUA 不是標準字,就是這個意思。
WFG 造了 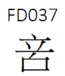 就是為了給全宋體補充 20C6B 的 G 形。
就是為了給全宋體補充 20C6B 的 G 形。
繁體 font 缺 G;簡體 font 缺 T。所以中華書局字型 (font) 缺 20C6B 的 T 形,無法顯示 "言” 的古文: 
好的,谢谢,我不太了解这方面的知识,感觉挺有意思的 ![]()
1 个赞
我剛好在琢磨如何定《說文》的主字目。發現《康熙字典》“㖕”字條引《說文》,「䇂」誤作「辛」,則隸定作 “㖕”:

說文原文: 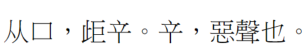
![]()
《廣韻》隸定作 “𠲗” ![]() ,不誤。
,不誤。
1 个赞
这些小问题确实比较麻烦,辛苦了,对您的付出表示敬佩! ![]()