这个版本和外观是真的顶,作者辛苦,一用就爱不释手了
这是哪个版本,看着新喜欢
跳行来显示伪元素标注(跟颜色无关)。

小改动过CSS代码,有需要的自行修改。
CSS
hdcs .hw::after {
content: "抖音\a汉语";
}
hdcs.xml .hw::after {
content: "第一版\a+訂補";
white-space: pre-wrap;
}
hdcs.xml[book="128"] .hw::after {
content: "近代汉语\a词典";
}
hdcs.xml[book="40"] .hw::after {
content: "现代汉语\a大词典";
}
hdcs.xml[book="3"] .hw::after {
content: "汉语\a大词典";
}
“洒”“折”等字,有把多个字音释义给合到一个字音的情况。xml里也有这个问题吗?
你在辞海网核对就行,何必问我。
建议楼主,还是加上词头、例句的发音,好些。
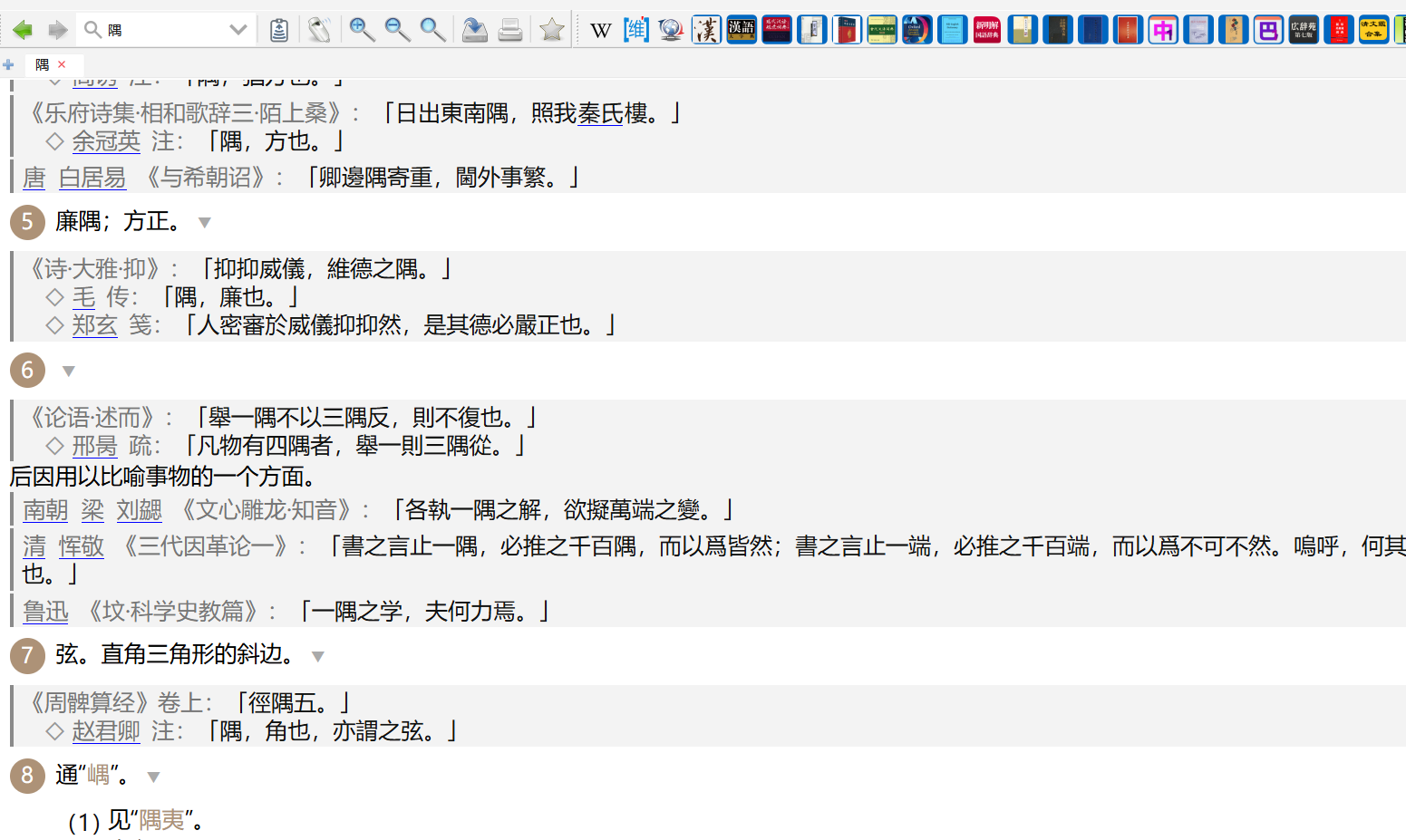
你不怎么用汉语大词典吧。。。这是常见体例,全书有很多处很多处(别的古汉语词典,成语词典也常见)。这种问题你应该自己先核对纸书pdf。
更新了一下把音韵部分给开启了,不过这颜色和样式不知道大家怎么看待,我尽可能融合了下,显示的具体位置目前还没改,所以mdx没更新,我先更新了百度网盘论坛网盘我稍后上传
作者是不是改名了,以前叫【youniworty】?
唉:-(你们做的大多数是屋内架屋、床上叠床的劳动,leon兄弟怕是隔着屏幕都要冷笑几声。leon所据的聚典源数据本身就有内容羼乱问题,如果此类内容本体问题得不到“匡正”,套的壳再好也是白搭。我之前做的很大一部分工作就是鉴于此而来的,现在主要的待解决问题之一是多音字字条的羼乱交杂问题(辞海网有好几处多音字字条,显见的将跨字条内容掺混在一起了)。如果你们有人能发挥点实证精神,比照纸书文本、光盘数据和我先前发布的筛核处理数据,就有数的多音字字条数据进一步排查厘正,也算功德一桩了。
用AI做的:汉语大词典 基于leon版,优化简繁对应等
凑合能用吧……聚典不是官方数据嘛,这么多问题……
聚典源数据虽说不是很精善,但整体质量还是优于光盘版数据的,还有就是把订补本数据也整合到一起也算一个长处。现在可见的问题还算少的,可惜我一个人心力容有不逮,字条这一块还没能跟进。你们即便用ai修改也请尽量一并附上具体条目修改记录。不然各人各种改法,前人有失察处而来人又不详辨,重悂累谬,诖误不小。
好,回去指挥AI拉个清单出来![]()
汉语大词典论坛上的版本已经相当繁杂了,现在无论是怎样继续修改下去都只是有屎山上雕花,现在或许只有新版的汉大词典的mdx出来才有可能能够解决吧
根据经验,AI的上下文长度无法支持这个工作,肯定会有缺漏的,一开始修改的时候就要让AI列出清单的。
再者,你可能没用AI做过古籍校对,AI的意见基本上至少会有20%的错误(就我用的gpt5.5而言,而且我是分段输入)。汉语大词典有这么多的古代引文,真的难以保证。AI只能用来辅助写程序,精确的字典编撰和字典校勘是很难做好的,人工审核的介入是必须的。
用的antigravity/codex,ai自己抽样分析、写脚本处理。整个塞肯定塞不进去啊
这里就有很大的错谬和幻觉空间以及上下文限制。
有些(比如简繁对应)我让他参照了以前tsiank那版。整个人工校对工程量太大了,我是觉得如果ai搞的比较好,就可以用着,追求完美就发现一个改一个。
谈何容易。哪怕新版汉大出来也需要人工校验。就像钟表不可能永远准确,没有什么数据是百分百完美的 ![]()