我平时在探究汉字字源、汉字音读的语源时,经常会查阅上古音、汉藏语系等资料,并尝试重构其语源。在这个过程中,我一直觉得,如果能够把属于同一声符的形声字整理在一起,并一眼看到它们的上古音和中古音,那就会非常方便。若能一眼比较同一声符组中各字的上古音、中古音,那么即使是尚未拟构上古音的字,也能通过比较而更容易地进行拟构。有时候,这也会为修正、改进既有拟构,或进一步探究更深层次的语源提供线索。
我本人采用的是白一平—沙加尔(2014)的上古音体系。白一平—沙加尔在2015年曾于其主页上公开了约五千字的上古音、中古音列表 Excel 文件。不过,该资料中未收录的汉字也很多,因此时常会遇到需要自己重新拟构的情况。
这次在这里公开的,是我几天前发布的《上古音—中古音综合字典》的全面修订版。为了方便中国朋友使用,语言也已经完全统一为中文。此外,这一版还新增了相当多的功能。
特点:
-
收录了白一平—沙加尔(2015)资料中约五千字的数据,并完整收录了《广韵》和《集韵》的中古音。现在调查中古音时,已经不需要再查看其他 MDict 字典。
-
《广韵》以 Mastameta 先生制作的 MDict 字典为底本,只将 PUA 字符(非标准 Unicode 汉字)依据韵典网(ytenx)的数据全部校正为标准 Unicode 汉字。同时也完整保留了 Mastameta 先生对《广韵》文本的校勘内容。
-
《集韵》以 LeiMaau 先生制作的 MDict 字典为底本,仅在 ChatGPT Pro 的帮助下添加了标点。毕竟有标点总比没有标点更便于阅读。不过,在解释联绵词等二字以上词语时,词语内部的释义有时没有加逗号“,”,阅读时只需留意这一点即可。
-
《广韵》《集韵》以及白一平—沙加尔(2015)中收录的所有中古音,都整理了白一平—沙加尔(2015)式中古音标记,以及对应《广韵》体系的韵、声母、等。反切则按《广韵》《集韵》原文照录。
-
声符组数据取自字统网(zi.tools)的“声旁”功能。
-
现在可以查看同一声符组中的《诗经》押韵情况。
-
现在可以查看同一声符组中的通假字。
-
现在可以查看同一声符组中的两汉声训。
-
两汉声训数据取自古音小镜的数据。
-
现在可以查看同一声符组中,哪些汉字在 STEDT Database 中与汉藏语系词源相连。
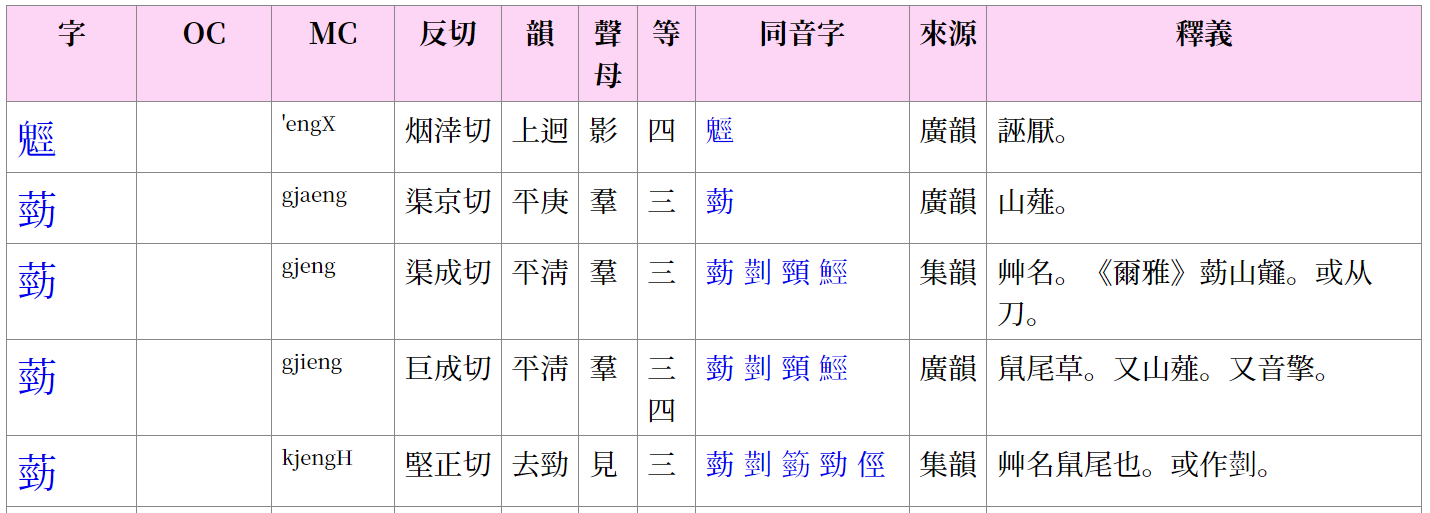

使用方法:
-
搜索某个汉字后,会显示与该字同属一个声符组的所有汉字。(例:“家”)
-
在上方,可以针对当前画面中显示的所有条目,只查看其中不重复的上古音(OC)和中古音(MC)值。(“OC、MC 摘要”功能)
-
在“OC、MC 摘要”功能中,点击某个音值后,会显示具有该音值的所有汉字;再点击其中某个汉字,就会自动滚动到对应的行。
-
其下方有“广韵”“集韵”“一音一行”三个复选框选项。白一平—沙加尔(2015)的资料会始终显示,而这些选项则用于选择是否额外显示《广韵》的中古音和《集韵》的中古音。默认设置为显示。

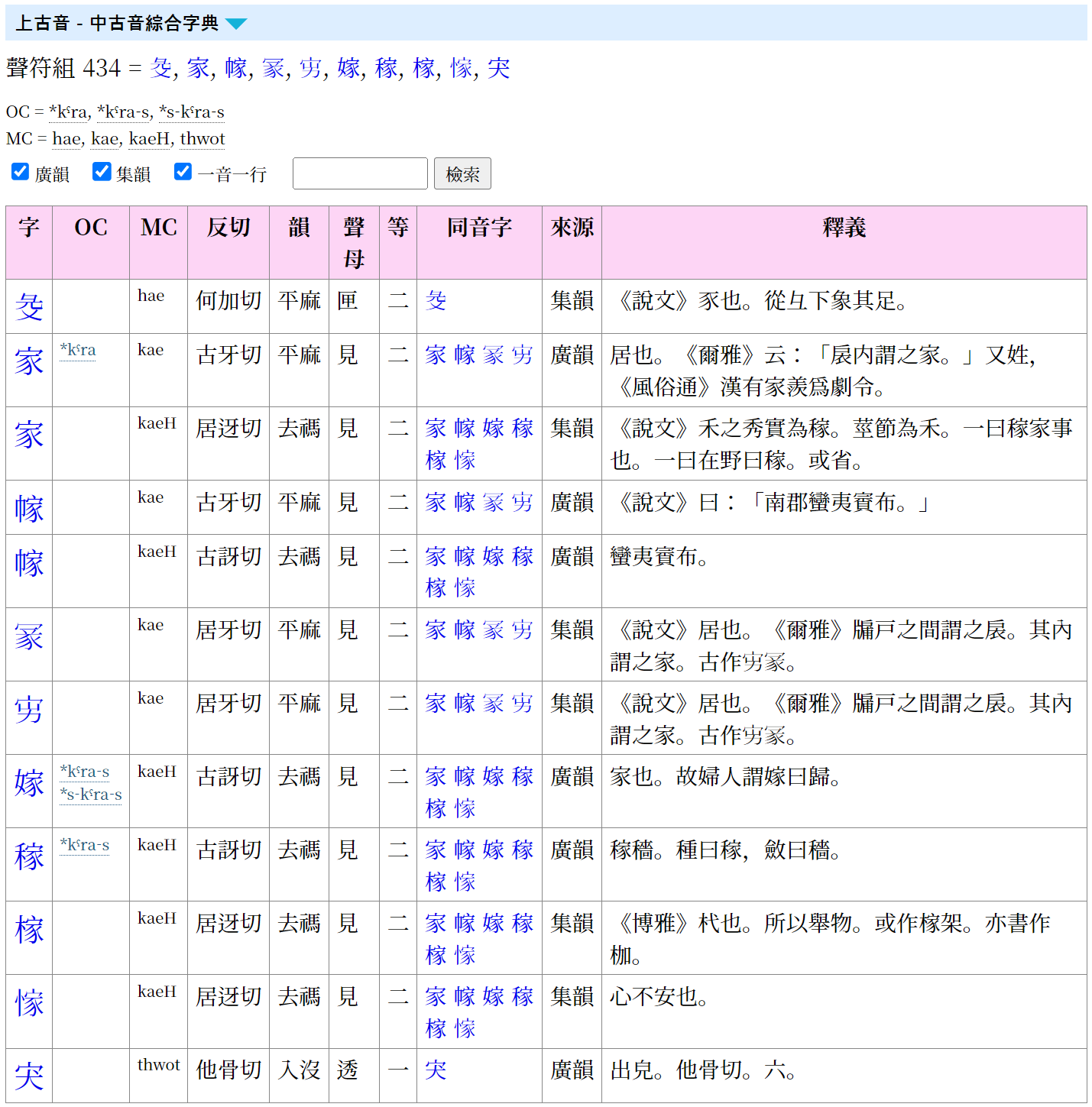
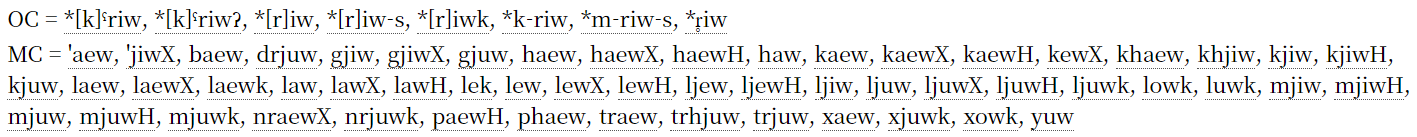
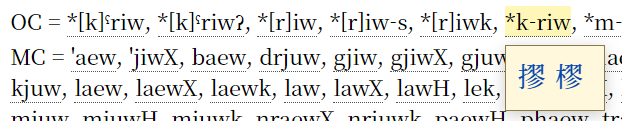
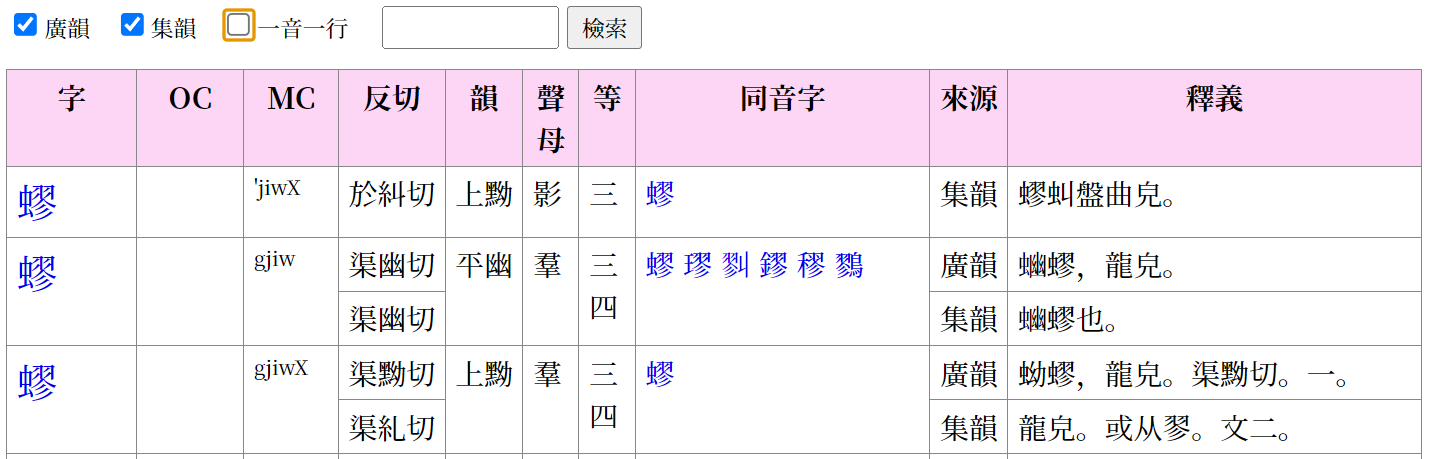
“一音一行”是指相同中古音只显示一行的功能:如果《广韵》中有该中古音,就显示为《广韵》行;如果《广韵》中没有、只有《集韵》中有该中古音,就显示为《集韵》行;如果两者都没有,只出现在白一平—沙加尔(2015)资料中,则显示为 B&S 行。这样可以避免出现过多的行。不过,有时也会想比较同一中古音在《广韵》和《集韵》中的内容,这种情况下取消勾选即可同时查看两者。
启用“一音一行”时的画面:

关闭“一音一行”时的画面:
-
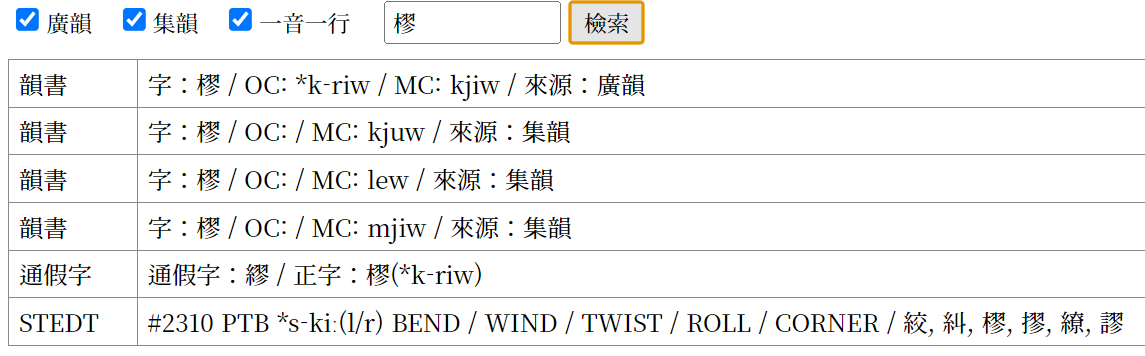
右侧有一个汉字搜索栏,这是用于在当前画面显示的内容中寻找目标汉字的功能。如果感兴趣的对象不是整个声符组,而只是某一个特定汉字,就可以使用这个功能快速跳转到该字的数据。
-
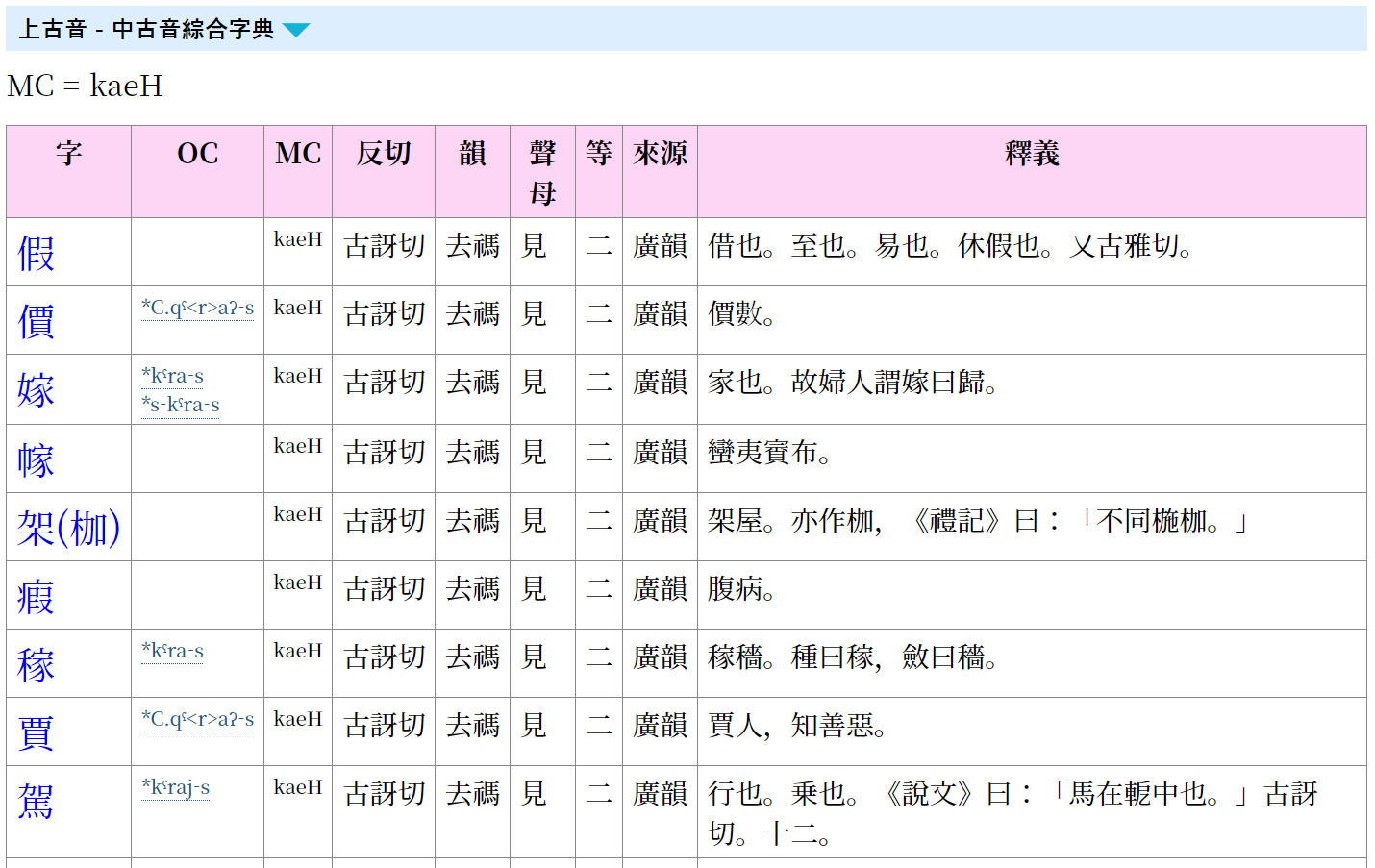
此外,本字典还支持输入“kaeH”这类白一平—沙加尔(2015)式中古音标记,从而方便地查找具有该中古音的同音字。
各位实际使用之后应该就会明白,虽然这样说也许有些冒昧,但我敢说,这恐怕已经是相当难得的、极为方便的上古音和中古音资料了。它可以说正好解决了许多研究过程中令人感到不便、却一直缺少合适工具的问题。
我一直以来从这个社区得到了许多帮助,因此也觉得自己应该有所回馈,便将这本字典分享出来。
希望大家能和这本字典一起,度过更加愉快的研究生活。
谢谢大家。
下载: 上古音-中古音综合字典(全面修订版/中文版) - FreeMdict Cloud
※ 本字典使用的字体为 Noto Serif CJK TC 和 Jigmo。如果系统中尚未安装这些字体,需要先行安装,汉字才能正常显示。
※ 我是韩国人,从2009年刚开始学习汉字时起,就开始研究汉字字源。我的现代汉语并不算十分流利,因此本文的中文内容是借助 ChatGPT 自动翻译整理而成的。