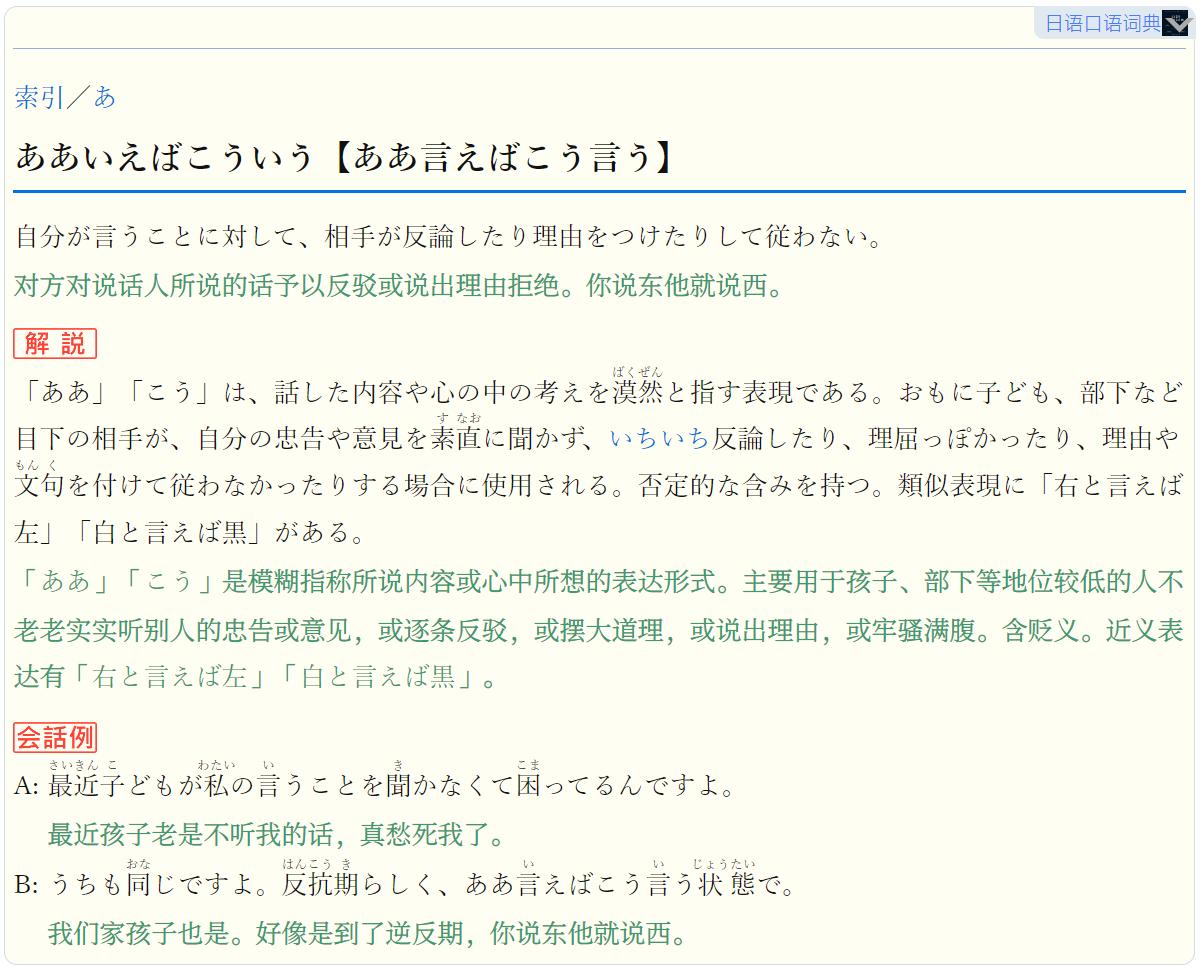
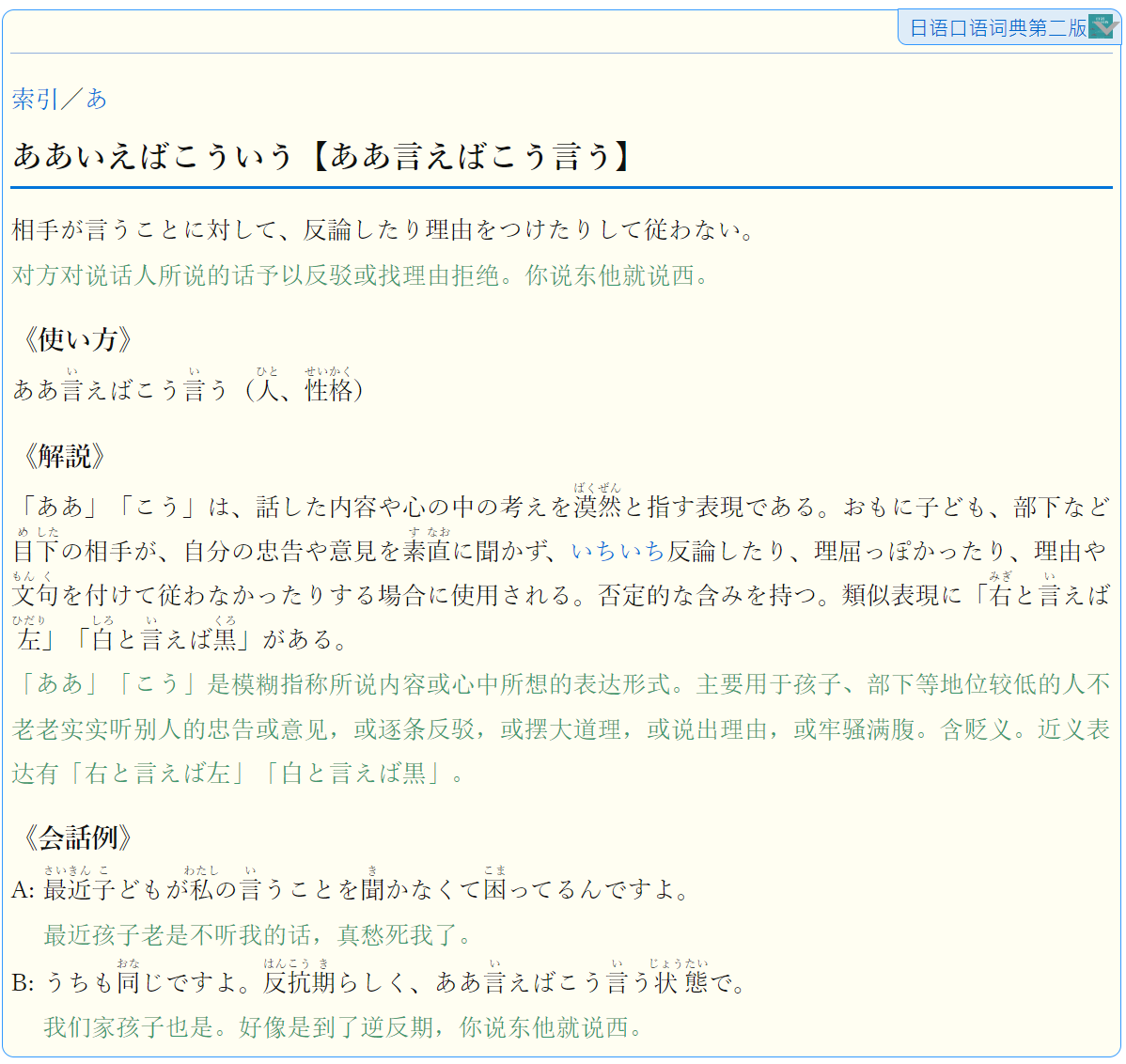
使用logovista数据快速转换的,没有改样式,直接合并了原样式,保留了附录等,不如第一版的样式好看,不过这一版比较新而且有furigana。
下载:
KQCOLEX2.mdx (1.5 MB)
KQCOLEX2.css (3.4 KB)

或
通过网盘分享的文件:研究社 日本語口語表現辞典 第2版
链接: https://pan.baidu.com/s/1eyNxC9yUvsujYv5pl6CPyQ 提取码: 1234
原始数据和脚本:
KQCOLEX2.zip (6.0 MB)
第一版的美化版感觉还没捂热呢,楼主第二版就端出来了,效率真是杠杠滴。 
之前研究新明解类语以后发现这个结构基本一样,就顺便做了。 第二版也有中文版,感觉可以扫描一下做双解版本。
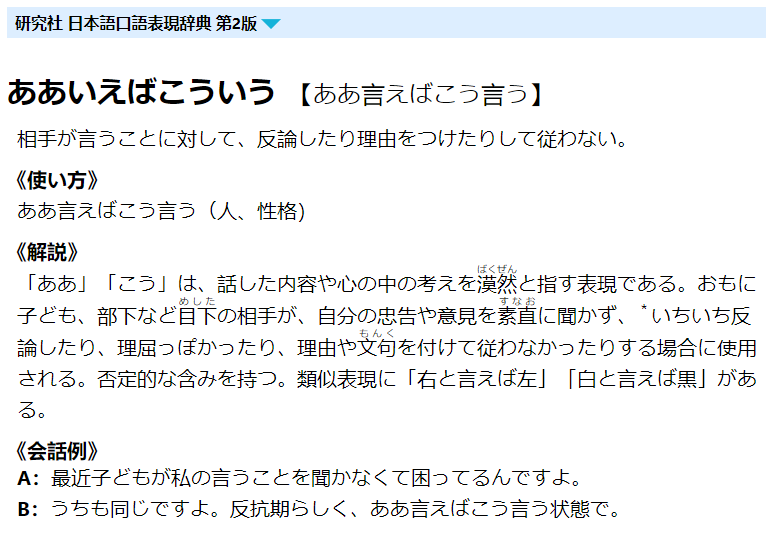
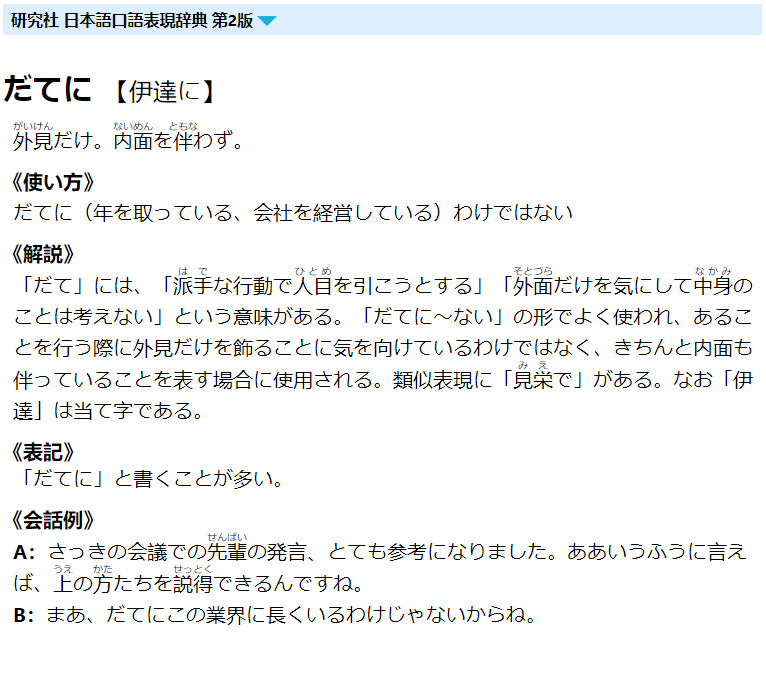
总算有人想弄这部了,logovista 的制作不难,但要注意类似这种 “あいきょうがある【愛嬌・愛敬がある】” 的拆分,要分成 “愛嬌がある” 和 “愛敬がある”。
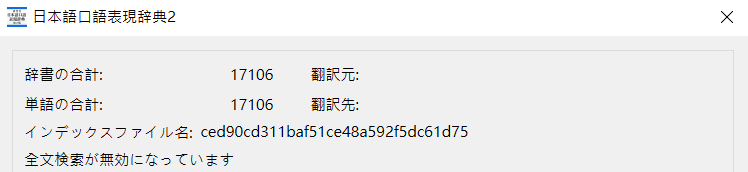
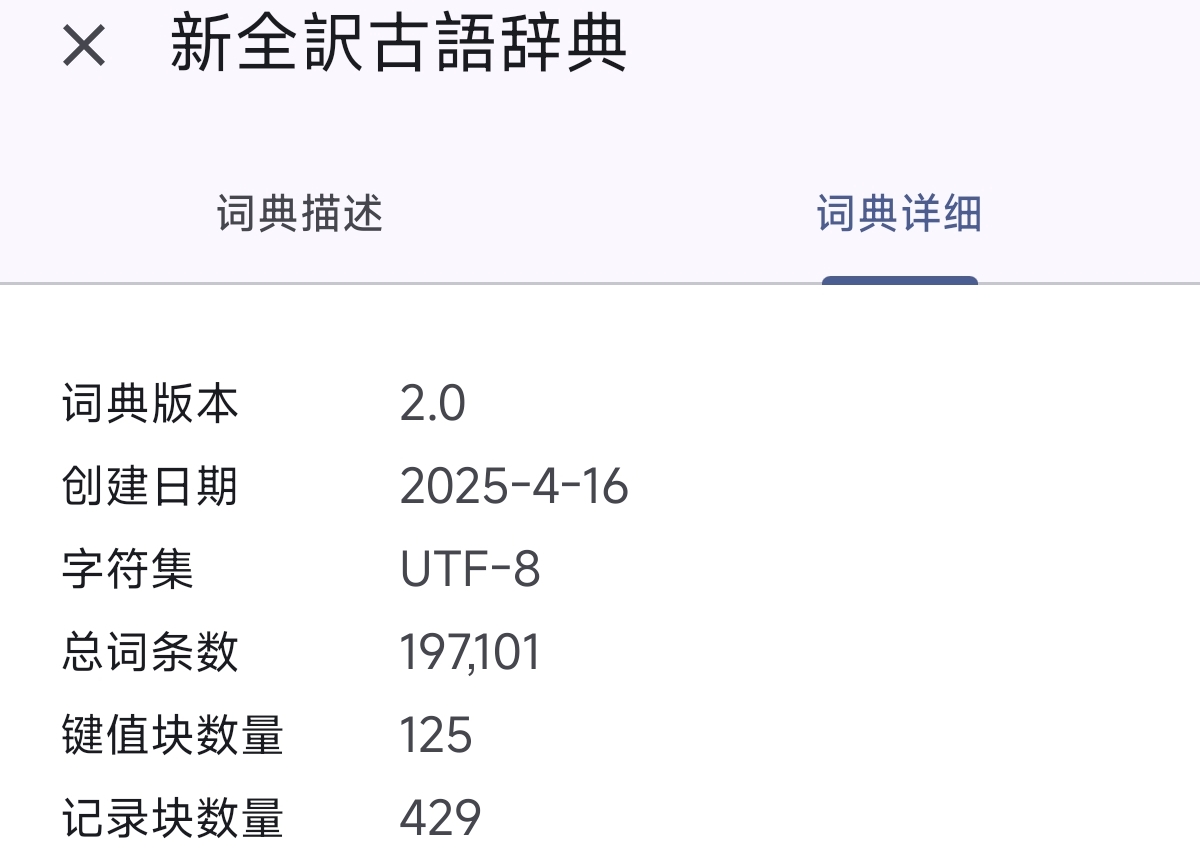
我制作的总词条数如下:
中文版本我是制作双语版,给你参考
啊,之前确实没注意这种细节,我是花半小时快速制作的,直接把【】里的词条简单分割了。不过词条只有三千多条,你索引多了这么多是把解说里面引用的内容都加进去了吗。
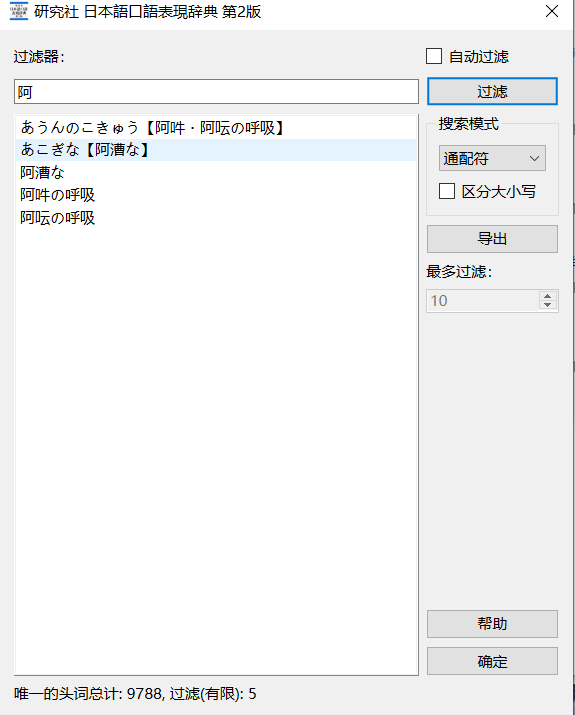
我的方法比较笨,比如词条 かにホホ【Aい・B】,那以下这些输入都会查询到
かにホホ, かにほほ, カニホホ, Aい, Aイ, B
还有表记的内容我也顺便添加了搜索
哦,是加了片假名索引啊,感觉这种转换其实应该是词典软件做的,是mdx设计缺陷问题没有对日语标准化。
我都忘了优化词头这一茬。
这个・的拆分感觉脚本做不到,可能是句首、句中、句尾的成分并列,不固定,至少不分析句子语义结构的话是做不到的。
所以我之前全是一个一个手动拆分的,附上文件,楼主应该用得上。还加上了句子拆解后的词来优化搜索,主要是不常见的词(都是个人判断,不完全严谨 )。
(以肩に伸し掛かる为例,肩和伸し掛る都作为优化词条。使得查肩和伸し掛る的时候,口语词典能出来肩に伸し掛かる。个人觉得这是合理的。)
平假名大概率是不会重的。
(不知道原数据是否自带这个表)
more_keys.txt (69.5 KB)
amob
9
好像各位制作logovista词典的经验不足,根本不用自己分拆的,直接表里取就行。。。至于分拆质量就全部交给官方了。不满意的话还得自己拆。

当然真用了的话,词典软件搜索起来搜索栏条目以及重复太多,观感不太好,我自己做个词典都有快二十万条索引。。
唉,logovista数据不会用。之前是用PDF提取出的mdx基础上改的。
amob
11
会用也不行,Logovista第一版还是类epwing的旧格式,官方没给索引表(或者说epwing这种索引不太好利用)。拿pdf已经转换的mdx做没差别。
哦,这个数据我之前没处理,不过他的索引全转成片假名了,要用还要转回来,也挺麻烦的。第一版的数据我还没研究,文件头我看和epwing不同还是native库处理的就没管。
已经修复了,是对logovista的索引还原成原始形式处理的,没有额外加片假名索引,因为感觉这是标准化问题,不应该在词典加一堆索引,比较乱。
发现了个小问题。包含多个会話例的词条,不同的会話例没有被分割。
第一版,带有会話例1、会話例2的区分
第二版:
查了下原数据就把这两个会话合并了,不是转换引起的问题,要想分开只能手动处理了。
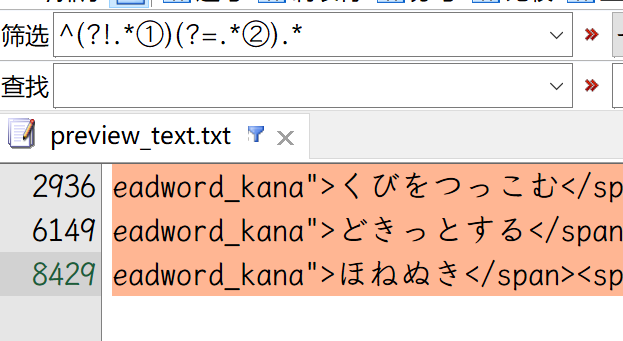
对了,忘了说,书本(不管一版或二版),logovista(不管一版或二版),都有一处共同的小错误约有三四处的样子,例如词条 “くびをつっこむ 【首を突っ込む】” 的例句多了一个 “②”。这个错误反而在中文版中有几处有修改掉!!
这正则好麻烦,我是用
^[^①]+?②
还有书本一二版和logovista有些显示字体不一样,我是按照书本为依据,我记得有以下这些
掻->搔, 填->塡, 噛->嚙, 呑->吞, 嘘->噓, 剥->剝, 掴->摑, 頬->頰
书上不知道什么原因用的旧字体,同系列其他书也有这个情况,我遇到这种情况一般统一改成新字体。