一楼更新:
单机浏览器测试版(Win10 64位版,其他Windows 64位机应该可以走起来) 链接: https://pan.baidu.com/s/1jNDXV7X_I_KCDOsqBk9saA?pwd=g634 提取码: g634
解压后点击 start-radiobee,在浏览器地址栏输入 127.0.0.1:7860 回车。
有什么问题跟帖。已经有人运行成功…… 先解压,路径名里最好别有中文。
一楼更新:
单机浏览器测试版(Win10 64位版,其他Windows 64位机应该可以走起来) 链接: https://pan.baidu.com/s/1jNDXV7X_I_KCDOsqBk9saA?pwd=g634 提取码: g634
解压后点击 start-radiobee,在浏览器地址栏输入 127.0.0.1:7860 回车。
有什么问题跟帖。已经有人运行成功…… 先解压,路径名里最好别有中文。
运行自带示例正常;但是我的两个文件对齐时在线版和单机版都显示错误。不知何故。
test_en.txt (1.8 KB)
test_cn.txt (1.1 KB)
下面是报错信息:
Coming up… it may take a while (…)
用法:
窗里出现 Running on local URL: http://127.0.0.1:7860/
字样后,用浏览器访问 http://127.0.0.1:7860
将需对齐文件拖到 FILE1 FILE2 处,再点击 Submit。
或选择点击 Examples 里文件再点击 Submit。
e2c lzma file loaded
Press Ctrl+C to quit
[I 211231 10:12:43 __main__:97] info
[I 211231 10:12:43 __main__:382] running at port 7860
D:\VIPSFT\Radiobee Aligner v0.1.0.beta1\python-3.8.0\lib\site-packages\gradio\interface.py:253: UserWarning: The width and height parameters in the Interface classwill be deprecated. Please provide these parametersin launch() instead
warnings.warn(
Running on local URL: http://127.0.0.1:7860/
To create a public link, set share=True in launch().
[I 211231 10:14:29 __main__:217] file1.name: C:\Users\LDS_NO~1\AppData\Local\Temp\test_cnvndnvz_7.txt, file2.name: C:\Users\LDS_NO~1\AppData\Local\Temp\test_enc1ghbnd2.txt
Traceback (most recent call last):
File “D:\VIPSFT\Radiobee Aligner v0.1.0.beta1\python-3.8.0\lib\site-packages\gradio\networking.py”, line 196, in predict
prediction, durations = app.interface.process(raw_input)
File “D:\VIPSFT\Radiobee Aligner v0.1.0.beta1\python-3.8.0\lib\site-packages\gradio\interface.py”, line 373, in process
predictions, durations = self.run_prediction(
File “D:\VIPSFT\Radiobee Aligner v0.1.0.beta1\python-3.8.0\lib\site-packages\gradio\interface.py”, line 339, in run_prediction
prediction = predict_fn(*processed_input)
File “radiobee_main_.py”, line 317, in fn
pset = gen_pset(
File “.\radiobee\gen_pset.py”, line 82, in gen_pset
iset = interpolate_pset(, tgt_len)
File “.\radiobee\interpolate_pset.py”, line 25, in interpolate_pset
y00, * = zip(*pairs)
ValueError: not enough values to unpack (expected at least 1, got 0)
可能文本太短了,3、5段?…… 正在修这个bug
太猛了,期待结果……
你是用hf spaces网页版还是单机版?
… 这两个文件都是按照段落对齐好的 …
已经对齐好的还对什么? radiobee目前还没加上分句及句句对齐开关。
我用的是单机版。运行了大约3530多秒后被小孩不小心关掉了。
可能我的想法比较怪,就想看看已经对齐的(段落对齐的两个文档),使用该软件会有什么结果?
结果是:1)一本500多kb大小的、已经对齐的专业书籍(有很多术语),经过很快处理后重新对齐了,绝大部分对齐很好,估计15%的句子没对齐。2)第二个我上面所说的大文件跑了1个多小时也没结果。
我的结论是相对于哪些做了好多年的对齐软件,这个初步预览版无论是速度或对齐的程度,已经相当厉害了!
测试结果供您参考!
感谢反馈。
可以说,速度和对齐非对称文本(比如译文里有编者按、前言、大段译者注什么的)是radiobee 的强项。
那个对短文本时出现的bug已经修好了。beta2版时会更新。
哥们,期待beta2能加入一个把一行或一段英文和一行或一段中文格式的文件的对齐功能,网上很多双语文本都是这种格式,如经济学人,纽约时报,VOA等。
这样对于混排格式的文件进行预处理后,下一步就可以利用RadiobeeAligner直接进行处理了。
cn.txt (134.1 KB)
en.txt (173.2 KB)
PS_Chinese_2012_Full-Document.pdf (1.0 MB)
PS_English_2012_Full-Document.pdf (489.6 KB)
我这里有两个文件是从PDF复制出来的,对齐的效果不理想,Abbyy Aligner的准确率要高一些,您可以对比一下,看看是什么原因,有可能是因为这些文档有脚注。
双语对齐在技术上确实是有难度的。30多年来,结合人工智能的机器翻译和语音识别技术你看发展多么迅速,取得的进步有目共睹。就这个双语对齐,一直在喊,一直在尝试努力。好多自然语言处理的博硕论文不断就句子层次的对齐进行着执着的研究,似乎进步不大,也没有实际的应用产出。一个个曾经涉猎的公司都放弃了,就连大名鼎鼎的SDL 公司集成在Trados的对齐功能效果也是惨不忍睹!楼主初步尝试我觉得起点已经相当高了!希望继续努力!
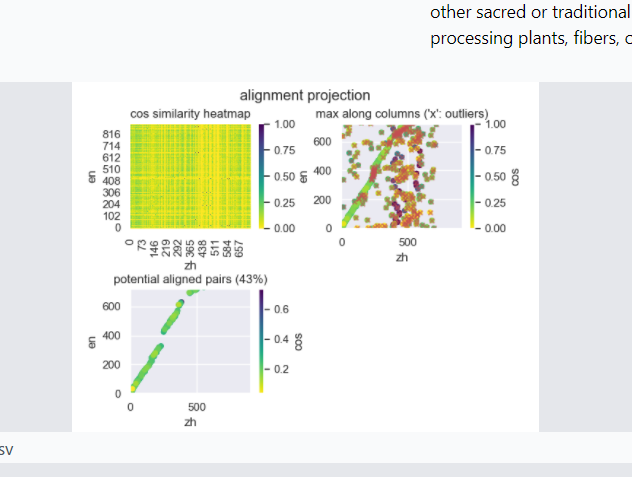
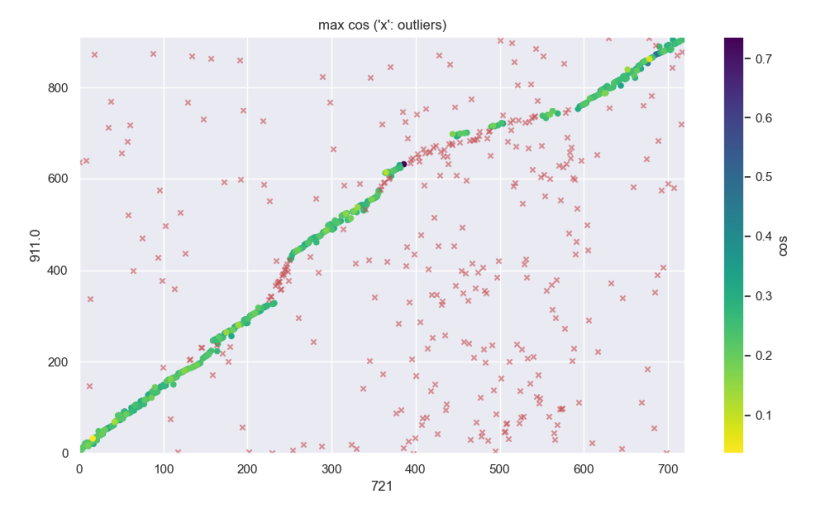
感谢反馈。看了一下文本的内容和对齐结果,貌似第三个图那根对齐线不太对,从两个文件的内容看那根线应该在 (912, 721)结束, 而不应该在图里 (500, 721)处结束。我看看是怎么回事,可能有个bug。按道理脚注是不会影响对齐过程的。但有可能因为段落长度分布太分散(存在许多很短的段、许多很长的段)导致一些误判。
我交互走了一下,确认并无bug。完整的对齐线如下图的绿线(淡红’x’是噪声(所谓的outliers))。上图的对齐线在(500, 721)处结束是因为图的画布(Canvas)不够高导致上面一部分没有显示出来而已。
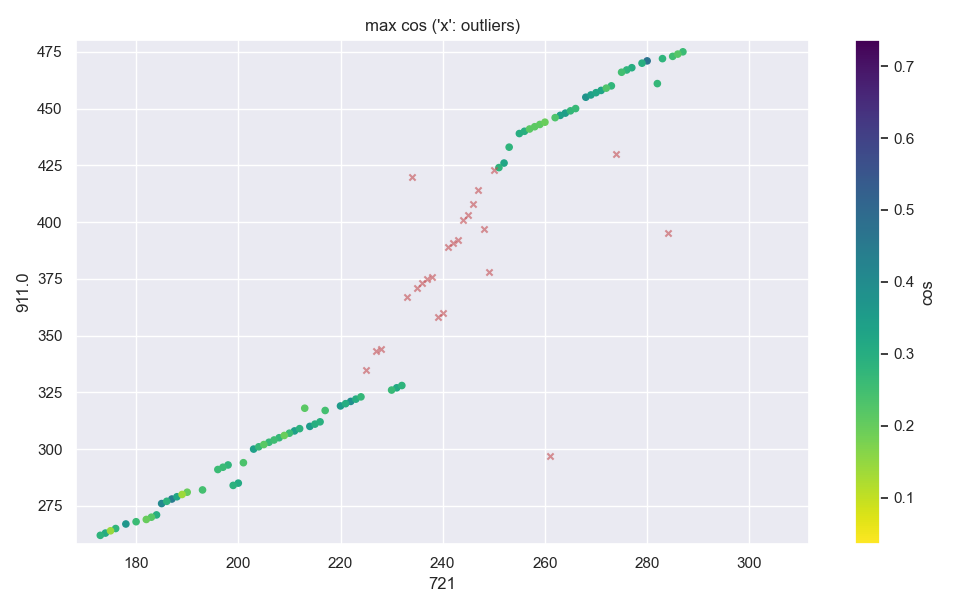
可以从上图里看到,英文(纵轴)第400段周围那些淡红x显示,radiobee未能找到对应的合适中文译文(假若找到了的话那地方应该是绿色)。
放大英文第400段处:
6 调到 4 效果会更好些。eps也可以稍微调小点(大于1.73或2即可)。
另外,我再看看能不能在获取对齐线过程中摒弃一些太短的段落,或是加个开关可以让用户选择这样做。再次感谢反馈。
谢谢赐教,明白了图像的含义。
大佬说的是中英一中一英相间的文本?这种仅涉及到分离,比较简单,可以做段对段分离,分离后已经是段对段对齐的。没必要全文分离合在一起再做段段对齐。我看看这个 gradio (radiobee 用的接口)可不可以设成上载一个中英混合文件,然后分离成段段对齐。
如果中英混合文本分离对齐后,若再用句子开关进一步对齐,岂不是Radiobee可将所有格式的中英文件做对齐处理了,所以,这个对齐从细节上来看是很有意义的。另外,Radiobee Aligner对齐效果的图像显示确实不错,直观明了,这也是一大特色啊!
很强大,处理速度很快,不知理论上能实现句级对齐吗?
beta2会加上分句、句句对齐功能。
beta2还会加上 单文件中英混合文件的自动分离 功能。
新年伊始的第一个好消息!十分期待!