【mdx分享】21世纪大英汉词典(全索引)427万词条(165MB)
博主我在备考GRE的时候用的欧路背单词,其中用到的一本词典就是《21世纪大英汉词典》,其MDX文件作者不详,时间不详,获取渠道我记得大概是这里:
我也创建了我的分享链接:
-
Google Drive:https://drive.google.com/file/d/13J8KGtYh3HqRiPnRcyg-jPJegSB-Q6xk/view?usp=drive_link
-
Quack:https://pan.quark.cn/s/bb79d86ab890
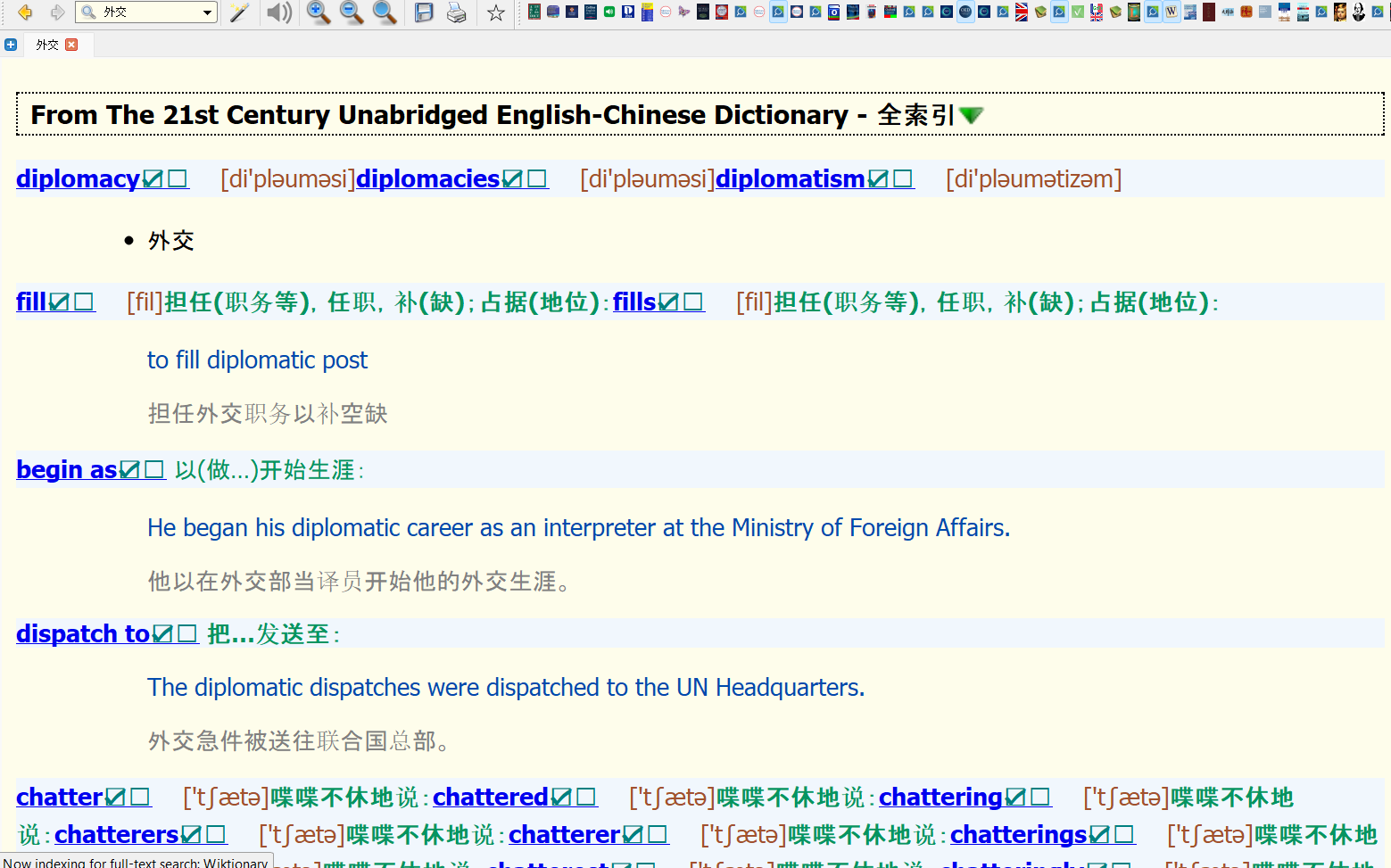
这本词典排版虽不是很华丽,但是简约清晰,收词量巨大,一共427万词条
同时也支持中文反查:
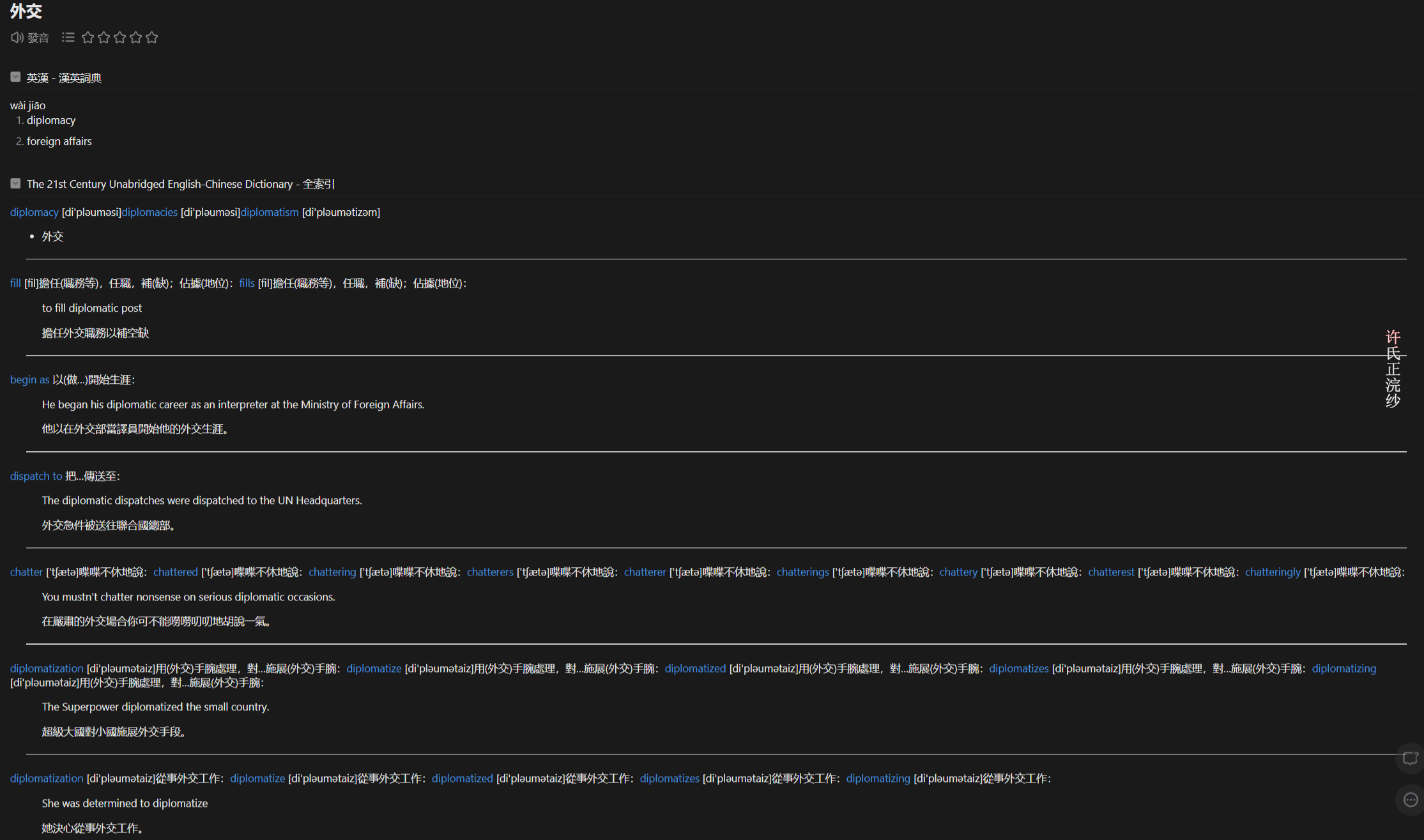
不同的软件显示的风格不一样,比如欧路这个要好看一些:
我一直老喜欢这本词典了,这是我见过最全面的中-英词典,释义水平也接近Merriam-Webster(听说就是以这个为底本修订的)。
我根据这个词典,使用notepad++结合正则提取了所有拉丁语的词头(仅有词头),同时对Merriam-Webster‘s Collegiate Dict 11ed也提取拉丁语词条,合并去重,做了一个“英语中的拉丁语”词典(仅有词头)
Latin_Vocabs_in_Eng.mdx (41.6 KB)
根据站内的帖子分享一批自己修改的css文件(共15部词典) - #31,来自 knetxp
我发现我的这个版本是有少许错误的,也就是这篇帖子贴出来的错误我自己去查了一下,确实是错的,且也出现了帖主说的重复现象。
我询问了他是否有修订日志,他说他也是用记事本暴力改的。
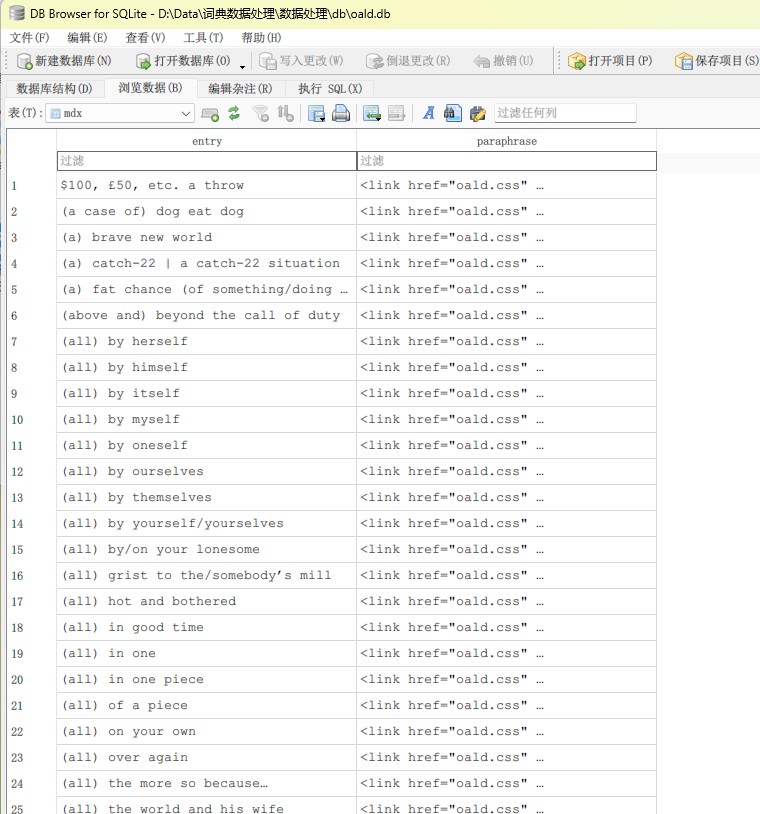
我自己编程水平不好,AI写的代码不敢直接弄。我尝试使用了某个命令行程序解包了这个mdx,结果如下:
解包之后txt文档高达1GB,用notepad++操作起来经常死机,所以我也没有什么好的方法修改。
希望有大神可以军训一下这个词典,我觉得这本词典的价值挺高的,不管是对于爱好者还是学生。
您也可以根据下面的邮箱联系我,或站内私信:
raterchan398087@gmail.com
我不会啊,我用一个命令行工具解包了,从里面提取出拉丁语词条,做了一个新的词典。本体我没动,这个太大了notepad++编辑不动,程序又不会写,有点菜 
你把它扔出来,自然有人帮你看看,或许对大家都有启发 
但是站内有人修改,我初来乍到我也不知道在哪找回那个帖子了,他编辑的是37万~42万(去重多少的区别)的版本,只能单向查,不能反查,我问他有没有修改日志,我拿过来我多少能改一点点,但是他说没有,他也是直接拿记事本干了
我存在Google Drive了,链接如下
MDX:
https://drive.google.com/file/d/13J8KGtYh3HqRiPnRcyg-jPJegSB-Q6xk/view?usp=drive_link ,我等下研究一下怎么用夸克再发一个出来
CSS:
21世纪大英汉词典.css (6.5 KB)
这里面包含MDX和CSS,具有断代能力的大神可能可以根据CSS来判断我这个是哪个版本。
建议用python处理…比较大的mdx一般都不会选择转为mdx而是转为db文件
Ivlivs
12
我也想过是否用数据库更有逻辑,然后用数据库软件弄起来比较好,可惜我的命令行软件只能转TXT,请问您有更先进的经验或者软件吗
python mdtta 解压成.db数据库。
可以用DB Browser打开
其实就是一个大型的xlsx二列表格。
但是可以使用SQL语句快速执行一些修改。
应该也有其他非python的解包方式,不过我好像不清楚。
mdtta 这好像也是论坛内的一个朋友写的。至于使用说明pypi官网写的很清楚
Ivlivs
15
可以可以,谢谢啦。我有编程基础,有文档前提下,我捣鼓一下应该能解决,感谢
这个命令行工具好像文档里写的有问题,貌似不能识别meta.toml文件 每一次打包都要制定-m
解包
mdtta extract oald.mdx -o .\output --db
输出meta.toml和oald.db
打包
mdtta pack -a oald.db -m oald.meta.toml oald.mdx
Ivlivs
17
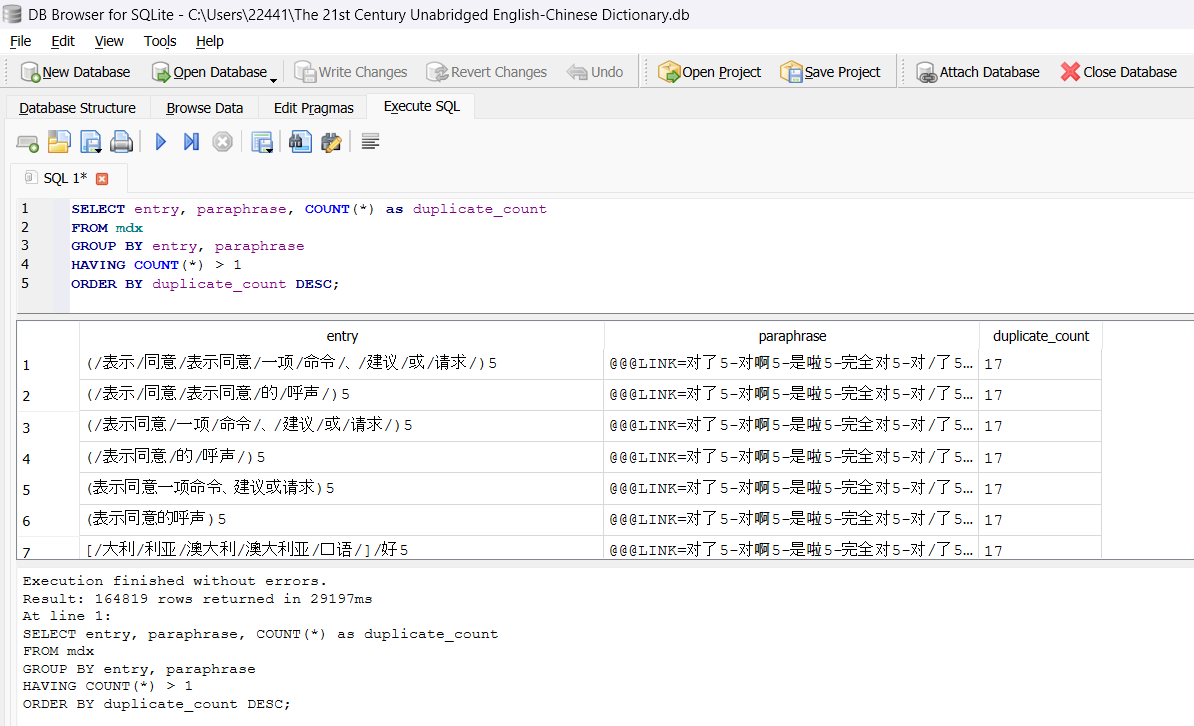
谢谢,已解包成功。我初步尝试使用语句查了一下,发现有16万行左右是重复的(键值分别相等的行记录),对比428万总词条,占比很少。后续我再试试更精确的方法。